Affects: \
affected versions:all
Background
We have a application where the jvm meta space periodically fluctuates significantly, as shown in the following screenshot.
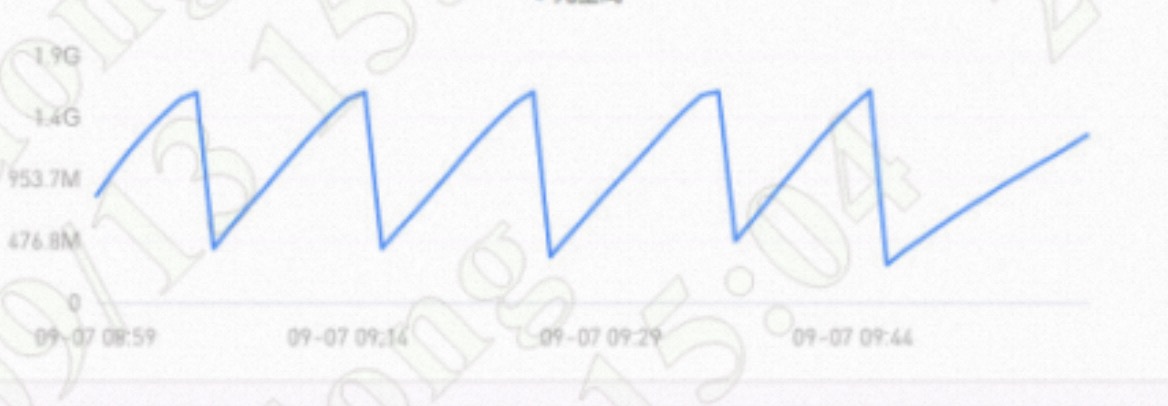
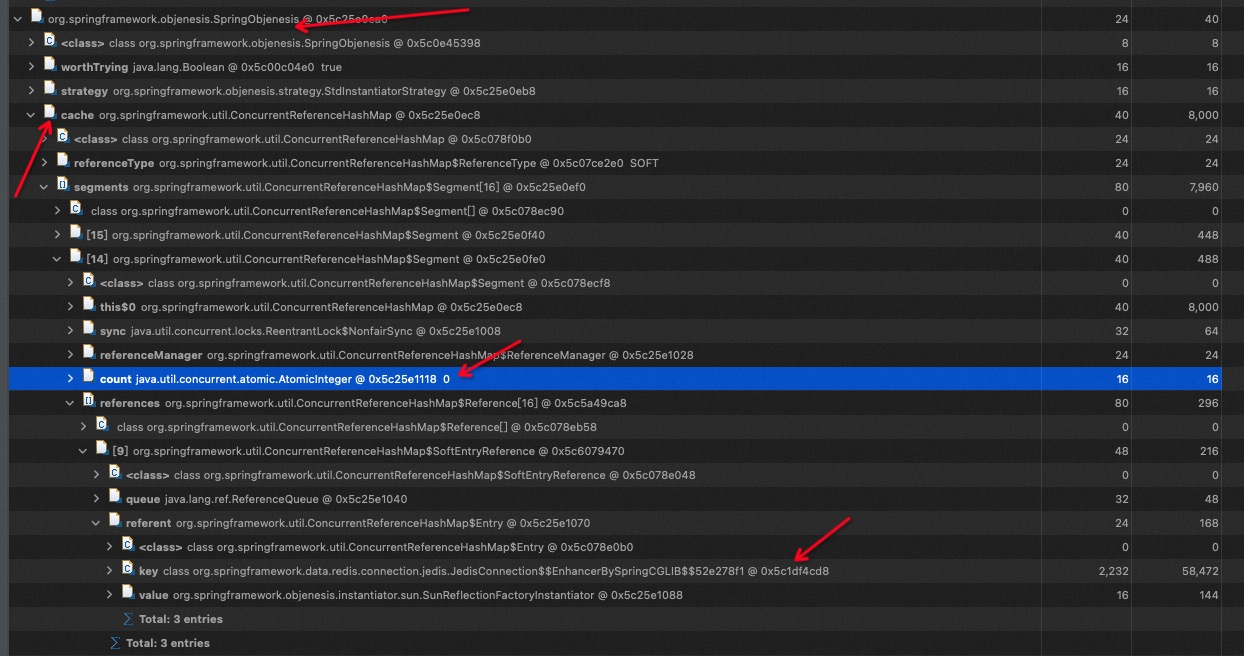
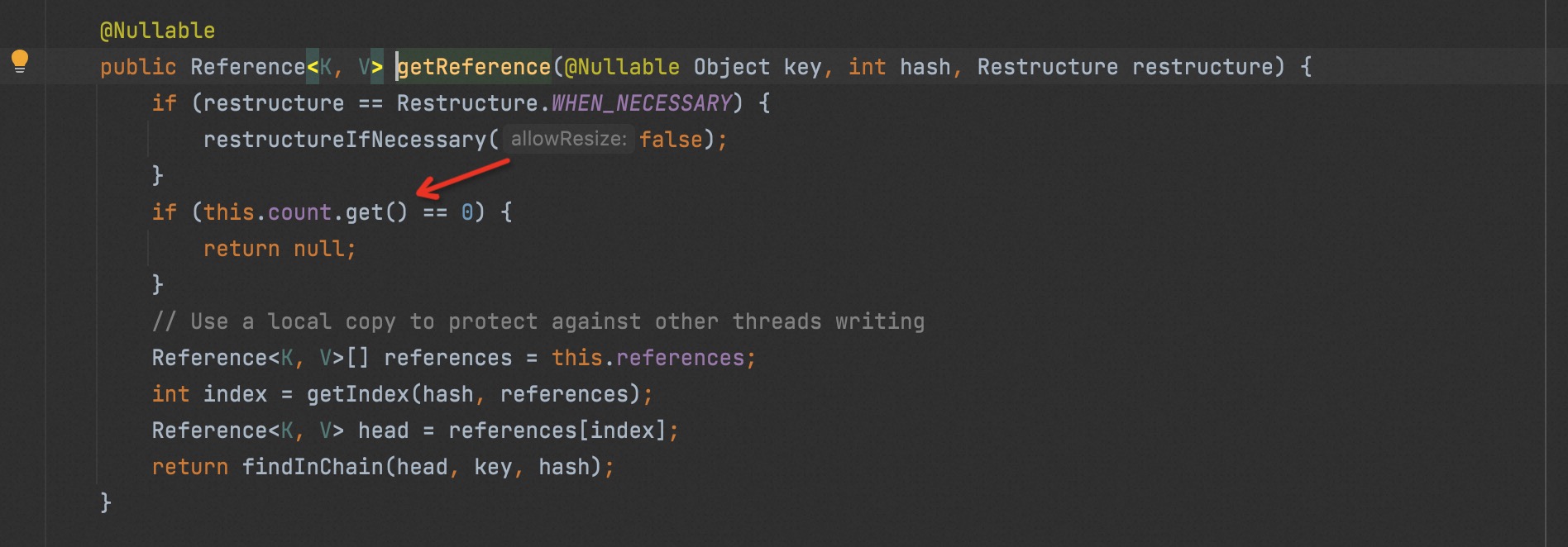
Why does the ConcurrentReferenceHashMap.Segment has this problem?
We have tried to reproduce the problem, as shown in the demo code
conrefmap-demo.tgz,
and it seems that the remove operation caused the problem, but there is no remove operation in the phenomenon described earlier,the org.springframework.objenesis.SpringObjenesis just invoke get and putIfAbsent.
We cannot confirm the reason for the count being less than the actual number of entries, but we speculate on the following possibilities:
- First: in the restructure method, copy the reference, generate multiple references for same key, and some old references also have the opportunity to enter the ReferenceQueue(for example getReference has the old Reference,so may cause old Reference have the opportunity to enter the ReferenceQueue).
- Second: when resizing, both arrays reference new and old reference, and the old references array are replaced only after the restructuring is completed. The old reference may be added to the ReferenceQueue by the garbage collector, and later, new reference are also added to the ReferenceQueue.
- Third: mysterious multi-threading issues.
Regardless of the reason, we only need to ensure that the count is equal to the actual number of entries containing references to fix the problem.
Comment From: bclozel
Thanks @nihongye for the detailed report. I think I understand what's going on here, although writing a test for this would be really challenging.
I think the issue is in the org.springframework.util.ConcurrentReferenceHashMap.Segment#restructure method. When conditions are met, this method will be called to purge elements from the segment that have been added to the queue by the garbage collector. Indeed, we need to remove References from the segments that no longer hold a valid entry.
Example
Let's use an example where a given Segment holds 10 Reference instances "element01"..."element10".
Now consider that 3 elements have been queued for removal by the GC. The restructure() method collects them first:
https://github.com/spring-projects/spring-framework/blob/1e7e532ed6bd8ebece49819554f7627e707e290f/spring-core/src/main/java/org/springframework/util/ConcurrentReferenceHashMap.java#L585-L592
Then it predicts the element count in the segment once the restructure operation is done:
https://github.com/spring-projects/spring-framework/blob/1e7e532ed6bd8ebece49819554f7627e707e290f/spring-core/src/main/java/org/springframework/util/ConcurrentReferenceHashMap.java#L593
Later, we effectively restructure entries and only add them if they're not in the toPurge set and the referenced entry is not null. At this point we can effectively remove more than 3 elements from the Segment, but the counter will decrease by 3.
https://github.com/spring-projects/spring-framework/blob/1e7e532ed6bd8ebece49819554f7627e707e290f/spring-core/src/main/java/org/springframework/util/ConcurrentReferenceHashMap.java#L610-L626
I think the key issue is this: while the segment itself is locked, the GC can still collect references and make entries as null. It could be that new elements were marked as nulls and will be removed during the restructure operation. This means that the count can be higher than the actual number of elements.
From there, other inconsistencies can happen, as the GC'd elements are guaranteed to be queued and will be considered in a later restructure() call. The count should be eventually consistent, but as you have seen several operations are skipped if the current count is 0 (including removals). I think the combination of the two can make the count invalid, at least temporarily. I haven't figured out an exact scenario but I think this could explain it.
Possible fix
To fix this inconsistency, we can:
1. not use the toPurge size to recalculate the count, but the actual count of removed entries. This is still a bit inconsistent, as we're removing more entries that we initially polled from the queue and the size calculations are somewhat wrong.
2. only remove the entries that are listed in the toPurge Set and possibly leave null entries in the Segment. They will be later removed during a later restructure() call. I have benchmarked this solution and results are similar.
I am tempted to apply the second solution to the 6.0.x and 6.1.x branches, given we receive enough feedback about this change. At this point, a 5.3.x backport is unlikely as this is the first report for such an issue.
@nihongye would you consider testing a 6.0.14-SNAPSHOT version with your production scenario (so, not using the repro project) and report back with the results? The release is scheduled on November 15th at the moment.
Comment From: nihongye
@bclozel Regarding "the count can be higher than the actual number of elements, The count should be eventually consistent", I think we should be consistent. This is the inevitable result of ConcurrentReferenceHashMap relying on Reference, and it is acceptable.
As for the reason why count is smaller than the actual number of elements, I would like to do another logical reasoning, which will help us understand this problem:
Only the new key causes count+1, and only the restructure process gets the Reference from the ReferenceQueue, causing the number to decrease; so we can infer that these Purged References contain at least one pair pointing to the same key.
Regarding the fix
"we only need to ensure that the count is greater than the actual number,The count should be eventually consistent". In my original PullRequest, this can be guaranteed.
For test
This problem occurred in one of our customer's production applications. It happened very accidentally. Already suggested to remove the dynamic use of ProxyFactory, so new fixes cannot be retested on previous scenarios application.
Comment From: bclozel
Thanks for the update @nihongye
Only the new key causes count+1, and only the restructure process gets the Reference from the ReferenceQueue, causing the number to decrease; so we can infer that these Purged References contain at least one pair pointing to the same key.
I'm not sure I understand . How would that relate to the use case for your customer? This would only reproduce this if the use code is calling remove (which is not the case apparently?). Also, this would mean that we can get duplicate values for the same key in the reference list, but I don't see how this can happen given that we lock the entire segment:
https://github.com/spring-projects/spring-framework/blob/1e7e532ed6bd8ebece49819554f7627e707e290f/spring-core/src/main/java/org/springframework/util/ConcurrentReferenceHashMap.java#L524-L540
"we only need to ensure that the count is greater than the actual number,The count should be eventually consistent". In my original PullRequest, this can be guaranteed.
I have looked at your PR and unfortunately it suffers from two issues:
- this adds another complete iteration over all values, which decreases performance
- because it happens before the actual restructure operations, there are still chances that the GC collects entries and we remove more than expected. The window of opportunity for this is reduced but it's still possible
This problem occurred in one of our customer's production applications. It happened very accidentally. Already suggested to remove the dynamic use of ProxyFactory, so new fixes cannot be retested on previous scenarios application.
Since there is no way for us to experiment with the fix, I'll schedule this for 6.1 and we might consider backports in the future if we get new reports for this.
Comment From: nihongye
I'm not sure I understand . How would that relate to the use case for your customer? This would only reproduce this if the use code is calling remove (which is not the case apparently?). Also, this would mean that we can get duplicate values for the same key in the reference list, but I don't see how this can happen given that we lock the entire segment:
https://github.com/spring-projects/spring-framework/blob/1e7e532ed6bd8ebece49819554f7627e707e290f/spring-core/src/main/java/org/springframework/util/ConcurrentReferenceHashMap.java#L609-L626
restructured[index] = this.referenceManager.createReference(
entry, ref.getHash(), restructured[index]);
In the restructure method,The above line of code will copy a reference, so there may be multiple References for the same key at the same time.old reference have a chance to be GC while they can be referenced
this adds another complete iteration over all values, which decreases performance
Yes, or consider removing the newly added iteration code and just calculating the number in the existing iteration, but this is a bit problematic. The opportunity to resize the array is moved to the next restructure execution.
because it happens before the actual restructure operations, there are still chances that the GC collects entries and we remove more than expected. The window of opportunity for this is reduced but it's still possible
This will only cause the count to be larger than the actual number of elements, but this is not important because This is the inevitable result of ConcurrentReferenceHashMap relying on Reference.
Comment From: bclozel
In the restructure method,The above line of code will copy a reference, so there may be multiple References for the same key at the same time. old reference have a chance to be GC while they can be referenced
Sorry to drag this conversation, but I'd like to fully understand here. I agree that in this case we might be copying a null entry to the restructured segment because it's been GC'd in the meantime. But I don't see how we could be in a situation where we have two references for the same key. All put/replace operations are locking the segment, so we cannot add a new entry to an existing key without locking the segment first.
If you can show a scenario where we would get many values for a single key, I would consider that a bug that should be backported.
Comment From: nihongye
https://github.com/spring-projects/spring-framework/blob/1e7e532ed6bd8ebece49819554f7627e707e290f/spring-core/src/main/java/org/springframework/util/ConcurrentReferenceHashMap.java#L617-L622
In the above code, Entry is copied, so at this time there are two References referencing the same Entry. There are two possibilities: - Situation 1: In the scenario of resizing the references array, the old array still references the old Reference, and the new array references the new Reference. Both are reachable references from the GC Root, so the old one have a very short time window to be GCed and push to ReferenceQueue; - Situation 2: During restructure, another thread executes map.get, which may reference the old Reference, so the old Reference is also reachable from the GC Root, so it has a chance to be GCed. But I can't demo it, or my guess is wrong...
I have done a demo like this to verify the above guess. After creatingReference, put the Reference into a Map for tracking (making the Reference reachable from the GC ROOT). Then simple get and put operations can reproduce this problem.
Comment From: bclozel
I see, with scenario 1 we could indeed get references to purge that are already gone and we could decrease the count without removing an entry effectively. I'll revisit my fix.
Maybe the goal here is to get an estimate of the restructured array size we'll need, then only count the element we actually keep in it while we're adding them.
Comment From: nihongye
@bclozel This problem is too difficult. We have also spent a lot of time analyzing it. Thank you for handling this problem.