In the GenAI ecosystem, many solutions have been introduced that are centered around the concepts of observability and evaluation of Large Language Models. Unlike more traditional applications, observability becomes even more a concern to be addressed already as part of the local development workflow, because it enables refining prompts and tuning the model integration to fit the case at hand. As such, I think it would be really great to start introducing some basic observability features in Spring AI before cutting the 1.0.0 GA release.
Background
From a Spring AI perspective, I believe it's useful to categorise the available GenAI observability products as follows:
- Products relying on OpenTelemetry to standardize the instrumentation, collection, and visualisation of telemetry data (traces, metrics, logs, and more). Examples: OpenLit, OpenLLMetry/TraceLoop, Arize Phoenix, LangTrace.
- Products relying on proprietary/custom strategies for instrumentation, collection, and visualisation of telemetry data. Examples: LangSmith, LangFuse, Lunary.
Considering the consolidation around OpenTelemetry (the industry standard for observability) and the many integration possibilities with the rest of the ecosystem, I would recommend drawing inspiration from the first group of products to understand better the types of features needed for observability, with a possible goal to integrate them with Spring AI at some point. There is also work in progress to agree on semantic conventions for GenAI applications in the OpenTelemetry project. Those conventions are still under active development, but they are being already experimentally adopted in products like OpenLit and OpenLLMetry/TraceLoop. A similar attempt of agreeing on standard naming conventions is also brought forward within the OpenInference group.
Context
What does it mean observing an LLM-powered applications? There are many use cases, going from more general observability to specific evaluation scenarios. For starters, I want to focus on the fundamentals, as also highlighted in this blog post from OpenTelemetry. In particular, what kind of telemetry do we need?
LLM Request
- Provider (mistral)
- Operation (chat.completion)
- Model (open-mistral-7b)
- Temperature (0.7)
- Top P (0)
- Prompt content (sensitive data, so to be handled optionally and separately)
LLM Response
- Model (open-mistral-7b-0118999)
- Finish reason (stop)
- Used prompt tokens (420)
- Used completion tokens (42)
- Completion content (sensitive data, so to be handled optionally and separately)
Proposal
My suggestion for addressing observability in Spring AI is to split the problems into smaller tasks.
- Instrumenting the code in Spring AI to allow collecting telemetry data for model integrations, vector stores, and higher-level AI workflows.
- Configuring the export of telemetry data to comply with specific conventions and allow integrations with different platforms.
In particular, I propose to start focusing on the models to refine and validate the solution, before extending the scope to vector stores and higher-level AI workflows.
Micrometer allows to instrument the code once and export telemetry both via OpenZipkin and OpenTelemetry, and offers good APIs to plug in different semantic conventions to customise the exported telemetry. So it aligns with how the rest of the Spring ecosystem is instrumented, but it will also allow to integrate with all those LLM Observability solutions that follow the OpenTelemetry standard. Furthermore, interested vendors can always implement their custom exporters and hook them into the Micrometer-based instrumentations, even though they rely on proprietary data formats and protocols. There is an opportunity here for enterprise solutions.
We can split this task further into two activities:
- Spring AI Observations: APIs and default implementations for modelling observations related to models and vector stores.
- Spring AI Instrumentation: using the foundation defined in the previous point, instrument the actual code to generate the observations based on Micrometer.
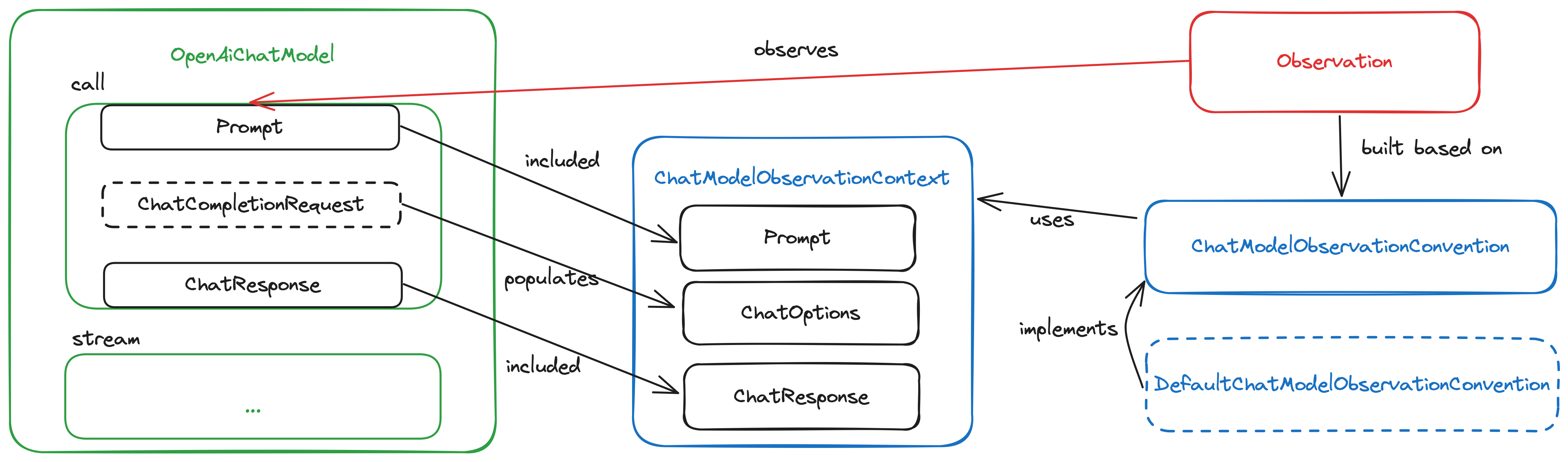
Spring AI Observations
First, I suggest to introduce an API for gathering the observation context for model integrations:
- The
ModelObservationContextextends fromAiObservationContextand will be the foundation of any machine learning model observation context. This is inspired by theRequestReplySenderContextused in Spring for observing HTTP interactions.
I'm focusing on models in this proposal, but observations for vector store would follow a similar path.
Then, I suggest introducing the following entities, as also shown in the diagram. For each model type:
- A
<Type>ModelObservationContextextendingModelObservationContextto hold all the data related to these model requests and responses that we are interested in possibly use in the telemetry data. The context is defined in terms of a request and a response, which in the case of Spring AI can be the specific implementations for the given model ofModelRequestandModelResponse. Additionally, we need to provide additional contextual data via aModelOptionsinstance. More details about this in the instrumentation section. - A default implementation of a
<Type>ModelObservationConventionthat will determine how to use the contextual data to build low cardinality and high cardinality key-value pairs, that will ultimately end up being exported as metrics and traces.
Based on the specific needs of a certain model, an additional implementation of an ObservationHandler can be defined to customise the way metrics and traces are produced.
There can also be implementations of ObservationFilter to optionally include prompt and completion content in the telemetry. This is where we can fulfil the feature request for logging prompts and completions, as I mentioned in https://github.com/spring-projects/spring-ai/issues/512#issuecomment-2185096414.
The default <Type>ModelObservationConvention implementation can be replaced with a different one to adopt different semantic conventions, for example to adopt the standard OpenTelemetry conventions or to integrate better with solutions like OpenLit or OpenLLMetry. I would keep that part out of scope since it's an area under active development and things will change very often. I imagine having an external library providing those experimental conventions (I'm actually drafting something in that direction).

Spring AI Instrumentation
After introducing all the necessary APIs for model-related Observations, we need to instrument each Model implementations in Spring AI.
There are 3 main alternative for where to apply the instrumentation. I'll use chat models and OpenAI as an example. Personally, I would go with option 2 because option 1 doesn't fulfil the requirements of LLM observability and evaluation scenarios (most contextual data is missing from the telemetry) whereas option 3 has a high cost in terms of implementation, maintenance, and efficiency.
Option 1: ChatModel interface
If we consider the call() method in the ChatModel interface, we could think of defining the instrumentation in a (newly-defined) abstract class or via AOP.
Pros:
- For each model type, the instrumentation is defined in one single place (
AbstractChatModel) so that all futureChatModelimplementations will be instrumented automatically and out-of-the-box. - The observation context can be based on the generic input and output objects as defined in the
call()method (PromptandChatResponse). - The chained model interactions happening during function calling are correctly observed once https://github.com/spring-projects/spring-ai/pull/1040 or a similar solution is delivered.
Cons:
- Most of the contextual data needed for the main LLM observability and evaluation purposes are not included in the telemetry data because not available by only looking at the
ChatModelinterface for thecall()method. The input object (Prompt) contains aChatOptionsobject used to pass some customizations for the chat request, but those are not the final options used in the request. As part of the eachChatModelimplementation, the inputChatOptionsobject is merged with the provider-specific default options. This point alone makes this solution not feasible.
Option 2: Provider-specific ChatModel implementation
If we consider the call() method in each ChatModel implementation, we could think of defining the instrumentation in each of them.
Pros:
- The observation context can be based on generic framework objects as processed in the
call()method (Prompt,ChatOptions, andChatResponse). - The observation context includes all the data needed for the main LLM observability and evaluation purposes, including the final options included in the request to the model service (model name, temperature, top p, top k, frequency penalty, and so on).
- The chained model interactions happening during function calling are correctly observed once https://github.com/spring-projects/spring-ai/pull/1040 or a similar solution is delivered.
Cons:
- The instrumentation cannot be applied via abstract class or AOP, but it needs to be included in each
ChatModelimplementation. Though, it's only a few lines of code, so I don't see this as a strong con.
This option is shown in the diagram. We populate a ChatModelObservationContext from the input and output of the call() method in OpenAiChatModel ( Prompt and ChatResponse), but also the OpenAI chat-specific options extracted from the internal ChatCompletionRequest object.
Option 3: Provider-specific Api implementation
We could go a level lower and instrument based on the provider-specific request and response objects in each ChatModel implementation (imagining to have a provider-specific method like doChatCompletion() which is currently implemented in the models that support functions).
Pros:
- The observation context includes all the data needed for the main LLM observability and evaluation purposes, including the final options included in the request to the model service (model name, temperature, top p, top k, frequency penalty, and so on).
- Since the instrumentation is applied very close to the provider API, every single model call is instrumented, including all the intermediate calls necessary in scenarios of function calling.
Cons:
- The instrumentation cannot be applied via abstract class or AOP, but it needs to be included in each
ChatModelimplementation. Though, it's only a few lines of code, so I don't see this as a strong con. - The observation context cannot be based on generic framework objects ( such as
Prompt,ChatOptions, andChatResponse). Instead, for each model implementation, we need to work with provider-specific objects. This increases a lot the initial implementation cost, but also the maintenance cost. It kind of defies all the benefits introduced by the nice abstractions in Spring AI. - Data from the provider-specific requests and responses end up being extracted twice. One time for the observation context and one time to wrap the information in the Spring AI abstractions returned by the
ChatModelinterface. Overall, the result is much more code and less efficient implementation.
Finally, we can introduce auto-configuration to pass an optional ObservationRegistry to OpenAiChatModel that will enable the instrumentation. And we can also define optional beans controlled via configuration properties, for example the ObservationFilters for including prompt and completion content into the telemetry.
Discussion
I'm looking forward to hearing from you with some feedback and thoughts regarding this proposal. In particular, @markpollack and @tzolov, what do you think? Also, the Micrometer team might have some inputs about this and perhaps suggestions on how to get a base foundation to be used across the Java ecosystem as well. @marcingrzejszczak
I have opened a WIP pull request to present a possible implementation of some of the ideas I shared above. For now, I focused mostly on traces and metrics for chat, embedding and image models (OpenAI as an example). If you'd like to give it a try, I prepared a simple app to manually verify the observations exported via OpenTelemetry.
I've been doing more experiments and you can see some of them in this other project, but it's very messy and outdated, so don't spend too much time on it :) There I tried the semantic convention customisation and integration with OpenLit and OpenLLMetry. I also started a discussion within the OpenLit project around some ideas that will make it more straightforward to have Spring AI integrated with that solution, all centered around the OpenTelemetry standardisation (https://github.com/openlit/openlit/issues/300 and https://github.com/openlit/openlit/issues/299).
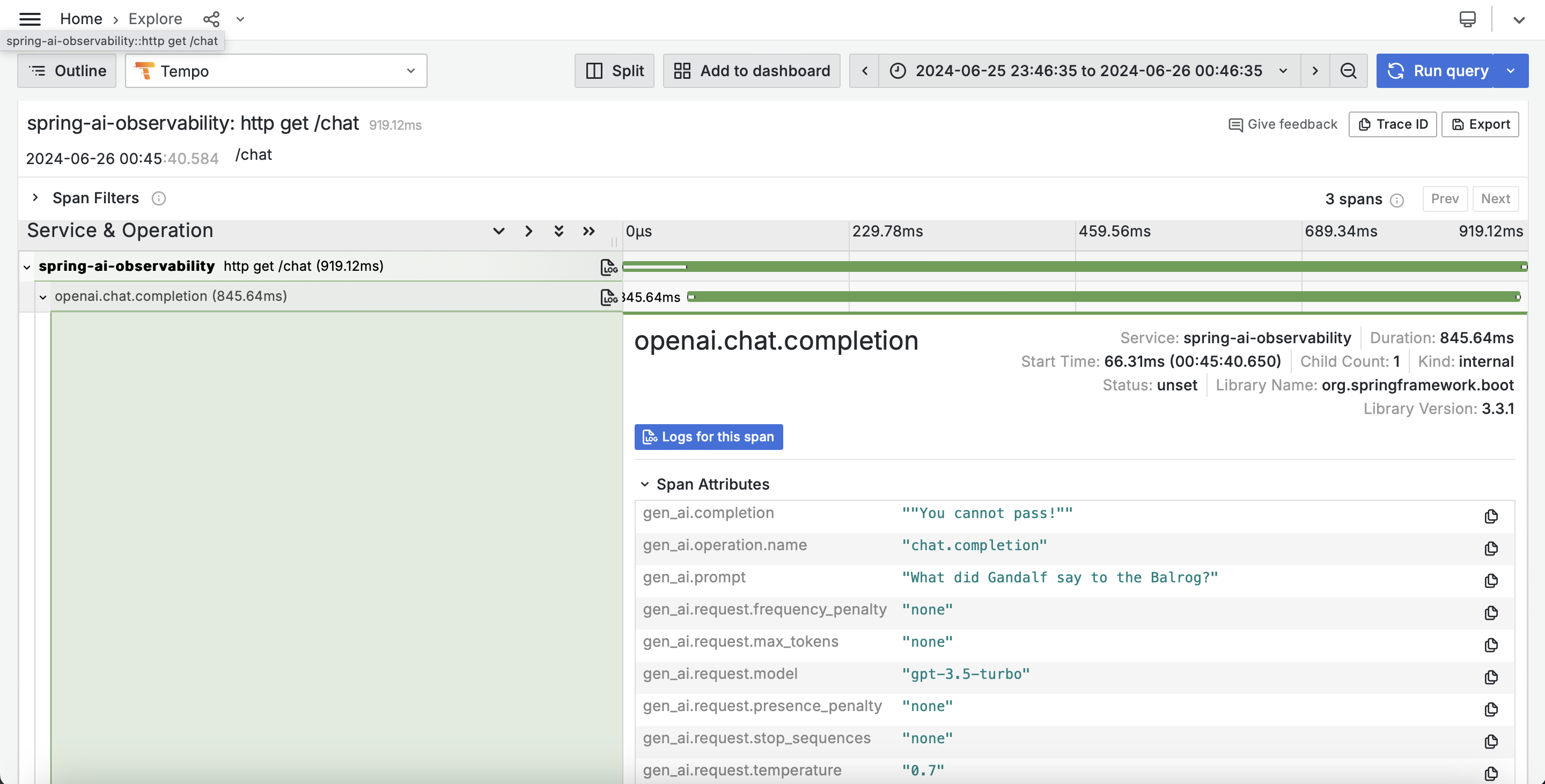
Example: Micrometer + OpenTelemetry + Grafana (default conventions)
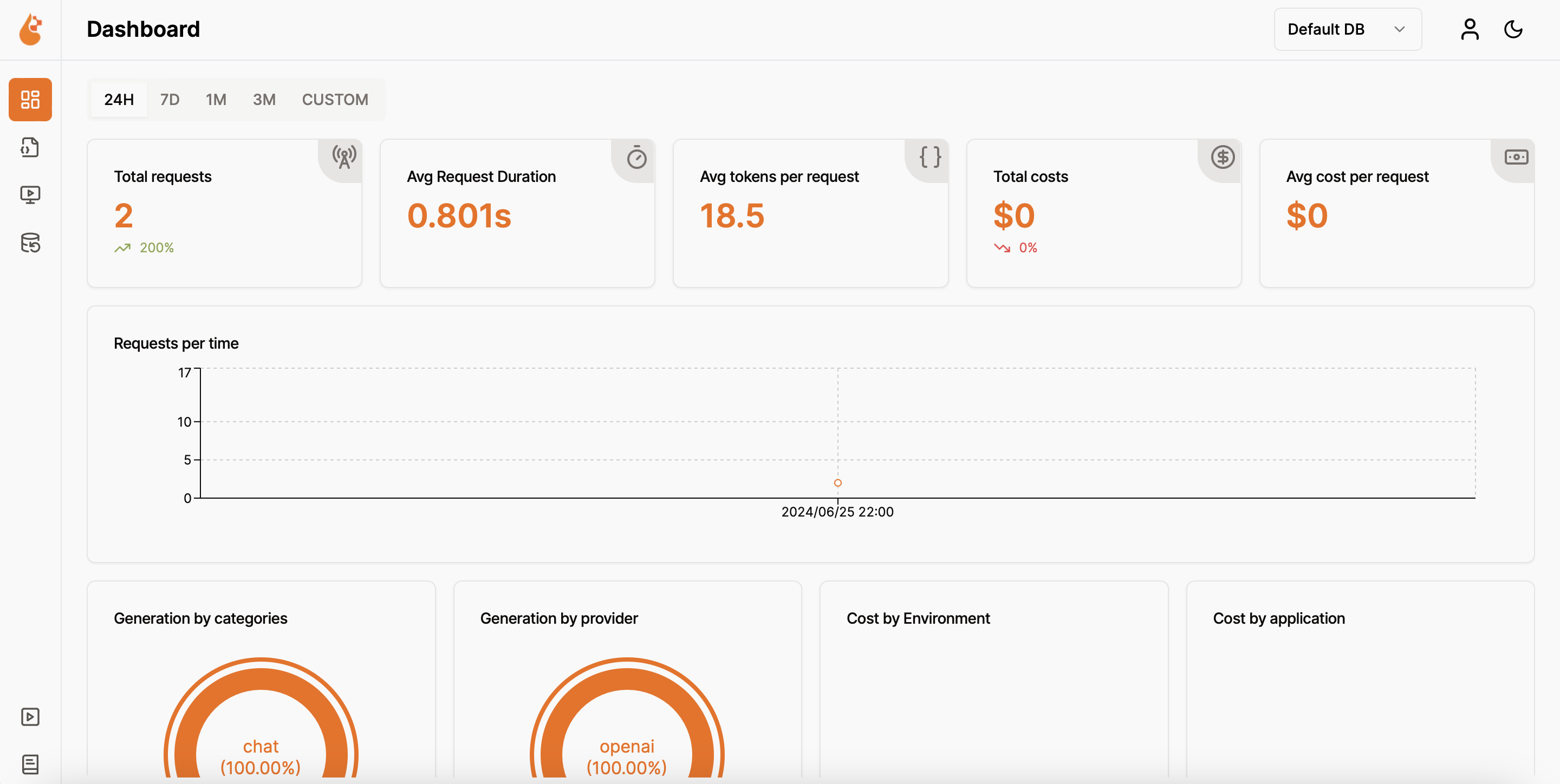
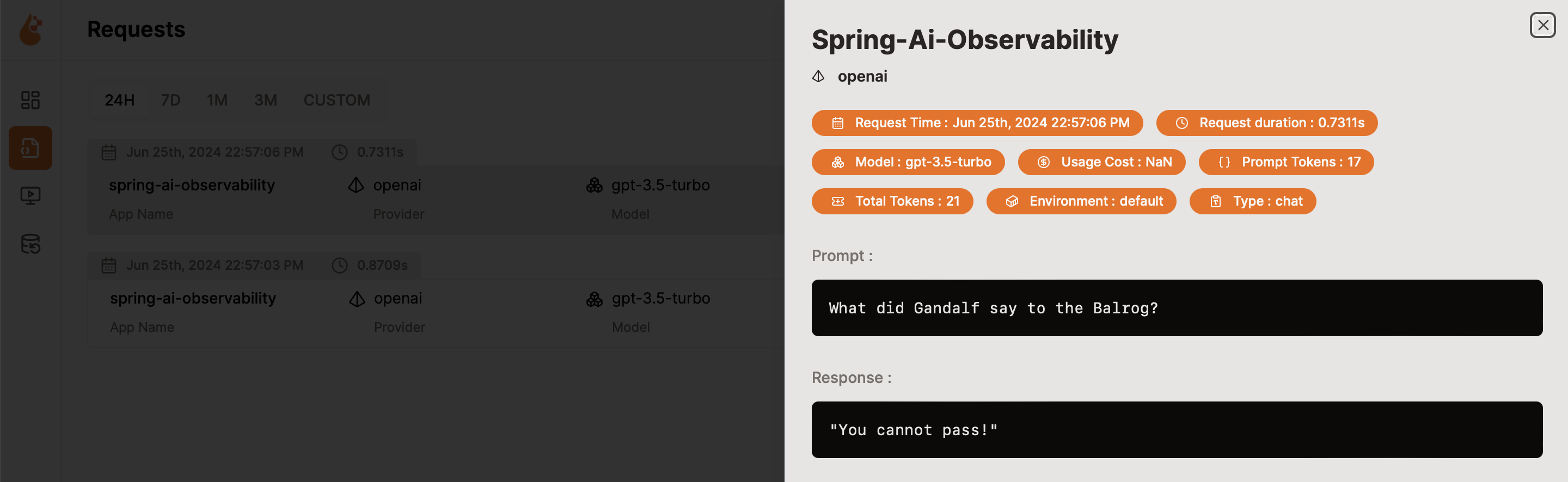
Example: Micrometer + OpenTelemetry + OpenLit (custom conventions)
Comment From: tzolov
Hey @ThomasVitale ,
This is exactly what i've been exploring in the past week or so. It is a great and promising stuff.
I did a spike: https://github.com/tzolov/spring-ai/tree/observability-support to explore what the end solution might look like.
Wanted to grasp the boundaries, challenges, limitation. To find how well we can instrument the entire execution flows and so on.
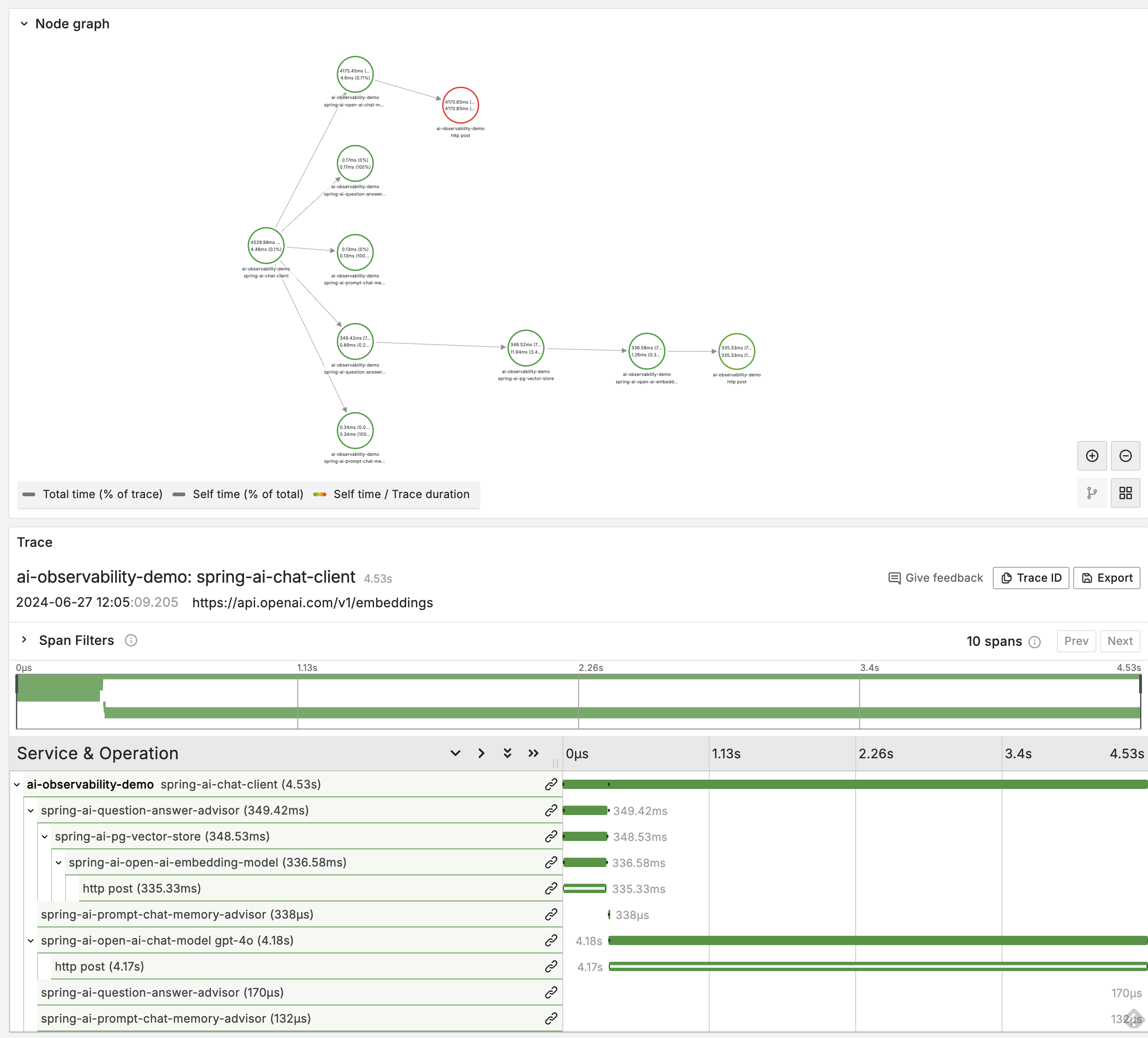
So in this branch I've implemented (basic) observation instrumentation for ChatModel, EmbeddingModel, VectorStore, ChatClient and Advisors.
I also used the ai-observability-demo app to test the E2E solution.
For example below are the Tempo traces for a RAG + ChatMemory pipeline:
var response = chatClient.prompt()
.user("How does Carina work?")
.advisors(new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults()))
.advisors(new PromptChatMemoryAdvisor(chatMemory))
.call()
.chatResponse();
@ThomasVitale I agree with most of the observation and conclusions you make above. But will contact you to start f2f discussion to clarify few technical/design problems I came across. Most importantly we need to discuss the conventions and how to structure the observations across the projects.
I will try to reach out to you on linkedin
Comment From: ThomasVitale
@tzolov I have updated the design proposal and PR based on what we talked about in the past few meetings. Thanks so much for taking the time!
Comment From: radhakrishna67
@ThomasVitale Very interesting feature to have in SpringAI
Comment From: ThomasVitale
I updated the description to clarify a few unclear points around the two parts of the proposal (Observations and Instrumentation), based on our last meeting. I also updated the PR accordingly.
Comment From: ThomasVitale
@tzolov based on the new function calling strategy, I have updated the PR to instrument correctly the chat models even when calling functions.
Comment From: ThomasVitale
We decided to go with option 2. This PR provides the initial observability support for models and instrumentation for OpenAI. More instrumentation will follow soon. https://github.com/spring-projects/spring-ai/pull/954