Describe the bug
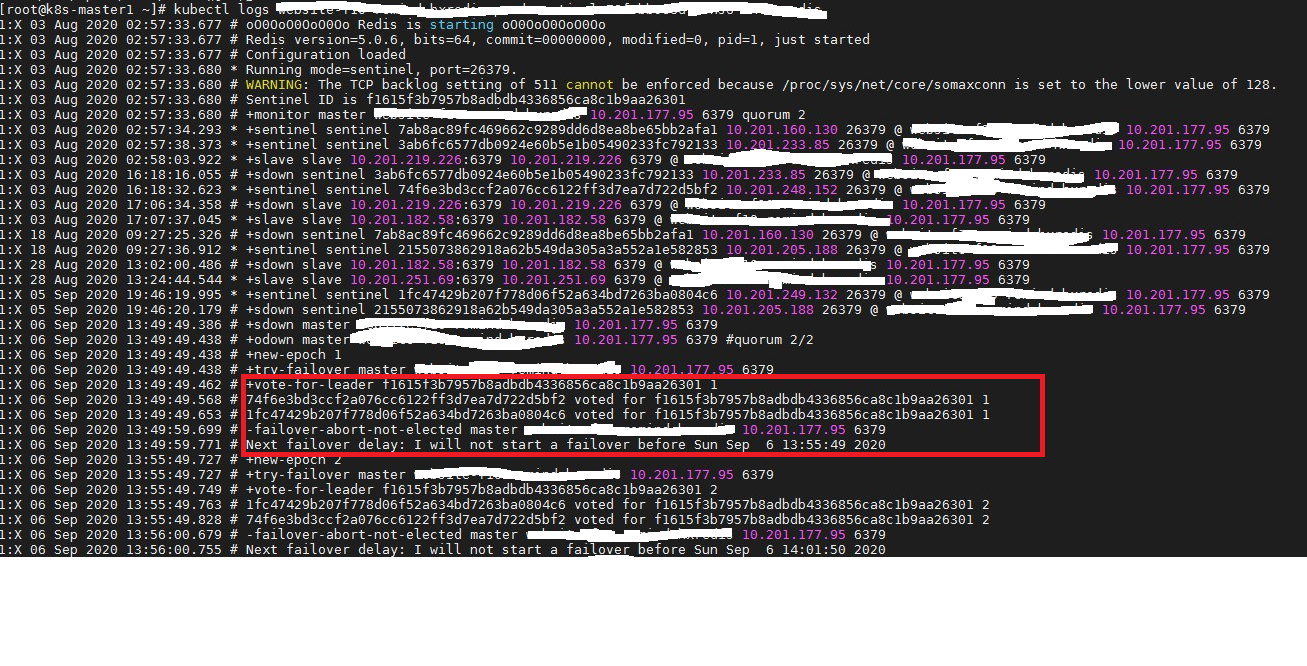
I have 2 redis and 3 sentinels. Sometimes when master down, sentinels vote to elect a leader, and a leader was elected by voting, but no failover was performed and an "failover-abort-not-elected" error was reported. The next epoch has recovered by itself
To reproduce
When master server went down, it just appeared by accident
Expected behavior
Failover instead of reporting errors
Additional information
redis version is 5.0.6, docker image is redis:5.0.6-alpine
@antirez
Comment From: cl51287
@yossigo Can you give me a hand?
Comment From: yossigo
@cl51287 Does this reproduce easily/often?
Comment From: cl51287
@yossigo It does not appear often, but once in a while.
Comment From: zhouyixiang
From the log, it looks like you have more than 3 sentinels and some of them are sdown.
Comment From: cl51287
@zhouyixiang thank you very mush, it should be that the data is not cleared after the sentinel container is offline, resulting in too much sentinel total and unable to elect a leader
Comment From: a28283878
@cl51287 I encounter the same problem, may I ask how did you solve this problem. I google the problem and people use to SENTINEL RESET * , but i'm searching for a smarter way.
Comment From: cl51287
@a28283878 I just used **SENTINEL RESET * ** to solve this problem. I used the operator to monitor sentinel. If an abnormal sentinel was found, I would reset
Comment From: a28283878
@cl51287 After searching for days, I found a solution for my scenario. I specify the ID of sentinel in k8s deployment pod. So after the sentinel down and restart it use the same ID, and other sentinels will treat it as the old one, no need to use SENTINEL RESET.