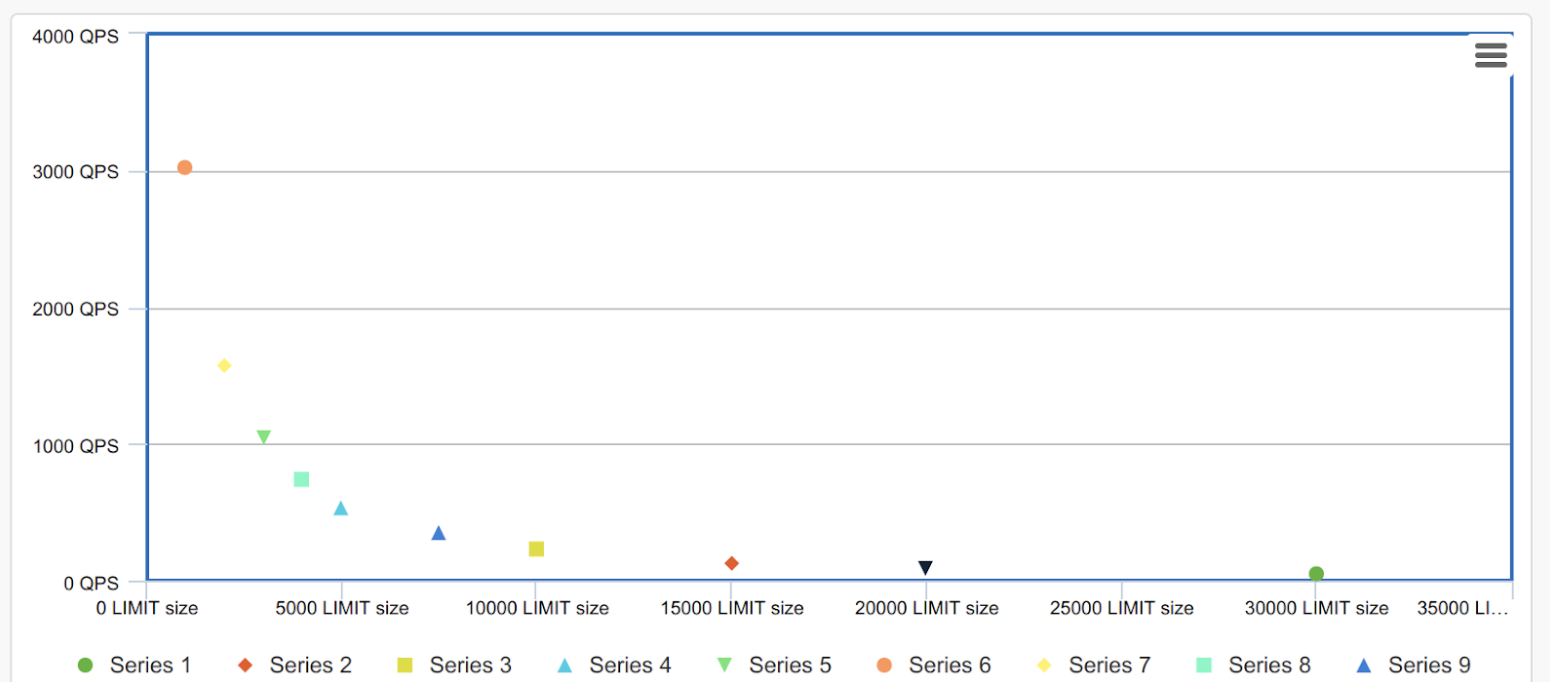
While I was benchmarking Redis for ZRANGEBYSCORE performance, I experienced significant performance degradation when increasing the COUNT value. The performance starts to drop exponentially after COUNT value roughly goes above 2.5K.
Given a ZSET of size 30K, I benchmarked Redis with different COUNT values from 1000 to 30K (without a limit), as you can see, the RPS dropped from 3000 when COUNT=1000 to 50 when COUNT=30K.
Is there any workarounds to improve the performance of ZRANGE with a large COUNT value? In my use case, the COUNT value decides my final product experience and may requires returning up to 40K results.
I tried to look for some alternatives other than ZRANGE - and ZSCAN caught my attention, but according to my research, it seems like ZSCAN doesn't guarantees the monotonicity of the returned reply comparing to ZRANGEBYSCORE.
Below is a chart with my benchmarking result.
Comment From: mgravell
Hmmm. This is very interesting. This is something I'd want to investigate properly - excellent evidence there re the graph etc. This sounds like a clear bug - could be in a few different places, and I wouldn't want to guess which!
Comment From: filipecosta90
@mgravell @yfei1 agree that this requires further investigation, but we should acknowledge that returning 30X more results is expected to have a deep impact on the command performance. A couple of questions @yfei1 so we can have more details and confirm wether the overhead is coming from the expected places ( writing reply ) : - are you returning scores? - what is the average size of each element on the sorted set? - is the benchmarked score range always the same? What is the expected reply size ( vs the total of 30K elements ). - can you share an RDB with the sample data? Or the benchmark command and expected reply size?