Now structured logging built-in support for Elastic Common Schema (ecs), Graylog Extended Log Format (gelf) and Logstash (logstash), any plan to support CSV format? Now DuckDB, DataFusion, ClickHouse-local all support to query CSV directly with SQL, and CSV friendly to AWK/DataFrame too.
Comment From: mhalbritter
That's quite an interesting idea, I can see that this is useful. We have to do some research on existing CSV formats, i guess.
Comment From: linux-china
That's quite an interesting idea, I can see that this is useful. We have to do some research on existing CSV formats, i guess.
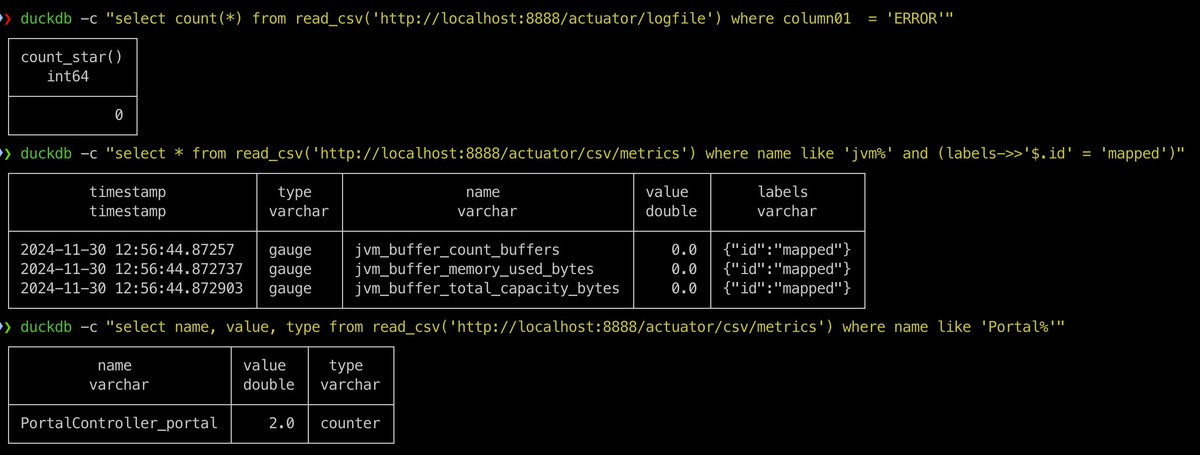
My examples now:
$ duckdb -c "select count(*) from read_csv('http://localhost:8888/actuator/logfile') where column01 = 'ERROR'"
$ duckdb -c "select * from read_csv('http://localhost:8888/actuator/csv/metrics') where name like 'jvm%'"
Of course, you can union logfiles/metrics from multi instances, and it's very convenient.
Comment From: ivamly
Hello, @mhalbritter! May I work on this issue? If so, do you have any suggestions or guidance on how to get started? Thank you!
Comment From: linux-china
Examples for logfile, metrics, env, beans with CSV support.
Comment From: mhalbritter
Hey @ivamly, thanks for the offer. For this issue, we'd like to spend some time on design work, so it's not open for contributions yet.
Comment From: wilkinsona
@linux-china are you aware of any standards or conventions for the column ordering, the contents and their format, and so on in the CSV data for logging?
Comment From: linux-china
Now I use @JsonPropertyOrder to convert POJO to CSV as following:
@JsonPropertyOrder({"id", "nick", "email", "tags"})
public class User {
private Integer id;
private String nick;
private String email;
private String tags;
For column type or format, and I think CSV Schema Language 1.2 some complicated.
DuckDB use struct style: column1: type, colum2: type , and example as following:
SELECT *
FROM read_csv('flights.csv',
delim = '|',
header = true,
columns = {
'FlightDate': 'DATE',
'UniqueCarrier': 'VARCHAR',
'OriginCityName': 'VARCHAR',
'DestCityName': 'VARCHAR'
});
For column ordering and format, and I think the following is fine.
logging.structured.csv.format=column1:type, column2:type, mdc_user, key_code, message
type name is not required if it's text, for most time, and type is not necessary at all. mdc_ prefix is for MDC, and key_ prefix is for KeyValuePair from slf4j 1.3.
Another question is about CSV headers. For new created logfile or rotatated logfile, the headers should be added as first line.
Comment From: philwebb
Another question is about CSV headers. For new created logfile or rotatated logfile, the headers should be added as first line.
This will be quite tricky for us as currently StructuredLogFormatter has no knowledge of the way logs are being written. It will also be difficult if an app is restarted and appends to an existing log.
Comment From: linux-china
@philwebb CSV headers is not a must, and most developers will use schema by themselves, supplied by schema registry or input by themselves.