Bug description
(Note: this is all a local test for now, but, the actual models being called are "production-ready", so to say so its a representative example)
When calling the below code from an API client, like Postman:
@GetMapping(value = "/streamed-completions-get", produces = TEXT_EVENT_STREAM_VALUE)
public ResponseEntity<Flux<ChatResponse>> liveCompletionsStreamed(HttpServletResponse httpServletResponse) {
httpServletResponse.setHeader("Content-Security-Policy",
"default-src 'self'; connect-src 'self' http://localhost:9841");
httpServletResponse.setStatus(HttpServletResponse.SC_OK);
httpServletResponse.setContentType(TEXT_EVENT_STREAM_VALUE);
return ResponseEntity.ok(((StreamingModel)chatModel).stream(new Prompt("Explain me how to configure the server port in springboot with examples")));
}
the expected behavior would be that the response is always streamed, meaning that chunks are received over time instead of all at once.
This works as expected when connecting to Anthropic models:
spring:
ai:
bedrock:
anthropic3:
chat:
enabled: true
model: anthropic.claude-3-haiku-20240307-v1:0
See below the screenshot for evidence that the response is streamed back:
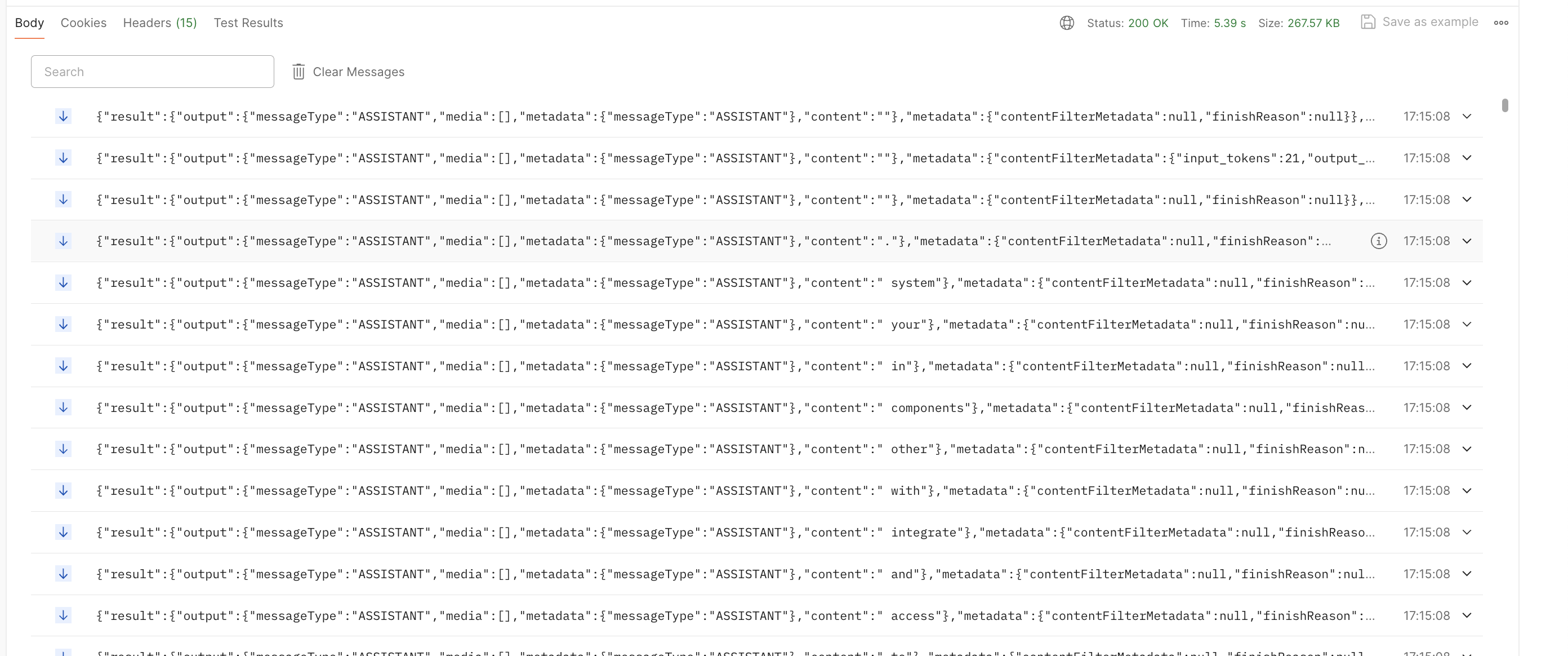
However, then, I simply stop the app, "swap" the credentials to use the Azure OpenAI Chat Client and the answer is instead, all "streamed at once":

What I expected is that the answer would also be streamed just like it is when using Anthropic models.
Environment
Using: Spring AI: 1.0.0-SNAPSHOT (bleeding edge release, received yesterday's breaking changes) SpringBoot: 3.2.4 Java: 21
Steps to reproduce A streaming call with a ChatClient configured for Bedrock Anthropic3 models will stream. The exact same code for an Azure OpenAI client will not stream in chunks, but all at once.
Expected behavior Essentially, by only tweaking an environment variable (think model being used for example) that the streaming mechanics works out of the box as expected without any need for "custom code".
Minimal Complete Reproducible example Example should be easy to reproduce, but, for further clarity, here are the beans Im using in a configuration class:
@Configuration
@Getter
@Setter
@EnableAutoConfiguration(exclude = {AzureOpenAiAutoConfiguration.class, BedrockAnthropic3ChatAutoConfiguration.class})
public class LargeLangModelConfiguration {
private static final float TEMPERATURE = 0.0f;
@Value(value = "${spring.ai.azure.openai.endpoint:#{null}}")
private String endpoint;
@Value(value = "${spring.ai.azure.openai.api-key:#{null}}")
private String apiKey;
@Value(value = "${spring.ai.azure.openai.chat.options.deployment-name:#{null}}")
private String azureModel;
@Value(value = "${spring.ai.bedrock.anthropic3.chat.model:#{null}}")
private String model;
@Value(value = "${spring.ai.bedrock.region}")
private String region;
@Bean
@Primary
@Qualifier("chatClientGpt")
@ConditionalOnProperty("spring.ai.azure.openai.chat.options.deployment-name")
public ChatModel azureOpenAiChatClientGpt() {
return getAzureOpenAIModel(getAzureModel());
}
@Bean
@Primary
@Qualifier("chatClientAnthropic")
@ConditionalOnProperty("spring.ai.bedrock.anthropic3.chat.model")
public ChatModel chatClientAnthropic() {
return getAnthropicModel(getModel());
}
private ChatModel getAnthropicModel(String model) {
return new BedrockAnthropic3ChatModel(new Anthropic3ChatBedrockApi(
model,
DefaultCredentialsProvider.create(),
getRegion(),
new ObjectMapper(),
Duration.ofMillis(20000)),
Anthropic3ChatOptions.builder()
.withTemperature(TEMPERATURE)
.withMaxTokens(1000)
.withAnthropicVersion(DEFAULT_ANTHROPIC_VERSION)
.build());
}
private ChatModel getAzureOpenAIModel(String model) {
return new AzureOpenAiChatModel(
new OpenAIClientBuilder().endpoint(endpoint).credential(new KeyCredential(apiKey)).buildClient()
, AzureOpenAiChatOptions.builder()
.withTemperature(TEMPERATURE)
.withDeploymentName(model)
.build());
}
}
I wonder if this is a bug in the stream library call for the underlying Azure OpenAI client or a mistake on the configuration on my side.
Any pointers appreciated!
Comment From: bruno-oliveira
According to the documentation the low-level API offers support for configuring streaming but, I suppose that something needs to be adapted to make it such that the detection of the call being from a streaming client needs no custom code or changes anywhere when simply calling it from the (StreamingModel) interface, that, obviously selects the correct underlying implementation?
Comment From: bruno-oliveira
It seems as if something makes this call to be blocking and the chunks aren't sent properly but instead the whole answer comes at once:
public Flux<ChatResponse> stream(Prompt prompt) {
ChatCompletionsOptions options = this.toAzureChatCompletionsOptions(prompt);
options.setStream(true);
IterableStream<ChatCompletions> chatCompletionsStream = this.openAIClient.getChatCompletionsStream(options.getModel(), options);
Flux<ChatCompletions> chatCompletionsFlux = Flux.fromIterable(chatCompletionsStream);
AtomicBoolean isFunctionCall = new AtomicBoolean(false);
Flux<ChatCompletions> accessibleChatCompletionsFlux = chatCompletionsFlux.skip(1L).map((chatCompletions) -> {
List<ChatCompletionsToolCall> toolCalls = ((ChatChoice)chatCompletions.getChoices().get(0)).getDelta().getToolCalls();
isFunctionCall.set(toolCalls != null && !toolCalls.isEmpty());
return chatCompletions;
}).windowUntil((chatCompletions) -> {
if (isFunctionCall.get() && ((ChatChoice)chatCompletions.getChoices().get(0)).getFinishReason() == CompletionsFinishReason.TOOL_CALLS) {
isFunctionCall.set(false);
return true;
} else {
return false;
}
}, false).concatMapIterable((window) -> {
Mono<ChatCompletions> reduce = window.reduce(MergeUtils.emptyChatCompletions(), MergeUtils::mergeChatCompletions);
return List.of(reduce);
}).flatMap((mono) -> {
return mono;
});
return accessibleChatCompletionsFlux.switchMap((accessibleChatCompletions) -> {
return this.handleFunctionCallOrReturnStream(options, Flux.just(accessibleChatCompletions));
}).flatMapIterable(ChatCompletions::getChoices).map((choice) -> {
String content = ((ChatResponseMessage)Optional.ofNullable(choice.getMessage()).orElse(choice.getDelta())).getContent();
Generation generation = (new Generation(content)).withGenerationMetadata(this.generateChoiceMetadata(choice));
return new ChatResponse(List.of(generation));
});
}
```
This is the method call inside the class: `AzureOpenAiChatModel` decompiled via IntelliJ.
I am not sure how to fix the issue but I suspect that something leads to the behaviour that this call to the return:
```
return accessibleChatCompletionsFlux.switchMap((accessibleChatCompletions) -> {
return this.handleFunctionCallOrReturnStream(options, Flux.just(accessibleChatCompletions));
}).flatMapIterable(ChatCompletions::getChoices).map((choice) -> {
String content = ((ChatResponseMessage)Optional.ofNullable(choice.getMessage()).orElse(choice.getDelta())).getContent();
Generation generation = (new Generation(content)).withGenerationMetadata(this.generateChoiceMetadata(choice));
return new ChatResponse(List.of(generation));
});
```
is a blocking one.
Simply calling the model with the stream method and putting a breakpoint in here is enough to observe this behavior.
**Comment From: bruno-oliveira**
Note that when I go deep into the BedrockAnthropic3Client for the streaming mode:
public Flux
String content = response.type() == StreamingType.CONTENT_BLOCK_DELTA ? response.delta().text() : "";
Generation generation = new Generation(content);
if (response.type() == StreamingType.MESSAGE_DELTA) {
generation = generation.withGenerationMetadata(ChatGenerationMetadata.from(response.delta().stopReason(), new Anthropic3ChatBedrockApi.AnthropicUsage((Integer)inputTokens.get(), response.usage().outputTokens())));
}
return new ChatResponse(List.of(generation));
});
}
```
And I put a breakpoint in the last return and run the app in debug mode, I observe the behavior I expect: the return being hit every time a new chunk comes back from the inference endpoint.
I'd expect a similar behavior for the AzureOpenAI method but something seems broken there? FYI @markpollack
Comment From: bruno-oliveira
I’ll see if I can clone the repo, run it locally somehow and if I can reproduce and subsequently fix the issue, I’ll open a PR! Thanks for the amazing work and project so far btw, super appreciated
Comment From: bruno-oliveira
The Azure method seems to stop the intermediate stream state as the chunks would arrive only if a tool call is happening and also skips the first element of the stream, these will be the details I’ll try to look into first!
Comment From: bruno-oliveira
Anyone up for reviewing this change? Thanks in advance 👌
Comment From: bruno-oliveira
This seems fixed in: https://github.com/spring-projects/spring-ai/commit/178a607cf6fc65e302b7420fe50cb8dff7e2df2d closing this one!!
Comment From: imGruuu
This seems fixed in: 178a607 closing this one!!
@bruno-oliveira Excuse me.I have tried in version 1.0.0-M1. It does not seem to be completely fixed, the problem still exists with the azureOpenai method, when the output is longer, or when calling the function.
Comment From: bruno-oliveira
I’ll have a try with M1 and see if it’s fixed! If not I'll reopen this
On Thu, 30 May 2024 at 09:41, imGruuu @.***> wrote:
This seems fixed in: 178a607 https://github.com/spring-projects/spring-ai/commit/178a607cf6fc65e302b7420fe50cb8dff7e2df2d closing this one!!
@bruno-oliveira https://github.com/bruno-oliveira Excuse me.I have tried in version 1.0.0-M1. It does not seem to be completely fixed, the problem still exists with the azureOpenai method, when the output is longer, or when calling the function.
— Reply to this email directly, view it on GitHub https://github.com/spring-projects/spring-ai/issues/764#issuecomment-2138879955, or unsubscribe https://github.com/notifications/unsubscribe-auth/ABEA53EWYZ5A44SKRGOT2U3ZE3J3PAVCNFSM6AAAAABIHZCEGOVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDCMZYHA3TSOJVGU . You are receiving this because you were mentioned.Message ID: @.***>
Comment From: bruno-oliveira
@imGruuu You're right, it's not yet working as expected. I've created a new MR: https://github.com/spring-projects/spring-ai/pull/796
Hopefully this will help, I will try to build the lib locally myself and use it from a "local maven repo" on my machine.