I would be honored if you would take five minutes to read through my solution for expanding a hashtable with a large number of keys. @oranagra
I saw your thoughts under this pr and it resonated me a lot.
Currently a reshash come with a big price of memory, which sometimes causes eviction and data loss. this is because we allocate another hash table that's double in size, and keep the old one in parallel to the new one for a while. my idea is that instead of allocating a new hash table, we'll re-alloc the existing one, and then start moving entries from the lower half to the upper half. or alternatively when shrinking, we can maybe concentrate the entries in the lower part, and then eventually realloc the hash table to be smaller. obviously this poses some challenges in dictScan and other areas of dict.c, but i think they're all solvable.
When the hashTable does not contain many keys, rehash does not take much memory (at least it is acceptable), but as the number of keys increases, the memory required for expansion becomes larger and larger (and must be contiguous).
| ht[0].size | memory required for ht[1] capacity expansion |
|---|---|
| 4 | 64bytes |
| 8 | 128bytes |
| 16 | 256bytes |
| ...... | ...... |
| 65536 | 1024K |
| ...... | ...... |
| 8388608 | 128M |
| 16777216 | 256M |
| ...... | ...... |
I think the biggest problem with hashtable scaling is that you can use infinitely large tables (they are all nth power of 2 in size), and such large tables not only consume memory, and much memory is not immediately needed. My idea is to limit the size of the largest table, for example 65535 (15 powers of 2, occupying 1M size of memory, this specification size is adjustable according to the configuration). When we need a larger capacity table, we can use multiple such maximum tables to form this larger capacity table to use, for example, a capacity of 131072 hashtable.
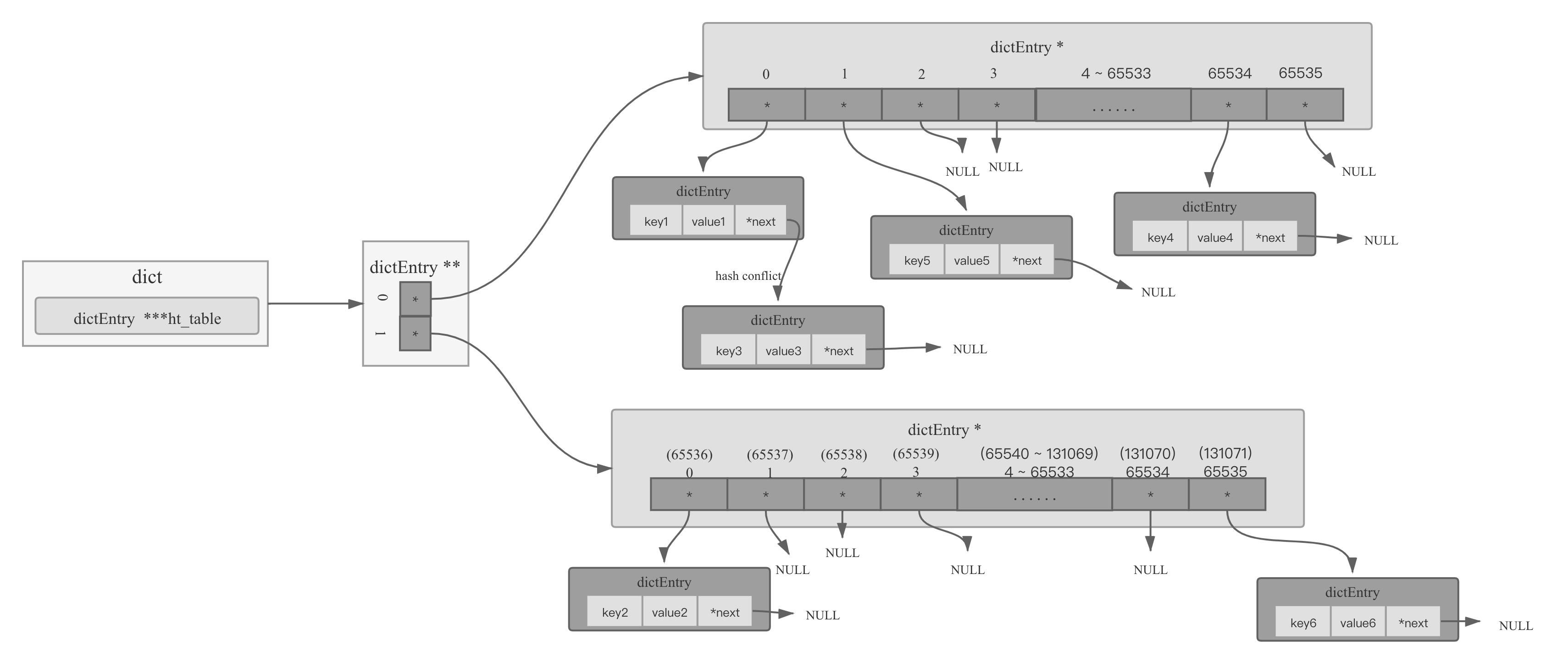
By adding an dictEntry ** array , a table of any size can be assembled, a capacity of 131072 hashtable used 2, a capacity of 8388608 hashtable used 128, etc.
This pattern of combining tables does not cause inconvenience to the lookup, insertion, expansion and traversal of hashTable, and is basically compatible with the previous way, except that it requires an additional pointer addressing, which I think is nothing compared to the benefits it can bring, such as the following expansion:

- when the hashtable is expanded just expand the dictEntry ** array
- allocate a table of size 65536 only when it is used, which is not often needed, and it has a memory limit of 1M
- overall it saves half of the memory than the original because it reuses the original table of 65536 size, and can also release a table's memory at the right time when scaling down, which is very flexible
this pattern of combining large tables is also very convenient when use scan, and like the previous way, it works better, it does not return duplicate cursor.
Of course, it is slightly more complex than the original implementation, but it can work better when there are a particularly large number of keys in a table, perhaps redis hashtable can set a threshold (for example, set to 65535) and use the combined bucket pattern when it exceeds this size.
Perhaps there are many details that I have not considered perfectly, even so, I hope that you or your colleagues can tell me, it will enable me to learn more, thank you very much!
Comment From: oranagra
@GuoZhaoran thank you for that interesting idea, so let me try to understand the process of re-hashing. let's say we have a dict with 4 hash tables (each of 65k entries). now we need to re-hash into 8 hash tables (each of 65k entries). we reallocate the root array from 4 to 8 and memset the upper half to 0. we set some state variables that mention that we're in the process of rehashing and indicate what portion was already rehashed and what wasn't (so that dictFind can still work). Then we allocate the first one of the new 4 entries (an allocation of 65k pointers) and start re-hashing the elements of ht[0] into ht[4]. when done, we move to the next table (rehashing ht[1] into ht[5]), is that right? so in some sense it's an evolution of the realloc idea i suggested (we don't keep two full hash tables), but also we don't have a huge realloc (which includes a huge memcpy), and the memory growth (doubling the size of the hash table) is gradual rather than happening at once. in both cases we don't scale to x3 and then back to x2 (which we do today). did i get it right?
i'll need to read this more carefully later and think about it. meanwhile i'll ask others to take a look in the context of other improvements we're considering.
Comment From: GuoZhaoran
@GuoZhaoran thank you for that interesting idea, so let me try to understand the process of re-hashing. let's say we have a dict with 4 hash tables (each of 65k entries). now we need to re-hash into 8 hash tables (each of 65k entries). we reallocate the root array from 4 to 8 and memset the upper half to 0. we set some state variables that mention that we're in the process of rehashing and indicate what portion was already rehashed and what wasn't (so that dictFind can still work). Then we allocate the first one of the new 4 entries (an allocation of 65k pointers) and start re-hashing the elements of ht[0] into ht[4]. when done, we move to the next table (rehashing ht[1] into ht[5]), is that right? so in some sense it's an evolution of the realloc idea i suggested (we don't keep two full hash tables), but also we don't have a huge realloc (which includes a huge memcpy), and the memory growth (doubling the size of the hash table) is gradual rather than happening at once. in both cases we don't scale to x3 and then back to x2 (which we do today). did i get it right?
i'll need to read this more carefully later and think about it. meanwhile i'll ask others to take a look in the context of other improvements we're considering.
Hello oranagra, your understanding is exactly right (I learned this idea from you), the process of rehashing this scheme makes the memory grow gradually to twice the size of the hash table. I saw your team's discussion about optimizing expired keys and felt that everyone was very passionate about these improvements. But here I would like to make a more systematic summary of our improvement ideas and would like your help to analyze whether they are correct or not, divided into two points.
First is a theoretical formula, if now our dictEntry ** array stretches to the mth power of 2, and the largest table we can use to define hashtable is the nth power of 2 (that is, the size of dictEntry *), then the capacity of our hashtable is
hashtable capacity = (1 << m) * (1 << n)

When we define n=12, when m is extended to 12, we can get hashtable with capacity 16777216 (4096*4096), which is quite a large hashtable and it is sufficient in most cases, of course, it can be extended to meet the needs of larger capacity, and the extension process is done step by step in 4096 bytes of memory size.
Maybe we don't need such a large hashtable in our business, and we don't need such a large memory size of 4096 bytes as a unit, we can define n smaller, like 8, then the expansion process is still easy to operate, when m is expanded to 8, we can also get a 65536 capacity hashtable (256*256), these can be flexibly configured according to the needs.
Then there are some conclusions (I think they are correct, but not sure).
-
My first idea is that this solution is also friendly for hashtable shrinkage, the process doesn't need to request memory and it frees unused memory gradually.
-
The second idea is that is for hashtable, as the key grows more and more, the smaller the chance of reshuffling, and the larger the maximum table n we define, the smaller the chance of m growing as the key grows.
I have another question, if we add the dictEntry ** array, it will make us use one more pointer to find the elements than the current hashTable implementation, will this affect the performance?
Comment From: oranagra
@GuoZhaoran thank you. i'm less concerned about deciding on the right N and M to use, we can experiment and adjust them later.
my concerns are: 1. the extra indirection (it'll surely affect performance) 2. the effort of coding this will require 3. whether the effort is worth it, considering we may some day move away from dict.c entirely (for either a faster or more memory efficient data structure, or for sorting keys by TTL).
btw, please be aware of #8700
i'm not concerned about: 1. the complexity it'll add to the code base (since it's all local to dict.c) 2. whether or not this will work with up-scaling / down-scaling, and dictScan (i'm quite sure it will) 3. whether or not this will solve the problem (i'm quite sure it will)
maybe we can attack this gradually, making an incomplete POC to test the performance impact (without code for rehashing and scan). maybe if the first lookup table is small, it'll likely to be in the CPU cache.
maybe we can add some logic to redis to somehow switch this mode on and off automatically, but this will actually cause the switch to be expensive. i.e. the only reason we're not paying a high price in rehashing is that we're devoting another lookup from the get go.
Comment From: GuoZhaoran
@GuoZhaoran thank you. i'm less concerned about deciding on the right N and M to use, we can experiment and adjust them later.
my concerns are:
- the extra indirection (it'll surely affect performance)
- the effort of coding this will require
- whether the effort is worth it, considering we may some day move away from dict.c entirely (for either a faster or more memory efficient data structure, or for sorting keys by TTL).
btw, please be aware of #8700
i'm not concerned about:
- the complexity it'll add to the code base (since it's all local to dict.c)
- whether or not this will work with up-scaling / down-scaling, and dictScan (i'm quite sure it will)
- whether or not this will solve the problem (i'm quite sure it will)
maybe we can attack this gradually, making an incomplete POC to test the performance impact (without code for rehashing and scan). maybe if the first lookup table is small, it'll likely to be in the CPU cache.
maybe we can add some logic to redis to somehow switch this mode on and off automatically, but this will actually cause the switch to be expensive. i.e. the only reason we're not paying a high price in rehashing is that we're devoting another lookup from the get go.
@oranagra Thank you for giving me the idea and historical background of the analysis of dict transformation, I learned the idea of HAMT and I will take time to study it more deeply afterwards.
I also think your long term idea of the perfect solution (maybe using rax trees with some other shiny ideas) for hashtable (for either a faster or more memory efficient data structure, or for sorting keys by TTL) could eventually be implemented, even if it takes a while to explore,i will keep an eye on this pr: [NEW] Optimize expire #9480, I think it is the final implementation of hashTable (more perfect than HAMT).
I think that many things are not always born particularly perfect, they all need an evolutionary process, such as the multi-threaded system of redis (at first there was no lazy free bio thread, Redis 4.0 added it. Redis didn't have multiple IO threads at the beginning, Redis 6 introduced them, and I'm sure Redis 7 will make it even better).
We should probably try add some logic to redis to somehow switch this mode on and off automatically, Even if it will be replaced at some later time.But maybe HAMT isn't performing as well as we'd hoped? Or maybe hashtable is still available as an option in redis7? Then the work we've done makes a lot of sense, don't you think?
Comment From: oranagra
@GuoZhaoran it doesn't look like HAMT (or improved multi-threading) is gonna make it for redis 7. it looks like it imposes too many problems at this point, both performance and also with SCAN. maybe i'm just narrow minded, and can't imagine that leap.
For now, we don't see others responding with feedback, so considering the concerns i listed above, if you have spare time i think you can try to POC that idea and benchmark it.
Comment From: GuoZhaoran
@oranagra I don't think you are narrow minded, just doing analysis based on the facts available, thanks for your guidance, i will try to POC that idea and benchmark it in the next while.
Comment From: madolson
@oranagra I'm pretty sure no one else commented because it's been a weekend ;). I noticed while reading through this you mentioned the realloc strategy. Realloc doesn't necessarily do a memcpy, but will will just update virtual memory pages mapping updates (mremap is the linux command) so it's able co quickly copy 4KB pages. So realloc is still O(N), but it's faster than memcpy. I built an implementation on it a couple of years ago, but we never published it because when you get up to around ~10M entries the realloc time starts hitting single digit ms, which we thought was likely too slow for redis.
@GuoZhaoran I basically agree with Oran's analysis and think the next step is probably a PoC to evaluate the performance implication. We should be able to implement that with a pre-allocated number of hash slots and then inserting values into it, there is a "benchmark" at the bottom of dict.c you can use for reference.
I do think the implementation will be more involved than we expect, and I don't think the overallocation problem is one that is so critically worth solving.
Comment From: oranagra
I'm pretty sure no one else commented because it's been a weekend ;)
Yeah, no complaints, it just looked like @GuoZhaoran can already proceed with a POC since I'm not expecting any pushback.
AFAIK, what you mentioned about in-place reallocs will only be possible with jemalloc in large class allocations (above 16k), sine the lower ones are managed in bins, but these are not the subject of this discussion. I actually never bothered to check how it handles lager ones. I'll look into it, but if you can shortly describe it here that would be helpful.
But anyway even with the memcpy issue aside, this design has an advantage over my initial design, and certainly over the current code. And if the extra lookup turns out to be an issue, we can fall back to mine.
AFAICT, The only reason not to do these is if we cant invest the coding effort or plan to move away from dict.c soon.
Comment From: madolson
You are right about the 16kb class allocations, but that is when things start to get more interesting anyways.
Comment From: GuoZhaoran
I basically agree with Oran's analysis and think the next step is probably a PoC to evaluate the performance implication. We should be able to implement that with a pre-allocated number of hash slots and then inserting values into it, there is a "benchmark" at the bottom of dict.c you can use for reference.
I do think the implementation will be more involved than we expect, and I don't think the overallocation problem is one that is so critically worth solving.
@madolson Thanks for the tip, I see that the dictTest method is at the end of dict.c, which is helpful. I'm checking to learn the latest code of dict.c, it's very high quality and easy to understand. I'm thinking of adding very little logic to it to make it more natural to switch to this mode. I'm also concerned about the coding complexity and the efficiency of the lookup execution, but let me give it a try, maybe the result is not as bad or better than we thought (maybe my expectations are too high)
Comment From: zuiderkwast
This looks like a really good idea. Go ahead and implement it! :-)
I don't think indirection is a problem for a small ht_table (the dictEntry**), since if it's small, it will always be in CPU cache.
I guess it will affect hashes, sets, zset, etc. too, right?
The HAMT is more compact but it has even more indirection. The problem with the HAMT PR is not SCAN (it has been solved and explained). The main problem is only debugging to make the tests pass. There are some failures that I don't understand. Apart from that, the HAMT is using small allocations and can probably cause much fragmentation so active defrag is very important for HAMT. Now, it has also diverged when we stared to embed more stuff in dictEntry.
For these reasons, I think this two-level hash table might be better than HAMT. With 65536 x 65536, we have 4G keys, so we'll never need more than two levels AFAICT.
I also find it very hard to believe that some other killer datastructure will take over. RAX is not good for long keys. Sorting by TTL is only good for expire, but not for key lookup... Some form of hash table will most likely remain the core of Redis.
Comment From: oranagra
@madolson apparently, jemalloc no longer uses mremap (looks like it caused complication or some kernel issues, not sure yet, but it was loooong ago).
i also tested this in redis, a realloc from 1gb to 2gb.
observations:
1. jemalloc uses huge allocations for such sizes, and dedicates a separate mmap for each allocation.
2. jemalloc doesn't use mremap or any other special tricks (validated with strace)
3. measured realloc time after memset, the realloc took more time than the memset (since it does both read and write)
4. after realloc, jemalloc doesn't immediately release the old memory map or return the pages to the OS (both the 1gb and 2gb regions remained resident (verified in /proc/<pid>/smaps)
5. eventually, if not reused, jemalloc will return the pages to the OS by the decaying mechanism (will keep the mapping)
Comment From: madolson
@oranagra i did some basic testing, and found that realloc was almost 100x faster using libc vs jemalloc, for large allocations (~10MB and larger). So I suppose we do really need to be conscious of it, which is a bit disappointing.
I wonder what the complications with jemalloc came up.
Comment From: zuiderkwast
Here's an explanation of why they stopped using mremap: http://jemalloc.net/mailman/jemalloc-discuss/2014-April/000757.html -- that mmap is using a linear scan in the worst case.
Here's the commit which removed the possibility to use mremap: https://github.com/jemalloc/jemalloc/commit/e2deab7a751c8080c2b2cdcfd7b11887332be1bb (2014).
Remove the --enable-mremap option. As jemalloc currently operates, this is a performace regression for some applications, but planned work to logarithmically space huge size classes should provide similar amortized performance. The motivation for this change was that mremap-based huge reallocation forced leaky abstractions that prevented refactoring.
Could we use try using mremap directly for large allocations, just for the dict ht?
Comment From: oranagra
We can't use that on our own (unless we also allocate these on our own, rather than though the allocator, and that would be a big mistake for redis), Also from what i understand, even if we could, that would still be able to cause the performance issues they mention (which happen after such reallocs due to the VM fragmentation they cause). p.s. note that this commit just removed a feature that was already disabled.. it was disabled long before (v3.0 / 2012).
Comment From: zuiderkwast
Yeah, I meant that we'd allocate the dict ht exclusively using mmap/mremap (at least for >= 4K) on Linux. Since the ht is always a power of two, it wouldn't cause the problem mentioned (if I understood correctly). We could add wrappers in zmalloc.c which records the memory stats. Why would that be a big mistake?
Comment From: oranagra
allocators are very complicated and consider a wide range of issues (many usage patterns, that possibly change over time on a long running execution) on a wide range of platforms (and their quirks). we try to choose the best one and just trust it (we do bother to know how it's working internally so that we don't do things that are inefficient).
IMHO writing our own allocator or taking a portion of the allocations to our own allocator, is like deciding to implement a custom file system. it's an expertise of its own, and if we think we good at it, we might just as well, start a new project (for the allocator).
more specifically for this case (even if we don't abuse zmalloc with these bypasses), and just dict.c, i'm afraid that we can fall into the same problem which jemalloc had (VM fragmentation), and will not necessarily know how to test that we don't suffer from the same implications (maybe after a long period of time or some specific workload). also, what's worse, is that we may be implementing something too naive, completely losing some basic advantages that are textbook case for jemalloc. we can open a separate issue about that and invite Jason to comment, or instead start a discussion in jemalloc's github or respond to an old one. we can also explore other allocators and conclude jemalloc is no longer the right choice for redis (also a separate issue / discussion)
Comment From: zuiderkwast
Another idea: Would it be possible to do the large ht malloc and free asynchronously in another thread, so that the main thread can continue serving clients? If I understand it right, there is a special arena shared among threads for large allocations (opt.oversize_threshold, 8MiB by default). The main thread would not start incremental rehashing until the allocation thread is done allocating.
Comment From: GuoZhaoran
I've been silently following your professional discussions while coding to validate my idea.
hello, @zuiderkwast , If it is possible to start a BIO thread for rehash, can we be more radical? As far as I know, the life cycle of redis providing client services can be roughly divided into three phases
- parsing instructions, calling the readQueryFromClient function
- execution of instructions, calling execCommand similar functions
- respond to the client, calling the writeToClient function
The third phase is more time-consuming (redis added some IO threads to help complete these tasks faster), I think in this phase, the work of rehash through BIO threads can also be carried out in parallel, without affecting the premise of providing services to the client, so that the database needs to rehash the dict as soon as possible to complete.
on this point, I would like to hear your professional analysis and that of your colleagues.
Comment From: oranagra
@zuiderkwast maybe I got lost, but this whole discussion about realloc being slow was related to the previous design (the one in which I suggested a realloc of x2 rather than a malloc of x2 and memory usage of x3), but in the new design suggested here there's no huge realloc (and even if realloc was fast, that idea is still better due to gradual memory increase rater than sudden).
P. S even if we went with that old idea, or target the smaller realloc of the new idea, I don't see how we can send the realloc to be executed in the bg thread (considering a very slow realloc) , since we need the ht to serve clients. If I understand the suggestion above, it's only valid for a realloc that doesn't take that long (up to few milliseconds, to be run in parallel to network / io) and considering that this is a rare event, I don't think the complexity would be worth it.
Comment From: zuiderkwast
@oranagra Sorry if I lost you. There are some parallel discussions going on here.
-
The realloc discussion is about your idea of rehashing without moving everything to a new allocation. (Pretty smart, if realloc is fast.)
-
This issue is about a nested hashtable design without huge allocations. (Very good but it requires some work.)
-
The idea of moving malloc and free to a background thread is about the original dict with huge allocations, a simple hack. That's why I put the comment in that other PR first. The new allocation is not immediately needed to serve clients. It is only needed to start the rehashing, which we do incrementally while serving other clients anyway. The idea is only about avoiding the malloc and free which freeze the main thread.
When the dict reaches a ratio of 1:1 (entries/slots), we start expanding it, but there is still some space in the old ht. If the ht fills up very fast to, let's say ratio 2:1, before the new allocation is available, we'd still have to freeze the main thread and wait for the allocation. If the expand is triggered by a large burst of inserts, then it might not be very useful, but if it's a mix of inserts and deletes, this trick might help. Let's say we'd only use it for allocations > 100M or so.
If the freezes are rare and the complexity is not worth it, fine. If we have another solution, also fine. If it's simple to try, I might try it though. :-)
@GuoZhaoran The rehashing (moving slots from one ht to another) needs to keep the ht consistent with the main thread, so if we do it in another thread we'd need locks. Therefore, I think it's safer to do it in the main thread. The idea was only about doing the slow malloc and free in another thread.
Comment From: oranagra
The idea of moving malloc and free to a background thread is about the original dict with huge allocations, a simple hack. That's why I put the comment in that other PR first.
Ohh got you.. So it's not even about my realloc idea (since in that case we do need it in the main thread immediately), it's just about avoiding freeze with the current rehash code we have in unstable.
I suppose it's just timing.. Had I seen that comment there a month ago I would have got it, but now after the realloc efficiency discussion here, I had the wrong context.
It still have some complexity (since dict.c is generic and it'll need the help from Redis and some global flags).
Anyway, I don't particularly like that idea, and I also wanna solve the memory issue, not just the freeze, so I wanna proceed with the idea discussed here (which is more complex, but local to dict.c)
Comment From: zuiderkwast
All good. I'll drop it then. :grin: Btw, I think some of these are orthogonal. For example, your realloc idea can be combined with the nested hashtable idea (although the 3X memory during rehash matters less with smaller allocations).
Comment From: GuoZhaoran
@oranagra @madolson @melo Hello everyone, I would be very sorry if I interrupted your work or life (I always seem to forget about jet lag). I implemented a simple POC to evaluate its impact on performance (it took me some time to get these data). If you have questions about my testing scheme and implementation, here's a pr commit an incomplete POC for dict's evolution to test the performance impact. Below are some core test data
- Maximum table capacity 65536, Linear access of existing elements
benchmark number |1000000|3000000|5000000|8000000|15000000|30000000 -----------|:----|----|----|----|----|----| dictFind|454/452/457|1353/1363/1359|2282/2262/2256|4089/4083/4039|8078/8076/8086|17212/17005/17049| dictXFind|450/456/451|1392/1378/1377|2267/2307/2280|4130/4146/4121|8457/8120/8110|17865/17358/17449| Performance loss|+0.0044|-0.0176|-0.0079|-0.0152|-0.0184|-0.0274|
- Maximum table capacity 65536, Random access of existing elements
benchmark number |1000000|3000000|5000000|8000000|15000000|30000000 -----------|:----|----|----|----|----|----| dictFind| 662/661/681 | 2168/2123/2119 | 3566/3564/3549 | 6107/6213/6150 | 13461/13309/12726 | 29135/28809/28939 | dictXFind| 675/673/673 | 2150/2135/2140 | 3598/3584/3587 | 6212/6213/6290 | 14591/12684/12613 | 29466/29057/29255 | Performance loss| -0.0084 | -0.0023 | -0.0084 | -0.0132 | -0.0099 | -0.0103 |
- Maximum table capacity 65536, Accessing missing
benchmark number |1000000|3000000|5000000|8000000|15000000|30000000 -----------|:----|----|----|----|----|----| dictFind| 529/527/529 | 1684/1674/1683 | 2639/2610/2641 | 4928/4970/4960 | 10303/10174/10131 | 21668/21588/21826 | dictXFind| 536/536/530 | 1686/1681/1666 | 2691/2697/2732 | 5098/5044/5015 | 11410/10066/10051 | 22067/22000/22346 | Performance loss| -0.0107 | +0.0015 | -0.0291 | -0.0201 | -0.0209 | -0.0204 |
It is about 0.008 times slower when the batch test data set is relatively large (over 5 million).
I did some analysis of the complexity of the coding implementation and indeed, As we thought of, I added a global variable to the original dict structure and named it dictX. The two forms of dict are compatible and easily convertible (when the threshold of the maximum table definition is reached), for the methods dictFind, dictRehash, which are different ( These implementations have some complexity, but the corresponding implementation ideas are similar), we can implement these extensions without modifying the original code of dict.c through pattern judgments, and overall it seems to me that it is more optimistic than we thought.
Comment From: oranagra
this seems like a price we'll be willing to pay, also IIUC the price becomes higher only when the dict is larger?
i'm assuming you used dictTest and if i understand correctly how you used it, the iteration count dictates both the number of records in the dict and how many iterations we're benchamrking. so when count is low, the benchmark is probably not very accurate.
also, considering the entire dict gets into the CPU cache, i suppose this benchmark is not very fair. i.e. in a normal workload of redis where we'll have many other keys and procedures being accessed the extra lookup has lower chances of being in the cpu cache, even if the table is small.
@filipecosta90 maybe you have an idea how to correctly benchmark this? maybe force the CPU cache to be dropped or just involve a larger workload?
regarding dictX and the dictEvolution / dictRewind. IMHO we don't want to keep supporting both at the same time, we'll use just the new format, and for the benchmark you can just test against another branch. as noted earlier, the only way we gain from doing efficient rehashing is if we used the new data structure from the get-go, switching to it just when the rehashing price becomes high, will mean the swtich will be pricey. maybe an exception to this is the really small dicts (less than few thousand records), but i don't think we wanna pay the code complexity of maintaining two data structures.
another concern is maybe memory consumption, i.e. for a really small dict (of 16) items or alike, the extra memory usage will be (relatively) high, so if someone has many many small hash keys, it'll have an impact. but that's what we have ziplists (or nowadays listpack) for, so i think that when we switch to dict, we don't want to consider two types of dicts.
Comment From: GuoZhaoran
i'm assuming you used
dictTestand if i understand correctly how you used it, the iteration count dictates both the number of records in the dict and how many iterations we're benchamrking. so whencountis low, the benchmark is probably not very accurate.
Yes, I used dictTest to get the data. I think maybe it makes more sense to specify the number of records in the dict and the number of iterations with two parameters, because it's easier to hit the CPU cache when there are fewer records in the dict, which will make the test data look better. Do you think I need to pull a branch to make a change to this?
@filipecosta90 maybe you have an idea how to correctly benchmark this? maybe force the CPU cache to be dropped or just involve a larger workload?
If you provide more professional testing methods, it would be really appreciated, maybe I am still missing rehash, add related test data, I plan to bring these in my next code commit.
regarding dictX and the dictEvolution / dictRewind. IMHO we don't want to keep supporting both at the same time, we'll use just the new format, and for the benchmark you can just test against another branch.
dict and dictX are one structure, and this time I let them be parallel to facilitate coding (without polluting the original content of the other dict.c), I'm very sorry if this is confusing for you. My idea is the same as your suggestion: let dict switch naturally from one form to another (the timing of the switch is when the number of elements in the dictionary reaches the threshold of the defined maximum table), and for that I have a preliminary idea to make it merge with dictX by simply modifying dict, the exact change is this :
// current structure
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx;
int16_t pauserehash;
signed char ht_size_exp[2];
};
// modified structure
struct dict {
dictType *type;
/* depending on the form of the hashtable, it could be dictEntry** or dictEntry***. */
void *ht_table[2];
unsigned long ht_used[2];
long rehashidx;
int16_t pauserehash;
/* ht_status[0]、ht_status[1] stored information is the same as ht_size_exp[2], ht_status[3] replace the
maximum_ht_num in dictX ht_status[4] allows to customize the maximum table size, the default is DICTHT_MAX_CAPACITY_EXP */
signed char ht_status[4];
};
- Modify the type of ht_table to void *, the content of the ht_table array depends on the shape of the dict
- Expand ht_size_exp size to 4 to store more status information.
Do you think there is anything wrong with my design like this? It can solve the memory problem and also adapt to more scenarios by flexibly defining the size of the maximum usage table.
The workload seems not small and I want to do this in two steps.
-
first dictX will be modified so that it can be better integrated with dict, adding the missing logic of dictRehash, dictAddRaw, using more scientific testing methods providing other test data. At this point, dictX and dict will still be in parallel, is this acceptable to you? This won't last long, and I will also explain this in the comments and during coding.
-
Replace the old dict completely with the new dict structure, and do the coding for the new form of dict (will involve dictScan, dictFind, dictRehash ......) I am considering how to do this without polluting dict.c and keeping the readability of the code good.
Comment From: oranagra
@GuoZhaoran if you rather work on it while still keeping the old dict functional and then delete it, that's ok with me. personally i'd rather review change to existing code rather than new code which is in part duplicated, but either way can probably work.
My idea is the same as your suggestion: let dict switch naturally from one form to another
IIRC i suggested this and immediately dismissed it since: 1. the price of converting from one form to the other can be high (higher than a normal rehashing of the new design). i.e. the whole purpose of the new design is for smoother rehashing, so it'll be silly to pay a high price when switching to it. 2. even if we can somehow just copy an HT pointer from the old dict to the new dict when doing the conversion, without paying any price on the conversion, maintaining both versions of the code is not a good idea, it's a lot more code to maintain, but it also means that many tests will not pass though the new code so it'll have low coverage. 3. IIUC your benchmark showed that the performance loss on the extra lookup is acceptable (still needs additional benchmark).
regarding the benchmark, if no one else has any advise, then: 1. i do think the dictTest needs separate control on the number of items from the number of iterations. 2. i still think we wanna also have a more realistic test in which the CPU cache is bothered both other work. maybe that can be done by using real client like memtier-benchmark with pipeline, to create variations on hash-type keys, some tests with lots of small dicts, and others with fewer big ones, or plain strings.