Bug description
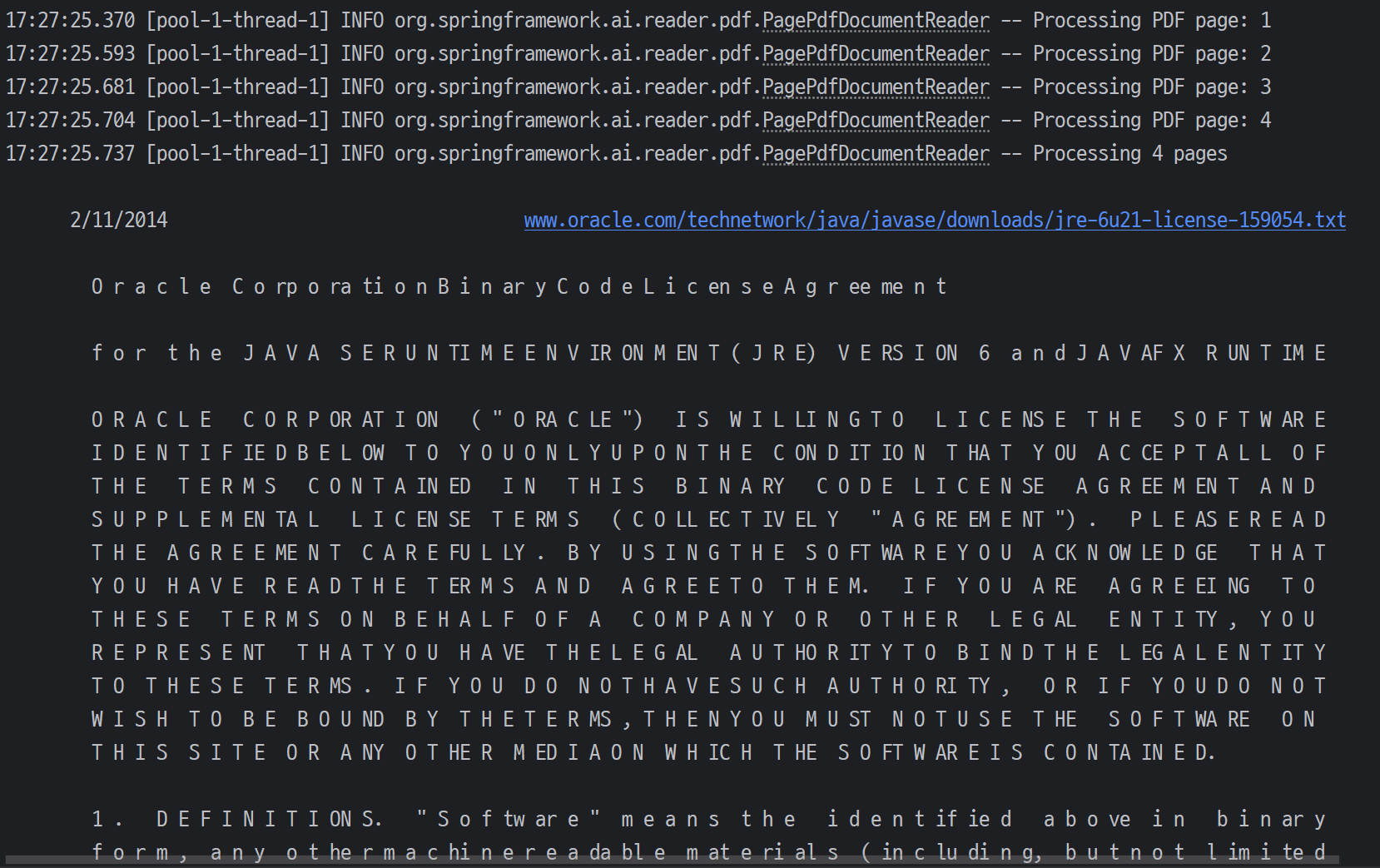
The ExtractedTextFormatter class currently uses System.lineSeparator() to determine line breaks when processing text extracted from PDF files. However, this introduces platform-specific behavior, as System.lineSeparator() reflects the operating system's default line separator (\r\n on Windows, \n on Unix-like systems). PDF files generally use \n as a line separator, regardless of the platform. This mismatch causes issues, such as line skipping not functioning correctly on Windows.
Environment Spring AI : 1.0.0-M4 JVM: corretto-21 + Kotlin (Java version 21) OS: Windows 11 / Ubunut (Windows WSL2)
Steps to reproduce
sample file : Oracle_Java_License.pdf
sample code :
```kt
test("test") { val stream = javaClass.classLoader.getResource("Oracle_Java_License.pdf")?.openStream() ?: throw Exception("Cannot find resource")
val pdfResource: InputStreamResource = InputStreamResource(stream)
val formatter = ExtractedTextFormatter.Builder()
.withNumberOfTopTextLinesToDelete(10) // Skip 10 lines from the top
.build()
val pdfDocumentReaderConfig: PdfDocumentReaderConfig = PdfDocumentReaderConfig.builder()
.withPageExtractedTextFormatter(formatter)
.build()
val pagePdfDocumentReader =
PagePdfDocumentReader(pdfResource, pdfDocumentReaderConfig)
pagePdfDocumentReader.get().forEach { orgDocs ->
println(orgDocs.content)
}
} ```
result on Win
result on Ubuntu
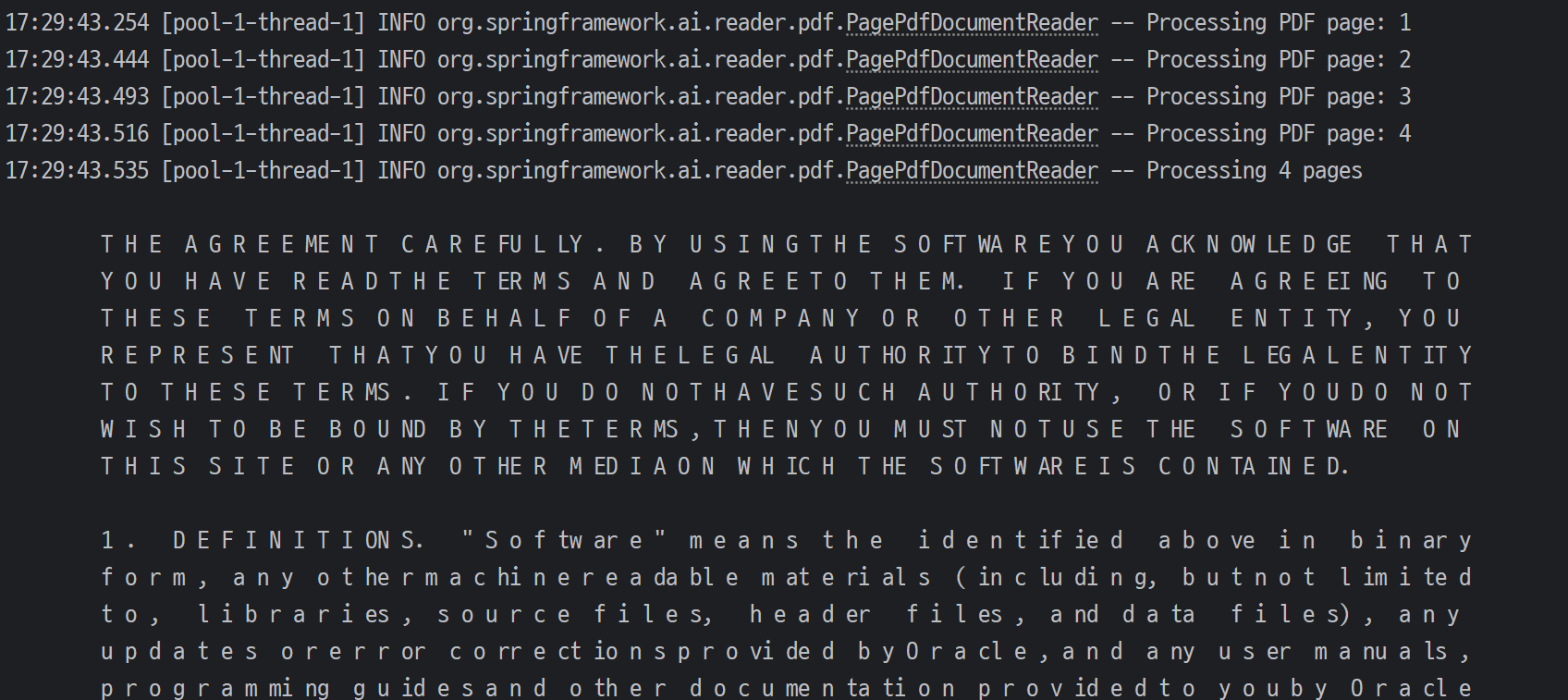
Expected behavior The line skipping should work consistently across platforms, regardless of the operating system.
Minimal Complete Reproducible example Refer to the Steps to reproduce section.
Comment From: Lee-WonJun
pr #1914