One of the use cases we have for redis at @gitlab is as a sidekiq backend. Since it is a job queue, that is a workload that relies heavily on blocking pop operations on lists.
We ran into some pathological cases with this a while back: https://github.com/redis/redis/issues/7071.
That fix already helped a lot. So did upgrading to a newer cpu architecture. But we're still peaking at ~55% CPU utilization, and it's expected to keep growing.
After spending a bit more time with the CPU profiler, I believe we may be able to optimize some more for this workload.
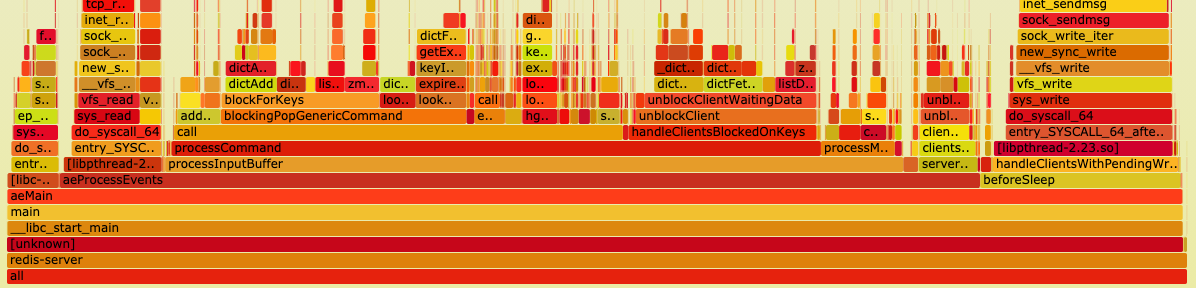
{kind=link}
This flamegraph represents 2 minutes of our production redis during peak. We're running redis 5.0.9.
The workload consists of 4-5k concurrent clients mostly performing BRPOP and LPUSHes at 1-2K QPS on a relatively small set of keys, perhaps a couple hundred. The BRPOP timeout is 2 seconds, after which it is re-issued.
Some things can be improved on our end, e.g. batching up messages, tuning timeouts, etc. We are also likely to benefit from the threaded I/O in redis 6.
One thing that is striking about this profile however is how much of it is spent in the memory allocator.
After I/O, there are three main code paths that show up in the profile:
clientsCronHandleTimeout: This is triggered by clients timing out from a BRPOP. Once the BRPOP times out, we clean upc->bpop.keys. Only to have to re-allocate and set it up again right away, as the client issues anotherBRPOPimmediately after.handleClientsBlockedOnKeys: This is triggered when a client actually gets a value from its BRPOP. In this case we do the same thing, clean upc->bpop.keys.blockingPopGenericCommand: This is triggered when a client enters BRPOP. We allocate a bunch of stuff, includingbkinfo, dict entries forc->bpop.keysandc->db->blocking_keys, a linked list node forlistAddNodeTail.
Since the set of clients and the set of keys are relatively static, we are doing a lot of allocations repeatedly.
It may be worth optimizing for this use case, as sidekiq is quite widely adopted, though deployed at various scales that may not yet have the issues we do.
I don't (yet) have any concrete suggestions, but I suspect that caching allocated values per-client could reduce a lot of pressure on the allocator, and let us reclaim quite a bit of CPU time. In our case about 23% of non I/O stacks are in je_malloc or je_free.
Of course I also understand that redis is general purpose and supports many use cases. So if optimizing for this kind of case is not a priority, that's fair enough!
Comment From: madolson
I would like to re-implement the blocking framework to remove all of the special handling we do with blocking, and instead just re-run execute processCommand when a client should be unblocked: https://github.com/redis/redis/issues/7551
I think that would help your case here, since we would be doing a lot less "extra" allocations aside from a dictionary maintaining the clients -> blocked keys. I'm not sure we could really do much else at that point.
Comment From: igorwwwwwwwwwwwwwwwwwwww
During some more analysis in this area (see downstream) we discovered another source of allocation churn: Lists becoming empty.
We noticed a big difference between two scenarios in synthetic microbenchmarks:
- Producers are pushing messages, consumers are keeping up. The queue length remains at 0.
- Producers are pushing messages, but consumers are struggling to keep up, catching up in bursts.
The second case used significantly less CPU. I instrumented signalKeyAsReady with uprobes to see how often it is getting called, and from where.
vagrant@devm:/vagrant$ sudo bpftrace -e 'uprobe:/usr/local/bin/redis-server:signalKeyAsReady { @[ustack()] = count(); } interval:s:1 { time("%H:%M:%S\n"); print(@); clear(@); }'
with 1000 consumers:
@[
signalKeyAsReady+0
pushGenericCommand+191
call+179
processCommand+1407
processInputBuffer+385
aeProcessEvents+281
aeMain+59
main+1256
__libc_start_main+243
]: 8927
with 100 consumers:
@[
signalKeyAsReady+0
pushGenericCommand+191
call+179
processCommand+1407
processInputBuffer+385
aeProcessEvents+281
aeMain+59
main+1256
__libc_start_main+243
]: 690
Interpretation:
signalKeyAsReadyis called fromdbAdd(inlined so not visible in these stacks)- with fewer clients, the messages pile up more, key allocation overhead is amortized
- clients waiting for an incoming key are much more expensive bookkeeping wise than just grabbing from a list
This suggests that keeping empty lists allocated (while still treating them as nil from a client perspective) would help in these cases. Since we don't then pay the key allocation overhead for every delivered message.