On Spring 6.1.5 when content type is set as application/x-www-form-urlencoded the request gets encoded value. However it also alters the request String to remove the number of characters added as part of the encoding.
Header has: Content-Type - application/x-www-form-urlencoded
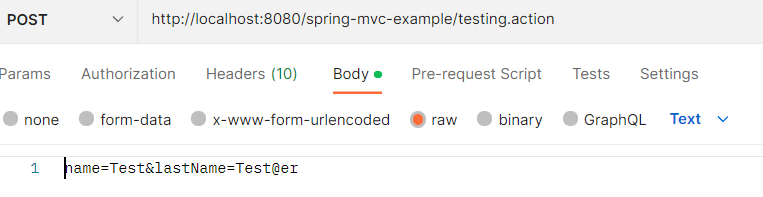
Request Body has String: name=Test&lastName=Test@er
In Spring controller the String appearing is: name=Test&lastName=Test%40
While it encodes, the last 2 characters have been removed by Spring. This issue exists in 6.1.x. Request any help on the same.
Comment From: snicoll
@ramyav16 please share a small sample we can run to reproduce the problem. You can attach a zip to this issue or push the code to a GitHub repository.
Comment From: ramyav16
Thanks for the response. Below is one sample. Tried on Java 17.
@RequestMapping(value = "/testing.action", method = RequestMethod.POST)
public @ResponseBody
void sampleCode(
@RequestBody String sampleInput, ModelMap model,
HttpServletRequest request, HttpServletResponse response) {
System.out.println("This is the req body: " + sampleInput);
}
Comment From: snicoll
@ramyav16 thanks, but a code snippet is not a sample. Please attach a sample as requested and how to trigger the query that leads to the problem you've described.
Comment From: ramyav16
@snicoll Thanks. I have added a sample - https://github.com/ramyav16/spring-mvc-example Works on Java 17, Tomcat 10.1
Same can be tested via any tool such as Postman.
Header

Body
Comment From: rstoyanchev
A different case was reported in #31327 with the same root cause, which is related to the StringHttpMessageConverter optimization in #30942 and ServletServerHttpRequest#getBody reconstructing the body from request params to ensure consistent form data access.
In #31327, both a request body and a query were present, and that made the reconstructed body larger than the content-length. For that case, we undid the optimization in 6.0.x, and added a check to avoid reconstructing the body if there is a query string.
Here the reconstructed body is larger because the request body has a character that wasn't encoded, but is after the body is reconstructed and that leads to a mismatch between content and content-length.
Comment From: ramyav16
@rstoyanchev thanks for the details. Would this be fixed in version 6.1.6?
Comment From: rstoyanchev
If the client was encoding the body, as it should, it wouldn't cause this issue. That said, the goal here is to find a fix although I'm not sure yet what it will be.