Discussed in https://github.com/redis/redis/discussions/9457
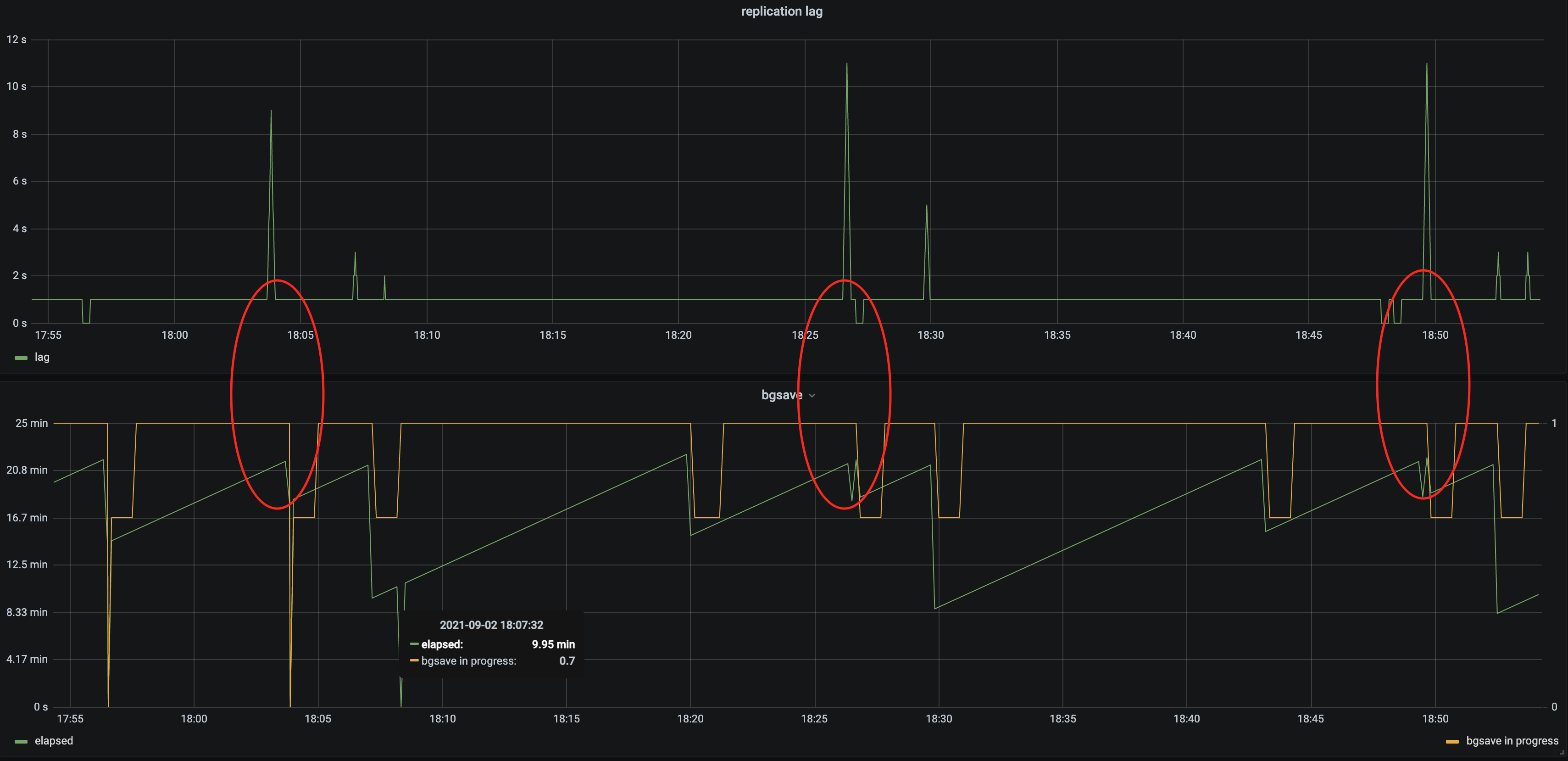 This is the current configuration:
This is the current configuration:
appendonly no
daemonize yes
databases 8
dbfilename dump.rdb
dir /var/db/redis
min-replicas-max-lag 20
min-replicas-to-write 1
pidfile /var/run/redis/redis.pid
protected-mode no
maxmemory 255092mb
save 900 1
save 300 10
save 60 10000
io-threads 13
io-threads-do-reads yes
client-output-buffer-limit replica 16gb 16gb 60
repl-backlog-size 4gb
repl-timeout 3600
86400: 1.299656368 0.000064812 write(7,"xL\^S#\M-*'\M-D \^Q@*\M-`\^D\^Q`"...,131072) = 131072 (0x20000)
86400: 1.300105565 0.000022102 write(7,"-\M^R \M-'\^De(a,b\M-`\^B\M^D"...,37480) = 37480 (0x9268)
86400: 1.300168366 0.000017520 fsync(7) = 0 (0x0)
86400: 1.300232401 0.000018878 close(7) = 0 (0x0)
86400: 1.325321507 0.024984899 rename("temp-86400.rdb","dump.rdb") = 0 (0x0)
86400: 1.325500433 0.000018393 write(224,"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"...,40) = 40 (0x28)
86400: 13.687191004 12.361617823 exit(0x0)
86400: 13.687230002 12.361656821 process exit, rval = 0
86400: 1.325321507 0.024984899 rename("temp-86400.rdb","dump.rdb") = 0 (0x0)
86400: 1.325500433 0.000018393 write(224,"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"...,40) = 40 (0x28)
86400: 13.687191004 12.361617823 exit(0x0)
Comment From: oranagra
in theory the freeze on the child process shouldn't affect the parent.
can you please set latency-monitor-threshold to some 10, and then get LATENCY LATEST after the freeze?
can you please also try reproducing this with the unstable branch? specifically #9409 can help if you have a single string key that's really big (because we break writes to smaller ones, not because of sync_file_range which is only used on Linux)
Comment From: nbari
Hi @oranagra this is the output of LATENCY LATEST after the freeze:
1) 1) "fast-command"
2) (integer) 1631702879
3) (integer) 8231
4) (integer) 8231
2) 1) "fork"
2) (integer) 1631702942
3) (integer) 2159
4) (integer) 2159
3) 1) "command"
2) (integer) 1631703798
3) (integer) 20
4) (integer) 8231
I will test now with the unstable branch redis_build_id:a5be941cf9fc2e25 - f560531, I notice that it has by default: rdb-save-incremental-fsync yes
) "rdb-save-incremental-fsync"
2) "yes"
This is the output of LATENCY LATEST after the freeze:
1) 1) "command"
2) (integer) 1631706691
3) (integer) 18
4) (integer) 6192
2) 1) "fork"
2) (integer) 1631706691
3) (integer) 1114
4) (integer) 1114
3) 1) "fast-command"
2) (integer) 1631706691
3) (integer) 15
4) (integer) 15
I didn't see any improvement, still idle for some seconds after BGSAVE finishes:
min: 0, max: 6191, avg: 0.58 (15010 samples)