High level design
We want to introduce a new Slot Migration process that atomically migrates a set of slots from a source node to a target node.
We will implement a net new slot serialization strategy which emulates the behavior of BGSave but sends a series of RESTORE COMMANDS instead of the RDB snapshot serialization format. The strategy being that we fork when migrating a batch of slots, we establish the new connection, and then iterate over the slot space and sent the restore commands. Once all the data for a slot is migrated, the accumulated buffer for the slot is drained. Once the buffer is drained, we block all write commands for the slot while we do a coordinated handoff, this can be upgraded to 2PC for cluster v2, to complete the transaction and make sure the target node takes ownership of the slot. Once the target has confirmed it owns the slot, the source node will asynchronously purge its slot data. This process will be repeated for all slots being migrated, one at a time. The forked process will be used to migrate a set of slots, once this set of slots has been migrated, the fork process ends.
On the source node there will be a cron job that will drive a state machine which will execute the different phases of the slot migration process. If an individual migration fails, it will be rolled back and the process will be aborted. Slot migrations can therefor partially succeed, with some slots owned by the target and some owned by the source.
Benefits from this new implementation compared to the current one:
- Atomic slot migration - no splitting of slots.
- Multi-key operations are seamless while a slot migration is ongoing
- No extra hop for client requests
- Easy to recover from failures
New commands
CLUSTER MIGRATESLOTS [NODE <Target node ID>] [SHARD <Target shard ID>] SLOTRANGES start end [start end]
Initiate a slot migration between a source and target node. Optionally supports a “shard ID” that can be used instead of a specific node. If a migration failed, it will not be automatically retried. It will be up to the caller to determine the migration has failed and to restart the process.
CLUSTER IMPORTSLOT START <slot> <Source node ID>
Control command sent between a source and target node to indicate that this link will be used to transfer the ownership of a slot.
CLUSTER IMPORTSLOT END <slot> <source-node-id> [<expected-keys-in-slot>]
Control function to indicate that the transfer has completed and the node should now take ownership of the data. Upon receiving this signal, the target will take ownership of the slot and broadcast to all nodes the new epoch.
New Info fields
slot_migration_role: [source|target]
if role == source
slot_migration_migrating_slots:
slot_migration_state:[see below]
slot_migration_start_time:
slot_migration_keys_processed:N
slot_migration_keys_total:N
slot_migration_perc:X%
slot_migration_last_duration_ms:
slot_migration_last_status:
slot_migration_last_failure_reason:
if role == target
slot_migration_importing_slots:
slot_migration_keys_processed:N
Major components
Slot migration state machine/SlotMigrationCron (slotmigration.c)
A new cron job will be introduced that runs every iteration of the clusterCron as long as a slot migration is running. It will be responsible for driving the state machine of an ongoing slot migrations (on the source node) forward.
These are the different states:
WAIT_TARGET_CONNECTION_SETUP: Established connection with the target node. Sends the CLUSTER IMPORTSLOT START ... to the target node. Process is forked.
SM_SRC_START: The request to migrate a slot has started. Start the actual slot migration tsk.
SM_SRC_FULL_SYNC_IN_PROGRESS: The migration is moved into this state when the fork has triggered and is now streaming data to the target. Once this process is complete, the fork will signal its parent process to begin transferring the accumulated output buffer.
SM_SRC_OUTPUT_TRANSFER_IN_PROGRESS: The full sync has completed. At this point, the primary is draining the client output buffer accumulated during the fork for that slot.
SM_SRC_WAIT_ACK: Once this process is complete, the primary will initiate the committing of the slot by sending CLUSTER MIGRATESLOT END . At the beginning of this state, we will start blocking all writes to the slot being migrated. In this state, we are waiting for the acknowledgement from the target that it took ownership of the slot. This is done by the target publishing a cluster bus gossip message stating that is has ownership of the slot with a higher epoch number. The source receiving such message would indicate the target has successfully claimed the slot. Once the acknowledgement is received, we will commit the slot transfer and begin to purge the data in our slots. The source node does not own the slot anymore.
SM_SRC_CLEANUP: Final state where the migration was either successful, cancelled or failed. Clean up the slot migration states and close the connection to the target.
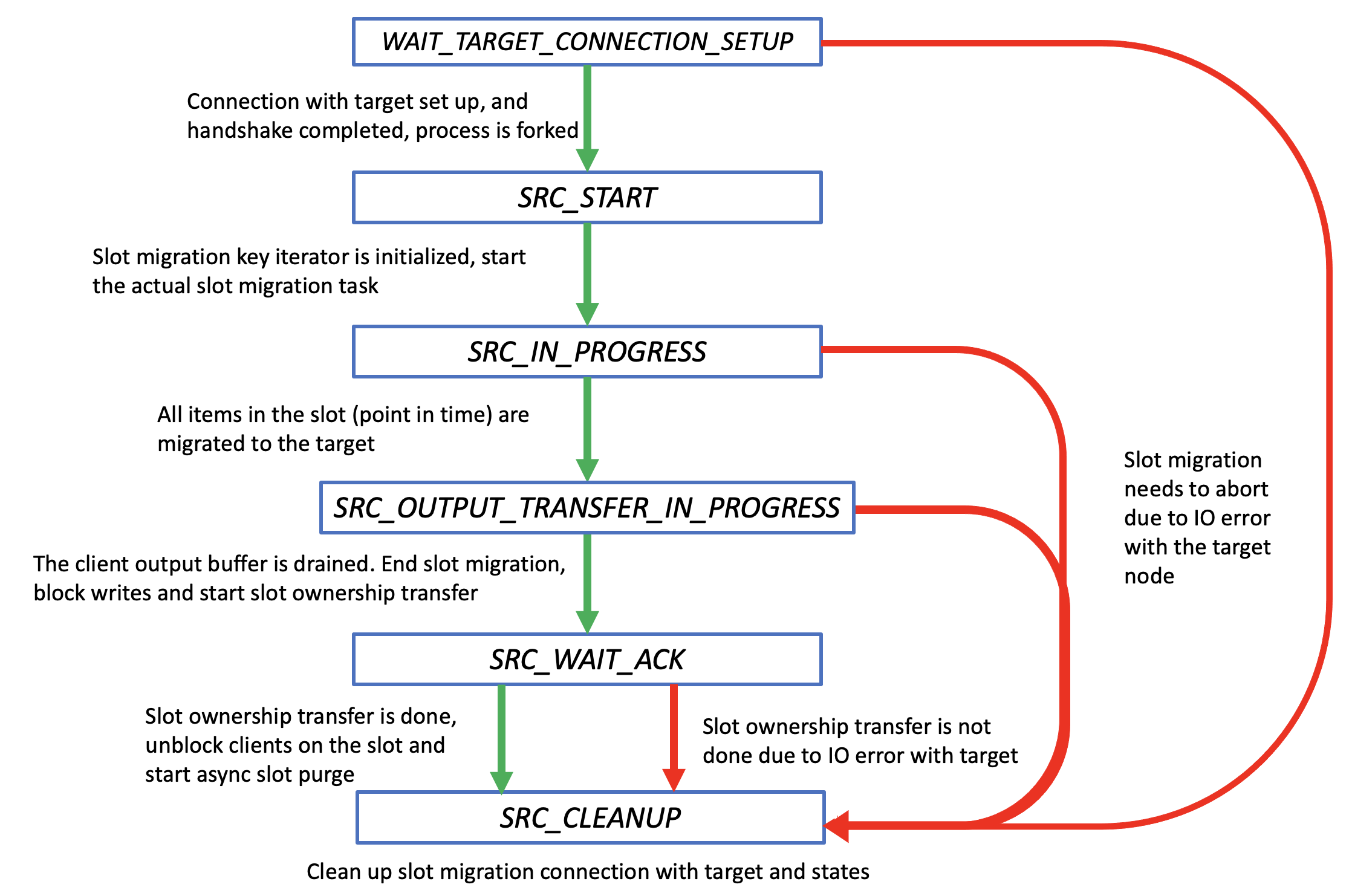
The states SRC_START through SRC_WAIT_ACK will be repeated for every slot that is being migrated. So there will be one connection for all of the slots being migrated. There will be one fork per batch of slots being migrated.
From the point of view of the target node the following happens:
- Receive CLUSTER IMPORTSLOT START
from the source node: start of the migration of a slot is replicated to its replicas then acknowledged. We are now expecting to get slot data from this link. The node processes the incoming commands from the source node to load the data into the slot, and relays the incoming slot data to its replicas. - Receive CLUSTER IMPORTSLOT END
from the source node: propagate the end of the slot migration to its replicas then acknowledges the end of the import slot. At this point the target node now owns the slot and can start serving traffic for it. A primary will synchronously replicate the CLUSTER MIGRATESLOT ENDto its replica, waiting for the acknowledgment, this will prevent the replica from needing to reconcile having data without knowing the state of the mgration.
Fork based slot migration full transfer (slotmigration_sync.c)
At the start of the slot migration, a client will be created on the source node and connect to the target node. This will be re-used from the migrate command code. At this point, a system fork will be executed, which will be used to send the point in time transfer of the data in the slot. The data transfer will occur on the main thread, with a named pipe being used to transfer the data from the child to the parent. This is link is used to enable TLS to be used, since a FD can not be shared between two processes since the internal TLS state will diverge. The process will periodically send information about the progress of the migration.
Once the full sync is completed, the fork will send a status message to the parent process using a pipe to signal that it has finished. If the status code was success, the primary will then begin transferring the queued up replication on the relevant slots. All incoming write traffic will be checked for which slot it is being accessed. If the slot being accessed is one of the slots currently being migrated, during propagation it will be queued on a dedicated buffer for the migration. Although the buffers could be kept independent for each slot, they will be grouped together in this implementation for simplicity.
Once this queue has been completely drained, a special “client pause” will be started on the slots being migrated, which will block all writes against those slots. This pause will remain in effect while a coordinated handoff is sent committing the ownership on the target.
If at any point in time, the connection between the source and target is killed, the migration will be aborted on both ends.
We will be forking once per batch of slots to be migrated, and serially sending the content of each slots in the batch. We believe there is an implicit tradeoff here between CoB usage, CoW usage, and time it takes to pause. We will optimize the number of slots in a batch to be migrated in a single fork based on performance testing. We think there will be some sweet spot for the number of slots to migrate per fork.
Async slot flush (slotflush.c)
A new state will be introduced for the slot state, which is slot flush. A slot that is flushing has data but is unreachable because the node does not own the slot anymore. A node will be unable to “import” data on this slot until the data has been fully flushed. The flush will happen in a new cron job which will be triggered at the end of the SM_SRC_WAIT_ACK state. Since the flush of a slot will happen asynchronously, we can start migrating the next slot while flushing of a slot is still happening. If flushing a slot takes longer than migrating the next slot, then the next slot to be flushed is queued up and flushed once the previous slots have been completely flushed.
This might also benefit from the investigation done here: https://github.com/redis/redis/issues/10589. Having a dictionary per slot would make it very easy to “unlink” the entire dictionary, but will require more investigation.
Failure modes
Source or target node dies during transfer: In this failure mode, the migration will be aborted once some pre-defined timeouts are reached. Once a target realizes that the migration target has been disconnected, it will initiate a slot flush of its data. Once a source realizes the target is dead, it will rollback the migration process.
Target primary dies during handoff: If the target primary dies after sending the CLUSTER IMPORT END and committing it to replicas. The newly promoted replica will be able to acknowledge slot ownership, completing the handoff. If no replica is there to acknowledge it, the slot will be lost with the remaining slots on that node.
Target never acknowledges handoff: If we have sent CLUSTER IMPORT END but never received acknowledgment that it was applied. In this event, we will wait for CLUSTER_NODE_TIMEOUT, at which point we will unblock the writes against the source. If the target is still alive, it will still be able to take over ownership of the slot via clusterbus message with a higher epoch of it owning the slot. This is consistent with OSS Redis behavior, which allows inconsistent writes within nodes that aren’t talking to each other. Note about clusterv2, the 2PC will be directed towards the topology director instead of the target node.
Target rejects a command: Any error received during the migration will result in a failure of the migration. Typical failures would be ‘incorrect acls’ or ‘OOM’.
Notes about cluster v2
The same general strategy will apply. The only difference is that the handoff will be a 2PC facilitated through the FC/TD instead of just between the source and target.
Open questions
- Should we include the Slot Migration client output buffer size as a new metric? Should we treat the target client as a replica client?
Comment updates
- [ ] Update to do a single fork per batch of slots.
Comment From: oranagra
Very nice. I think I'm missing some chapter about replicas of the source and target.
Comment From: PingXie
`CLUSTER MIGRATESLOTS [NODE
] [SHARD ] '
Can we add the slot range syntax sugar similar to ADDSLOTSRANGE for consistency?
How do you plan to support auth? Are you thinking about the MIGRATE model where the client provides clear text auth on the command?
Fork-based migration protocol
The proposed migration protocol makes sense to me.
2PC
On the surface it sounds like target replicas don't participate 2PC and they seem to serve as a "volatile" WAL. Are the slot ownership asynchronously replicated to the (target) replicas? If yes, even with an HA setup, depending on the replica that wins the election, the slot could still be lost just like the non-HA case. Then in the source post-migration failure case, we seem to still fall back on the epoch, which I assume is bumped on the target without consensus as well? In general, I am not sure what additional value 2PC provides without a real WAL. Maybe I am missing details.
Comment From: zuiderkwast
I think the target needs to synchronously propagate CLUSTER IMPORTSLOT END to replicas and write it to AOF/RDB before taking ownership by bumping the epoch. Is it enough though? Will this lead to other problems? @PingXie WDYT?
Comment From: judeng
this is a very mature and exciting proposal. only have one minor suggestion.
We will implement a net new slot serialization strategy which emulates the behavior of BGSave but sends a series of RESTORE COMMANDS instead of the RDB snapshot serialization format.
I think the restore command is designed for the old version scheme to realize the atomic migration of keys. When migrating large keys, especially the zset keys, restore comand often make the target to be hung for a long time, maybe causing the slot migration to fail. According to your proposal, in the source fork process, we can give up the use of the restore command, we could transmit many small commands, just like the output of bgaofrewrite.
Comment From: PingXie
@zuiderkwast I think you are essentially suggesting 2PC in the target shard as well, either hanging off of the 2PC between source and target primaries or part of the same 2PC between source and target primaries. The source replicas if any should also participate in the same 2PC BTW; otherwise the agreement reached by the source primary and the target shard could be nullified if both source and target primaries failed. Then I think this should work in theory but still there are details to work out too. For instance, how do we determine the new 2PC coordinator if the original one died? In the textbook 2PC, we would like to stick to the same coordinator after the failure. Need to think it though what it means if we change the coordinator midway a transaction.
Another concern I have is w.r.t. the dependency on any sort of persistence. What do we do for the deployment without non-volatile storage access?
The fork requirement is not ideal but is acceptable IMO, if there is an incremental path forward, which isn't clear to me at the moment. If we ended up not reusing any fork-based pieces, the tech debt is real.
Among the key benefits called out
- simplicity - only one command is needed per-slot; no more coding required on the admin side
- transparency - no more dealing with moved/asking on the client app side; multi-key commands no longer need retries during migration
- strong consistency - via 2PC
I can totally see 1) happening; I think 2) is undoubtedly a good trait, if it can be delivered without fork. With fork, we are trading the long-lived but smaller (additional n/w hops) impact on a few keys (in the slot being migrated) with the short-lived but bigger impact (frozen) on all keys; I am looking forward to more details on 3). So far my understanding is that unless we go 2PC all the way, it is hard to say the consistency bar would be raised significantly, compared to what we have today.
Comment From: hwware
I have several questions for this design:
-
As @PingXie comment, if the command CLUSTER MIGRATESLOTS [NODE
] [SHARD could support multiply slot ranges, such as CLUSTER MIGRATESLOTS [NODE] ] [SHARD ] -
It is mentioned that All of these states will be repeated for every slot that is being migrated. So there will be one fork and one connection to the target node for each migrating slot. I am not sure how much cost of every fork and how many performance difference between these 2 ways , if we could only fork once and migration multiply slots?
-
In the old design, if we want to do one slot migration, we need run the command on source node and target node client sisde. Can we add the feature that allow client to run all the migration commands on any node client side, including non-target node and non-source node?
-
In the design, it says that If an individual migration fails, it will be rolled back and the process will be aborted. My question is when we migrate multily slots, if one slot fail, only this slot process abort and continue migtating other slots OR other slot migration process will be termiated as well?
Thanks
Comment From: madolson
@zuiderkwast There is some value in replicating the import slot synchronously on the target. I think the most interesting example is as follows (Assume 2 primaries and two replicas across two shards (A and B), where A is migrating to B)
* Primary A is transferring data to Primary B, all the data is already staged on B.
* Primary A sends the IMPORT SLOT END. There isn't really a reason to replicate anything to replica B at this time.
* Primary B receives the end, and replicates it to its own replica. I think this should be done in either case. There are two sub-cases:
* * If it's done async, there is a case where replica B never learns that primary B completed the transaction that is interesting. In this case, it's possible that primary B did acknowledge to primary A that migration completed. At this point, the slot is lost, since replica B will take over without any data. This is easy to mitigate though, as we can detect that replica B has staged data and nobody owns the data.
* * In the synchronous case, the previous failure mode can be mitigated since we explicitly replicate the IMPORT END command before responding. However, we still run into the special case of the primary B failing, and the replica B needing to take special action.
I don't think it changes the overall correctness, but if it's easier to reason about I don't have much of a strong opinion.
On the surface it sounds like target replicas don't participate 2PC and they seem to serve as a "volatile" WAL.
For what it is worth, it's still a 2PC without a persistent WAL, it just adds failure modes. At AWS we just reconcile the system after it has failed catastrophically (Read everything has died). A single AOF disk is something we should probably think about more, which is not a mode we support internally. Replicas + AOF already don't play well together.
In the old design, if we want to do one slot migration, we need run the command on source node and target node client sisde. Can we add the feature that allow client to run all the migration commands on any node client side, including non-target node and non-source node?
Will ask this be a separate feature probably, since in a way it's kind of like a proxy of commands to the right node. Which I think is useful in many other circumstances.
In the design, it says that If an individual migration fails, it will be rolled back and the process will be aborted. My question is when we migrate multily slots, if one slot fail, only this slot process abort and continue migtating other slots OR other slot migration process will be termiated as well?
Currently it will not rollback the slots that have been successfully migrated.
Comment From: zuiderkwast
@madolson
If it's done async, there is a case where replica B never learns that primary B completed the transaction that is interesting. In this case, it's possible that primary B did acknowledge to primary A that migration completed. At this point, the slot is lost, since replica B will take over without any data. This is easy to mitigate though, as we can detect that replica B has staged data and nobody owns the data.
I'm fine with such mitigation. It reminds me of redis-cli --cluster fix.
In the synchronous case, the previous failure mode can be mitigated since we explicitly replicate the IMPORT END command before responding. However, we still run into the special case of the primary B failing, and the replica B needing to take special action.
You mean primary B failing before the slot is fully migrated? The migration is rollbacked and the only thing replica B needs to do is to flush the slot, right? (or do we want to continue the migration after failover?)
What about primary A and primary B failing at the same time? Will the mitigation (replica B detects that the slot has no owner) work for this case too?
Comment From: ushachar
The strategy being that we fork when migrating a slot, we establish the new connection, and then iterate over the slot space and sent the restore commands. Once all the data for the slot is migrated, the fork ends and the accumulated buffer for the slot is drained.
During the discussions about this, we said we will also offer a forkless option for people running in a very resource constrained environment (these deployments will lose write availability for the duration of the data migration).
These are the different states: WAIT_TARGET_CONNECTION_SETUP: Established connection with the target node. Sends the CLUSTER IMPORTSLOT START ... to the target node.
I suggest preserving the current behavior of gossiping the intermediate state (marking slot X as being imported/migrated in the relevant shards) as it would make it easier for an admin to understand the current cluster state / see when rollback happens. This could be done automatically by the source and doesn't need to have an actual effect on the source/target.
SM_SRC_WAIT_ACK: Once this process is complete, the primary will initiate the second part of the 2PC by sending a CLUSTER MIGRATESLOT END ... . In this state, we are waiting for the acknowledgement from the target that it took ownership of the slot. This is done by the target publishing a cluster bus gossip message stating that is has ownership of the slot with a higher epoch number. The source receiving such message would indicate the target has successfully claimed the slot. At this point we are blocking all write requests against this slot.
The source should block writes to the slot before sending '''CLUSTER MIGRATESLOT END''', and not after receiving the acknowledgment from the target. Otherwise new writes would be lost.
All of these states will be repeated for every slot that is being migrated. So there will be one fork and one connection to the target node for each migrating slot.
This means that we will have 8K forks (not concurrent, but still...) happening when scaling up from one shard / whenever we multiply the number of shards. I know you suggest a potential improvement later in the game, but can we live with this in the first drop?
At the start of the slot migration, a client will be created on the source node and connect to the target node. This will be re-used from the migrate command code. At this point, a system fork will be executed, which will be used to send the point in time transfer of the data in the slot. The data transfer will occur on the main thread, with a named pipe being used to transfer the data from the child to the parent. This is link is used to enable TLS to be used, since a FD can not be shared between two processes since the internal TLS state will diverge. The process will periodically send information about the progress of the migration.
Why not just open the client conn in the child process? Worst case we'll incur the cost of forking and immediately exiting if unable to connect (and - under the assumption that the majority of the data is in the initial full sync - we benefit from less interruption to the primary in the happy path).
If at any point in time, the connection between the source and target is killed, the migration will be aborted on both ends.
Technically we can reconnect and continue in cases of connection failures that are not the result of process failure (verified by comparing runid). This could be a potential future enhancement since it will require a more complicated state handling.
This might also benefit from the investigation done here: #10589. Having a dictionary per slot would make it very easy to “unlink” the entire dictionary, but will require more investigation.
Going in this route would also open up the option of dedicated memory arena per slot(s) -- which will place a much tighter bound on the CoW overhead generated by slot migration.
Source or target node dies during transfer: In this failure mode, the migration will be aborted once some pre-defined timeouts are reached.
Once one of the sides decides on a timeout it must drop the connection ASAP as a signal to the other.
Target primary dies during 2PC: If the target primary dies after sending the CLUSTER IMPORT END and committing it to replicas. The newly promoted replica will be able to acknowledge slot ownership, completing the 2PC. If no replica is there to acknowledge it, the slot will be lost with the remaining slots on that node.
Doesn't the target primary receive the CLUSTER IMPORT END? How will the newly promoted replica be able to ack the slot ownership & complete 2PC? Shouldn't this case have the same end result as Target never acknowledges 2PC ?
As a nitpick, I think the using the term 2PC here is a distraction - we don't have a coordinator and there are only two entities which reach agreement.
Comment From: zuiderkwast
The strategy being that we fork when migrating a slot, we establish the new connection, and then iterate over the slot space and sent the restore commands. Once all the data for the slot is migrated, the fork ends and the accumulated buffer for the slot is drained.
During the discussions about this, we said we will also offer a forkless option for people running in a very resource constrained environment (these deployments will lose write availability for the duration of the data migration).
I still don't understand why we don't implement the simpler thread approach instead: Let a thread on the source node handle the transfer of data to the target. For each key, it asks the main thread (over a named pipe) to serialize it. Pros: No CoW, no losing write ability. The only downside is that it blocks the source node for the duration of serializing one key, but that's no worth than what we do on the target node, namely execute the RESTORE command which blocks the target for the duration of restoring the key. The thread can keep the pipeline to the target busy by serializing a few keys in advance, so I can't see that it should be any slower than the fork either.
What am I missing?
Comment From: ushachar
The strategy being that we fork when migrating a slot, we establish the new connection, and then iterate over the slot space and sent the restore commands. Once all the data for the slot is migrated, the fork ends and the accumulated buffer for the slot is drained.
During the discussions about this, we said we will also offer a forkless option for people running in a very resource constrained environment (these deployments will lose write availability for the duration of the data migration).
I still don't understand why we don't implement the simpler thread approach instead
@zuiderkwast As I understand it, the goal here is to provide an atomic transfer of the slot (and avoid the current intermediate state which requires ASK/ASKING). Serializing per key while locking the entire slot will create a very long write outage.
Comment From: zuiderkwast
@ushachar Then you misunderstand me. The idea is that the thread does exactly what the fork would do, apart from asking the main thread for each key. When a key has been serialized, it is marked so that further writes are accumulated and transferred later. Everything else can work as with the fork, except that the work is done in a thread instead. I hope I am more clear this time.
Edit: We'd need a structure to remember which keys have already been serialized, so we accumulate writes for them. (I forgot to mention but it's implied.)
Comment From: PingXie
Right, the one benefit with this proposal (in its current "forking" form) is that clients no longer need to deal with redirection during the slot migration. Design wise, the cluster is not more resilient to failovers during the migration, compared to the existing migration flow. Implementation wise, we will need at least the single fork to make the migration impact (close to?) acceptable in the real world.
I am not sure serializing per key will create a very long write outage, only for the case where an excessively large key/value is encountered. In fact, I was able to serialize multiple keys for migration in my solution while seeing <2 ms of delay. I do have a plan to break the migration logic out of the main thread such that the impact will be limited to the slot being migrated, as opposed to all slots on the same node. Until we can achieve forkless for this design, I would say, we are essentially trading few long-pauses (due to fork) with many small delays.
Comment From: oranagra
During the discussions about this, we said we will also offer a forkless option for people running in a very resource constrained environment (these deployments will lose write availability for the duration of the data migration).
why bother? if we're willing to pause writes, we can keep the single fork-based approach and the COW will be negligible. not sur e the overhead of maintaining two modes is worth it.
Going in this route would also open up the option of dedicated memory arena per slot(s) -- which will place a much tighter bound on the CoW overhead generated by slot migration.
playing with arena selection scares me. there are many ways we can plan this (e.g. separate actual data from infra buffers for easier counting, or faster flushing), but i think there are many ways this can go wrong (specifically with modules), and we also can't count on it since not all allocators support it.
I still don't understand why we don't implement the simpler thread approach instead: Let a thread on the source node handle the transfer of data to the target. For each key, it asks the main thread (over a named pipe) to serialize it. Pros: No CoW, no losing write ability. The only downside is that it blocks the source node for the duration of serializing one key, but that's no worth than what we do on the target node, namely execute the RESTORE command which blocks the target for the duration of restoring the key.
I think forkless (user space COW cloning, or on demand serialization) is a dead end, in some cases with extremely large compound keys, a user space COW or on demand serialization (if done from the same thread that serves traffic) will freeze the traffic for very long. The fact that we suffer from that on the target (processing a large RESTORE from the main thread), is not a reason to screw up the source too. what we need to do is resolve the problem on the target (both long freeze and also memory overhead of keeping both the serialized and deserialized forms at the same time). we do have a long term plan for non-blocking DUMP and RESTORE, by using RESP3 chunked format and threaded / background execution of these (processing the data while also streaming it rather than caching it), this will require key-locking, maybe we'll get to it in redis 8.0.
Comment From: zuiderkwast
Thanks for the clarification Oran.
If we get key locking and multi threading for the key space, we solve the freeze issues on both source and target. Then, why fork? Perhaps it's too far in the future...
Comment From: oranagra
maybe i'm missing something, but doesn't the fork approach allows modifying a key while serializing it and keeping the modification the replication buffer (like master->replica full sync)? i.e. we serialize a huge ZSET key (or actually a complete hash slot), but also allow ZINCRBY on some field during that time.
also, i think it makes things simpler and allows for this improvement to be done before the async dump and restore is implemented.
Comment From: zuiderkwast
After the fork, the main thread needs to accumulate writes that are transferred later. Sure it's simpler that it can accumulate all writes to the slot after forking. It doesn't need to keep track of which keys have already been serialized, which would be needed with the thread approach.
Comment From: madolson
@zuiderkwast I don't really want to block progress here on a potential future implementation that doesn't fork. There are a lot of other problems that need to be resolved before we can solve, and I think solving it for replication also needs to be done. So I think we can tackle them together in the future. As Oran also called out, we need async dump + restore as well.
I think we want to trend towards the world where we incrementally iterate through keys, block them on the main thread, and serialize them in a background thread. A lot of the problems are documented here, https://github.com/redis/redis/issues/7372#issuecomment-640956204, and some of the work is being done here https://github.com/redis/redis/pull/11012.
Comment From: madolson
As a nitpick, I think the using the term 2PC here is a distraction - we don't have a coordinator and there are only two entities which reach agreement.
That's a fair comment. One of the reasons I used it specifically is because in the cluster v2 world it should be a 2PC that coordinates with the TD. The commit we execute today is very weak and prone to failure, for cluster v2 and alternative consistency mode it will need to be a stronger handoff. But I will clarify it.
Comment From: madolson
I suggest preserving the current behavior of gossiping the intermediate state (marking slot X as being imported/migrated in the relevant shards) as it would make it easier for an admin to understand the current cluster state / see when rollback happens. This could be done automatically by the source and doesn't need to have an actual effect on the source/target.
This is an interesting question. We will have an info field for the ongoing migration which can be discovered. We don't need the migration in the nodes.conf file for any reason, since on failures it will rollback and the admin is expected to re-initiate it. In the cluster v2 case, we would be expecting the slot migrations to be started by the engine as long as the desired state is not the same as the current topology. So I don't think we need to expose it anywhere.
Comment From: pieturin
Note: There will be one COB per slot being migrated. For every incoming write command we will store it in the corresponding COB depending on which slot it writes to. In the SM_SRC_OUTPUT_TRANSFER_IN_PROGRESS state we will flush the corresponding COB for the slot being migrated.
@ushachar
Why not just open the client conn in the child process? Worst case we'll incur the cost of forking and immediately exiting if unable to connect (and - under the assumption that the majority of the data is in the initial full sync - we benefit from less interruption to the primary in the happy path).
The parent process is the one sending the data to the target. This is because of two reasons: - Once we finished sending the data of a slot from the "snapshot" taken by the child process, we then need to flush the COB of that slot to the target. The COB is going to be on the parent process. - When doing the final hand-off of the slot ownership with the target, the parent process will receive the acknowledgment that the target now owns the slot via an update to the epoch through cluster bus. - We cannot send the data from both the parent and the child because of the TLS connection state that needs to be updated and shared for the same connection.
We could change that and have the parent process stream the COB data to the child process. During the hand-off, the parent process could also notify the child process that the epoch has been updated. But we want to be more inline with the current behavior of BGSave, where we send the data to the replica from the parent process.
Also, I'm gonna be working on this project with @madolson in AWS.
Comment From: ushachar
* Once we finished sending the data of a slot from the "snapshot" taken by the child process, we then need to flush the COB of that slot to the target. The COB is going to be on the parent process.
Under the very reasonable assumption that the amount of data which exists in a given slot is >> the COB generated during the migration process, it might be worth it.
* When doing the final hand-off of the slot ownership with the target, the parent process will receive the acknowledgment that the target now owns the slot via an update to the epoch through cluster bus.
I agree it complicates the IPC between parent and child a bit, but not that much (since some IPC is needed anyways)
As an sidenote, depending on the underlying TLS implementation it is possible (thought complicated) to transfer TLS connections between processes.
Comment From: ushachar
I suggest preserving the current behavior of gossiping the intermediate state (marking slot X as being imported/migrated in the relevant shards) as it would make it easier for an admin to understand the current cluster state / see when rollback happens. This could be done automatically by the source and doesn't need to have an actual effect on the source/target.
This is an interesting question. We will have an info field for the ongoing migration which can be discovered. We don't need the migration in the nodes.conf file for any reason, since on failures it will rollback and the admin is expected to re-initiate it. In the cluster v2 case, we would be expecting the slot migrations to be started by the engine as long as the desired state is not the same as the current topology. So I don't think we need to expose it anywhere.
I'm not saying it's needed, but it would make admin lives a lot easier (and costs practically nothing since the mechanism for it already exists). Consider the case of having dozens of concurrent migrations happening in a large cluster - with a single CLUSTER SLOTS directed at any node I'll be able to see which slots are in progress.
Comment From: madolson
@ushachar maybe we want a new "admin health command". That gives a simple summary of important parts of the cluster. Adding it to slots or shards seems wrong, as they are datapath commands. There was a previous ask for this as well I sort of ignored.
Comment From: pieturin
I agree it complicates the IPC between parent and child a bit, but not that much (since some IPC is needed anyways)
@ushachar, would you be in favor of also changing BGSave to have the child process send the replication data instead of the parent proces? For Slot Migration I would rather keep the implementation as close as possible to BGSave to be able to re-use as much code as possible.
Comment From: ushachar
I agree it complicates the IPC between parent and child a bit, but not that much (since some IPC is needed anyways)
@ushachar, would you be in favor of also changing BGSave to have the child process send the replication data instead of the parent proces? For Slot Migration I would rather keep the implementation as close as possible to BGSave to be able to re-use as much code as possible.
That's a valid point, not sure what the considerations were behind the existing BGSave implementation (it might have a lot to do with the original - disk based - replication mechanism). @oranagra care to chime in on this?
Comment From: ushachar
@ushachar maybe we want a new "admin health command". That gives a simple summary of important parts of the cluster. Adding it to slots or shards seems wrong, as they are datapath commands. There was a previous ask for this as well I sort of ignored.
@madolson This information is already visible in the current SLOTS/SHARDS output, so keeping it there seems like the path of least resistance... but it's not a big issue either way
Comment From: madolson
@madolson This information is already visible in the current SLOTS/SHARDS output, so keeping it there seems like the path of least resistance... but it's not a big issue either way
I didn't follow this. Today ongoing slot migration is not present in SLOTS or SHARDS. It is present in CLUSTER NODEs.
Comment From: ushachar
@madolson This information is already visible in the current SLOTS/SHARDS output, so keeping it there seems like the path of least resistance... but it's not a big issue either way
I didn't follow this. Today ongoing slot migration is not present in SLOTS or SHARDS. It is present in CLUSTER NODEs.
@madolson right --- my mistake...
Comment From: madolson
We probably want to implement https://github.com/redis/redis/issues/11395 as part of this change as well.
Comment From: yossigo
@madolson Finally circled back to this one. I think the design is solid, and I agree we should focus on the fork option now. Some other comments:
The states SRC_START through SRC_WAIT_ACK will be repeated for every slot that is being migrated. So there will be one fork and one connection for all of the slots being migrated.
I think the implementation should be able to handle multiple slots per CLUSTER IMPORTSLOT START|END cycle from day one. Doing many iterations of forking, iterating the keyspace, and blocking clients while waiting for CLUSTER IMPORTSLOT END makes little sense.
We can start with a naive implementation and later figure out how to break down a N-slot migration request into batches. Even if we initially process one slot at a time, we'll have everything in place to improve that.
All incoming write traffic will be checked for which slot it is being accessed. If the slot being accessed is one of the slots currently being migrated, during propagation, it will be queued on a dedicated buffer for the migration
Minor comment: we'll need to consider implicit writes as well, e.g., stop active expire, etc.
Once a target realizes that the migration target has been disconnected, it will initiate a slot flush of its data.
It should probably also flush the slots on CLUSTER IMPORTSLOT START, since it may have some stale leftover keys from a previously failed import (e.g. started import, crashed, restarted and loaded from disk).
Should we include the Slot Migration client output buffer size as a new metric?
Yes, it's more similar to replica buffers because users may want to track it directly when slot migration fails.
Should we treat the target client as a replica client?
I guess the intention here is actually mark it as a replication master (CLIENT_MASTER), right? We should, so mustObeyClient() lets us skip normal client restrictions if they apply in rare cases.
Comment From: madolson
I think the implementation should be able to handle multiple slots per CLUSTER IMPORTSLOT START|END cycle from day one. Doing many iterations of forking, iterating the keyspace, and blocking clients while waiting for CLUSTER IMPORTSLOT END makes little sense.
I think this was brought up earlier and I agree, but I don't think it was actually addressed in the top comment. I'll add a section for updates.
I guess the intention here is actually mark it as a replication master (CLIENT_MASTER), right? We should, so mustObeyClient() lets us skip normal client restrictions if they apply in rare cases.
Yeah. We'll probably find out the right balance in the implementation, but yes it should call mustObeyClient() either by marking it as CLIENT_MASTER or adding a new flag.
Comment From: madolson
@soloestoy Gentle reminder you said you were interested in looking at the issue. It has been updated to take into account the latest conversations.
Comment From: uvletter
Finally catch up with the discussion, The proposal looks pretty good, I have some mirror comments as well:
If the slot being accessed is one of the slots currently being migrated, during propagation it will be queued on a dedicated buffer for the migration.
How about Sharing the same buffer with replication but with an extra index buffer to track the offset and length in buffer belongs to migration. It should save the dedicated buffer memory, and reuse the code for replication.
We will be forking once per batch of slots to be migrated, and serially sending the content of each slots in the batch. We believe there is an implicit tradeoff here between CoB usage, CoW usage, and time it takes to pause. We will optimize the number of slots in a batch to be migrated in a single fork based on performance testing. We think there will be some sweet spot for the number of slots to migrate per fork.
Maybe we can implement forking once for all slots at beginning for simplicity. The worst case is just another full sync replication, and I believe the time cost on pause while forking and consensus on handoff is over the memory waste on CoB and CoW for the high performance users.
A primary will synchronously replicate the CLUSTER MIGRATESLOT END to its replica, waiting for the acknowledgment, this will prevent the replica from needing to reconcile having data without knowing the state of the mgration.
Why not deliver the new topology to replica with clusterbus just like gossiping to the source node? In cluster v2 all topology consensus is made by TD, the counterpart in cluster v1 is gossip and vote. I think when the target receives CLUSTER IMPORTSLOT END, it gossips the new topology with a higher epoch to its replicas firstly, waiting for the acks, and then gossip to the source, and finally broadcast to all nodes, is a more consistent way with cluster v2 2PC, of course a more safe way is generating the new topology with a vote, but it's too slow.
Comment From: DarrenJiang13
Hi guys, sorry for being late, this is our schema for slot migration and we'd like to join the discussion. Instead of migrating by key, ours also fork once but try to migrate data by slot-rdb file stream. The migration state machine is nearly same to psync process.
(BTW, this schema on our redis 5.0 and redis 6.0 has provided stable and efficient cluster-rebalance performance for years Alibaba Cloud. So we'd also like to provide some potential corner cases to make the final slot migration design more perfect).
1. Diagram
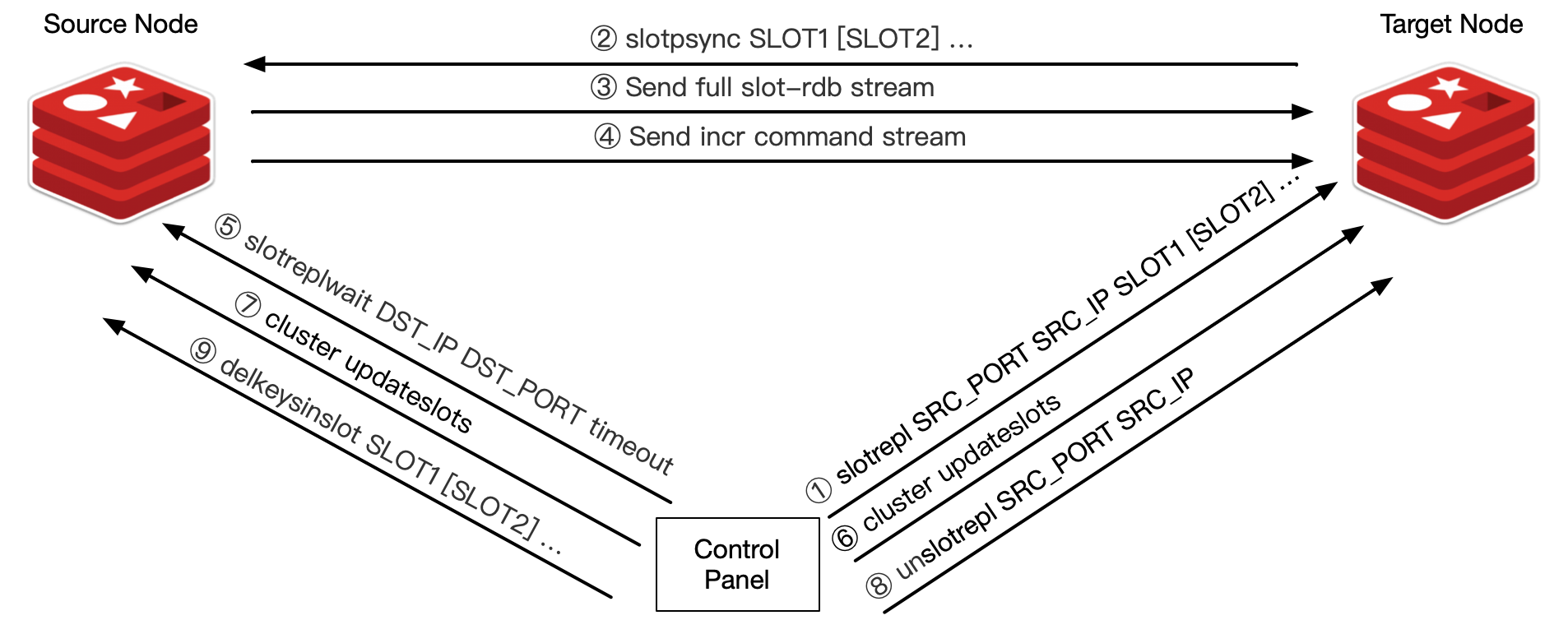
slotrepl command to target node, which helps set the source node information and slots to be migrated;
2. Target node then tries to connect to the source node using slotpsync command. After a successful handshake, go to step 3.
3. Source node starts a bgsave step which would save migrating slots into one slot-rdb file. Then rdb file should be sent to target node. Target node would start an async thread to load rdb data.
4. When fullsync finished, following incr commands would be transfered from source node to target node.
5. Control panel would send slotreplwait to source node to pause the clients which are related to the migrating slots. And expire/evict would be skipped for migrating slots in source node. Until slot replication offset of source node and target node equals to each other, go to step 6.
6. Control panel would send new cluster config to both source node and target node. After that, commands to migrating slots would be sent directly to target node.
7. Stop the replication relation between source node and target node with unslotrepl.
8. Delete unused slots in source node with delkeysinslot.
Steps 2-4 are inspired by primary-replica replication protocol. Therefore, the state machine is like a simplified version of syncWithMaster()
From the picture we can see 2 important points of the design: 1. fork-based slot replication (by rdb stream); 2. senseless migration for users with pausing clients;
2. Details
Here are some details for code.
2.1 slotrepl.c
In slotrepl.c, we implement basic structs and CRUD APIs for source nodes, target nodes and wait nodes.
‒ struct slotReplSource: For target node, source node info would be saved in slotReplSource node including slots, host, port and etc.
‒ struct slotReplTarget: For source node, target node info would be saved in slotReplTarget node including slots, host, rdb filename and etc.
‒ struct slotReplWaitNode: For source node, slotReplWaitNode is used to save the paused client infos.
‒ async flush: using slots_are_cleaning[] array to indicate which slots are ready to be cleaned. This array will help block all the operations to the cleaning slots and do delKeysInSlot() in another Cron function.
‒ client pause: using client pause for senseless migration.
2.2 slotrepl_rdb.c
This is for rdb related functions.
1. For source node: Fork a child process to save slot-rdb data. Usingslots_to_keysas the index to find keys belonging to same slot.
2. For target node: Create a bio to load data from slot-rdb file into a tmp db . After loading finished, move keys from this tmp db to actual db. If loading failed, delete tmp db. So this bio would help keep slot-level atomicity. With loading to tmp db, we can avoid pollution to main db while loading data and easily rollback task when failure (just like functions).
slot-level rdb replication has its disadventages: slot-rdb streaming replication between primarys could not be followed by their replicas. This means, when target node (primary) read slot-rdb from source node (primary) and load to db, target node (replica) knows nothing about it and would do nothing. Control panel needs to force a primary-replica synchronization after slot migration, which may cause a huge dataflow.
2.3 slotrepl_sync.c
In this file, slotReplCronTarget()and slotReplCronSource()work for sync part in slot migration.
1. For source node: slotReplCronSource()would deal with the slot-rdb issues like saving rdb.
2. For target node: slotReplCronTarget()deals with the replication state machine update. This is like a simplified version of syncWithMaster().
Here is a time diagram of the replication state machine.

Comment From: madolson
@DarrenJiang13 Some observations comparing the two: 1. There is quite a bit of reliance on a CP in your design sending states and controlling the coordinated failover. For self-managed, I would prefer it to be a little bit more integrated into just the engine. 2. I don't like that the replica needs to resynchronize afterwards. I would prefer to interleave the new slot information into the replication stream. 3. I like the tight relationship between regular replication and slot migration. I do think they should re-use as much code as possible.
Comment From: DarrenJiang13
@madolson
1. Yes, I agree that more logic should be integrated to just engine like "client pause" part.
2. Our design wants to solve bigkey problem so we choose the rdb-stream way. Therefore it has to resynchronize cause replica cannot notice the rdb-stream to master node.
"dump + restore" way can provide a more smooth replication stream. And for bigkey problem, I remembered we talked it before, #11395, it might be a good way to deal with that.
3. Yeah it is just like a "slot-master and slot-replica" relationship, so reuse the state machine or the code should be reasonable and make life easier.