I want to start a conversation about trying to come up with a more memory efficient main Redis dictionary. The motivation primarily being that a lot of users of Redis have a lot of small strings and values, and Redis has ~52 bytes of overhead for every value and ~32 bytes of overhead for TTL. If you have a lot of small keys/values, this overhead will dominate. It's still worse for cluster mode, since there is another 16 bytes of overhead.
I'm not necessarily implying I have an answer, but think we should be investigating this further. If other folks have relevant ideas, maybe we can discuss it here.
Background (Current structure)
Currently keys and values are stored in a simple Hashmap that uses a linked list to resolve collisions. The key is stored as an SDS inside the map, with the value being a "redisObject" which is a container with some metadata.
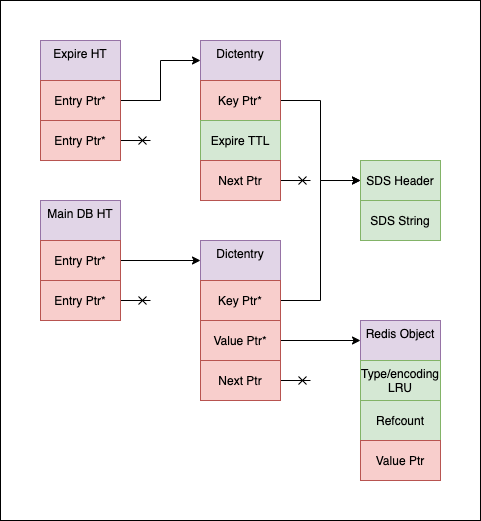
52 bytes: - 8 byte dictEntry pointer(Assuming 100% load factor on DB) - 24 Bytes for the dictEntry (8 byte key, 8 next, 8 byte value) - 16 byte Redis Object (4 byte for type/encoding/LRU, 8 for value pointer, 4 for refcount) - 4 bytes for SDS overhead (max 3 bytes + \0, might be a bit less with jemalloc arenas)
32 Additional bytes for TTL: -8 byte dictEntry pointer in TTL table (Assuming 100% load factor) -24 byte dictEntry
Additional memory for cluster Mode: - 16 byte, next and previous pointers for maintaining the slot to keys mapping.
One possible alternative
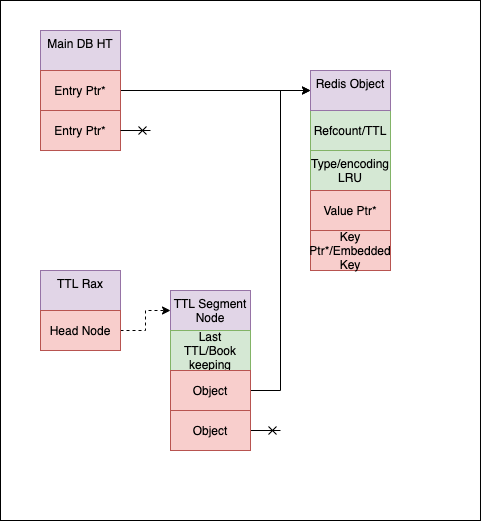
- Use an open addressing scheme and embed the value directly into the main dictionary (Saves 8 bytes, no next. Not strictly required, means a good bit of work to figure out how to maintain SCAN/rehashing, but it's doable).
- Promote the Redis object to be the dictEntry, saving a pointer. (Saves 8 bytes)
- Embed the key when possible, which is basically always unless it's really large. Prefetch the value before doing the key comparison. Unlike embedded string robj, all key/values have an embeddable string, and most keys are shorter than values. (Our internal estimates says average key ~17 bytes, easily embeddable!) (Saves 8 bytes if we can embed the key)
- Embed the TTL information into the refcount. AFAIK we don't have high refcounts, so stealing some of the TTL precision should be OK. (No memory saving, just moving data around). We are removing the key->TTL dictionary, so we need to keep track of it.
- Replace the TTL dictionary RAX, which maps TTLs -> buckets. TTL buckets will be a fixed number of Redis Objects with similar TTL, buckets will be split as they fill up and will be marked so they can be dropped together. (Saves about 8 bytes) The intuition is that most of the time items are going to be added near each other (You're usually incrementing the expire or setting it to a fixed increment in the future) so blocks will typically be mostly full.
Total saves about 16 bytes, potentially an extra 8 for embedding key. TTL saves another 8. Since the TTL is now ordered, we can deterministically and proactively expire items. Which should reduce steady state memory overhead.
Another perhaps downside is that we lose refcounting for independent objects, which is used very frequently for strings on argument vector. It might be time to try to be more efficient here anyways, and just have a refcountable string object.
Other ongoing efforts
- https://github.com/redis/redis/pull/9464
- https://github.com/redis/redis/pull/8700
Comment From: romange
@madolson good ideas. I hope it's ok if I chip in? I chose for my implementation an open addressing scheme with small object optimization as you suggested here. Since it's in C++, has dependencies on other components (not self-contained) - I do not think its code can practically help Redis maintainers with this task.
However, if you decide to pursue the direction "Promote the Redis object to be the dictEntry, saving a pointer. (Saves 8 bytes)" , I wrote the following data-structure https://github.com/dragonflydb/dragonfly/blob/ExpSet/src/core/string_set.h that is much simpler than DashTable. It resembles redis-dict (chained linking), and it saves more than 8 bytes per object.
it can easily be extracted into a self-contained class and converted to c. if it can help you I will gladly release its code under BSD license.
Comment From: moticless
@romange , I don't see how redis 32 bit can reuse of the higher bits as you suggested and I am not sure if we wanna have different implementation to 32 bits. Alternatively, maybe we can guarantee alignment level of dictEntry (and its derivatives) and gain at least 3 unused bits. This way we can use, for example, to mark with 1 bit wether it is the last item in the chain (and avoid the next pointer), and with the other bit(s) to mark an inline key in dictEntry.
IMHO, as we are talking about few optimizations, each one should be profiled on its own.
Comment From: romange
@moticless yeah, you are right - I forgot that Redis is required to support 32bit. Re alignment - it won't work if you want to use sds as keys, because it's unaligned :(
Comment From: moticless
I didn't think about the it throughly but we will need to enforce 4bytes alignment all our dictEntry types. Then again, another option is to optimize it only for 64bits and reuse high bits of the address.
Comment From: madolson
@romange <3 You're always welcome to chip in! If there are places we can improve Redis and better align DragonflyDB with our code for maintainability, that seems like everyone is better off.
AFAIK I know the SDS is still always aligned to start at an 8 byte address, unless it's being embedded somewhere. The Dictentry pointer should always be 8 byte aligned. There are definitely plenty of places we can harvest the 3 bits if we want to.
I don't mind splitting the 32bit vs 64 implementations if it results in reclaiming some number of wasted bits from pointers.
Comment From: romange
sds is unaligned because of the header. I.e sds itself is not aligned, but we can indeed populate the real pointer (sds-1 or whatever it is). For 64bit it's easier to trust linux spec than a developer, hence my preference to high bits
I will put the set code into a dedicated repo some time next week. It works, though it's not polished. Unfortunately, I wont have time to transform it to a proper adt for redis but if someone will take this task, i will be available to help.
Comment From: romange
I put string_set here: https://github.com/romange/midi-redis/tree/main/string_set. hopefully, you will find it useful. It even has unit-tests.
Comment From: madolson
@romange Awesome!
Someone from AWS is going to pick this up shortly, so tentatively assigning it to myself. If other folks from the community are interested please follow up, this is definitely going to be a bigger effort.
Comment From: vitarb
Hey folks, I've done some research on this topic, and wanted to share my findings with you all. At the high level there are 3 ways to improve main dictionary memory consumption: - Keep existing data structure layout, but reduce overhead, that is primarily used for pointers and TTL metadata. - Change data structure design and normalize common data at the top level, while packing key/value data in larger segments. - Use compression for data that isn't accessed frequently.
Now, I don't think it is possible to significantly change data structure design without certain trade-offs. There are some great ideas that can improve performance in certain situations, like for example SegCache that introduces bulk expiration for cache oriented use case where all data has TTL, but it will have some edge cases that may work worse than in the existing system. (such as frequent updates to the entry's value in case of SegCache) Compression, while interesting, won't also be a universal solution and may degrade performance for certain users. This is why I've mostly focused on the first area, namely finding ways to improve existing chained hash table.
There are a few sources of the overhead in the current data layout, that Madelyn pointed out above. 1. Values stored in the redis object are double-referenced, which means 16 wasted bytes of space. 2. Keys are referenced, which wastes another 8 bytes on pointer. 3. Next record pointer in the entry chain is NULL for most records with normal load factor, while using another 8 bytes. 4. TTL data requires a separate entry, wasting another 32 bytes.
Instead of using existing sparse layout where all data is referenced, we could have a dictionary entry contain data array of variable length (similarly to how radix tree does it) with data embedded into this array (or referenced in case if it exceeds certain size).
Possible dictEntry layout could be:
typedef struct {
// All below metadata fields before data array add up to 4 bytes
// (1b for flags + 1b for key size + 2b for val size).
uint32_t is_key_ref:1; // is key a reference or embedded as a byte array.
uint32_t has_val:1; // can be used in sets to allocate 0 bytes for value.
uint32_t is_val_ref:1; // is val a reference or embedded as a byte array.
uint32_t is_val_primitive:1; // is val a primitive or a redis object.
uint32_t has_next:1; // indicates if there is a pointer to the next entry.
uint32_t unused:2; // reserved for future use.
uint32_t key_len:8; // length of key [0..256).
uint32_t val_len:16; // length of val [0..64k).
unsigned char data[];
}
In this case we drastically reduce overhead for small records, at the cost of having dictEntry being of variable length and having to alloc/realloc when something changes.
Another, perhaps debatable, idea is to embed TTL data into primary redis entry. This can be configurable, but if enabled it can save another 32 bytes per entry with TTL, at the cost of making proactive expiration less efficient. It might be a good trade-off for users that use TTL extensively, as if all records have TTL then there will be no penalty at all in expiration efficiency, only savings in terms of space usage.
We may also consider more trimmed down version of this approach that only embeds keys or values under certain circumstances, but it will provide less savings at the end.
Main challenge that I see with this proposal is that in order to make it efficient, we need to know entry size at the creation time, and existing code creates entry without value and lets caller populate it later. Similarly TTL is assigned as a separate API call. This approach may need to change, otherwise each entry would need to realloc when the value or TTL is set (in case if we do embed TTL).
I welcome your thoughts and feedback on this. I'm also curious to hear what you folks think about following this route versus designing a completely new data structure with a different set of tradeoffs and performance characteristics (perhaps more cache/TTL oriented).
Comment From: GuoZhaoran
@madolson Great dictionary architecture improvement design! but it seems that it still needs some coding and testing discussions to fully implement them. Is it feasible to use variable length arrays to implement the "Use an open addressing scheme" scheme? If so, the changes to dictEntry are as follows:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry[] next; /* Replace the pointer to the next dictEntry */
//struct dictEntry *next; /* Next entry in the same hash bucket. */
/*void *metadata[]; An arbitrary number of bytes (starting at a
* pointer-aligned address) of size as returned
* by dictType's dictEntryMetadataBytes(). */
} dictEntry;
In addition to saving 8 bytes, it also speeds up search and traversal due to local access.
As you analyzed, if there is a hash conflict when updating the dictionary, we will have to create and construct a new dictEntry array through the realloc/malloc function, but this change is only in dict The c and dict. h files are internally modified. I really want to do some coding, try and do some tests to verify the feasibility of this scheme.
You want to promote the Redis object to be the dictEntry. I think it is very beneficial and should be like this in the end. Do you think it is necessary for me to try to transform the dictEntry?
Comment From: vitarb
Hey folks, I've decided to build a prototype and tried to limit the scope as much as possible, working only on embedding keys into data array. Here is what I've learned so far:
* Dict keys can be of different types (sds, C*, robj), it's not enough to just memcpy what key points to into the buffer, but instead we also need to know what type of the object it is (like in case of sds where len and flags are prepended before the key pointer). At the dict level we don't have that information. We also need to know object type in order to properly reconstruct it when get is called.
* Copy on write is necessary, copy on read can (and should) be avoided - current solution stores pointer to the key, if we want to embed the key, we would need to copy bytes (the only alternative is to realloc key itself into data array, but then it can't be a variable length array in the entry struct) and would require a separate pointer. On read however, we want to return a pointer to the data array in order to reduce impact on performance.
* Dict entry is used outside of the dict - this may or may not be a problem, depending on whether or not we require dictType to be available as part of the dictGetKey call. Passing dictType will only be needed if we'll want to do copy on read and have custom deserialization (or decompression) logic. In the most simple case, we should be able to get away with just providing a pointer to the data array. (sds will be a special case)
* Entry metadata field is a variable length array - since two arrays of this type can't co-exist in the struct, it needs either be eliminated or also encoded into data array. Metadata is used to iterate keys in slot for CME, one way to achieve similar functionality without saving extra data inside of the entry is to partition dictionary by slot id. This should be discussed separately.
* Mutable access to the key - in some places (in hash for example) we have calls like sdsfree(dictGetKey(de));, this will be a problem since we can't free bytes inside of the data array. We may need to consider providing separate functions at the entry level, or use a different entry type that will be based on pointers.
In order to implement copy on write for different types, I recommend adding necessary functions into dictType, that would provide length of the key and will know how to write it into the buffer. Something along the lines of:
typedef struct dictType {
...
// Returns key length in bytes, that are guaranteed to be available in the buffer passed to keyToBytes.
size_t (*keyLen)(const void *key);
// Writes key into provided byte array and returns number of bytes written.
void (*keyToBytes)(unsigned char *buf, const void *key);
} dictType;
Then we can simply have different implementation of these functions for sds, C* and robj. Alternative is to somehow push through all necessary metadata to the dict level, but I find that unfeasible as it would create unnecessary complexity in the dict itself making it highly coupled with the representation of the object.
My next goal is to finish the prototype and see how much copy on write impacts performance as well as see if there are other challenges that I haven't discovered yet. Any feedback is welcome.
Comment From: zuiderkwast
Here is a refactoring PR that makes the dictEntry struct opaque: #11465. Hopefully it makes experimenting with the dict entry representation easier. (Encoding has-next in a bit in a pointer, embedding the key inside the dictEntry, etc.)
Another completely different idea is to replace the chain of dictEntry with a listpack. It would allow storing multiple keys and values in a compact way.
Comment From: zuiderkwast
@vitarb Thanks for the link to the paper about SegCache! It has some very interesting points, mainly these:
- putting multiple keys with similar TTL into segments (similar to what @madolson's idea with TTL-rax with segments IIUC; a very good idea it seems) and
- hashtable with bulk-chaining; instead of a next-pointer on each entry, they bake up to 8 entries together in one allocation.
I think bulk-chaining can be done in our dict, separately from other features. We get rid of the next pointer in most cases and we avoid cache misses. (Pre-conditions: (1) Make dictEntry opaque and (2) get rid of dictEntry metadata.)