This thread identified two improvements to scanning CME we would like to address:
- [ ] Implement a new command for doing a stateful scan of multiple cluster nodes.
Suggested command:
CSCAN <cluster cursor> <node cursor> [MATCH pattern] [COUNT count] [TYPE type]
The command does an incremental scan of cluster, using moved requests to indicate when the client has finished parsing the requests on the given node. If the command is sent to the wrong node, it will automatically be redirected to the correct one. The scan will guarantee that all data at the start and end of the scan will still hit at least once.
The command will allow use cases that allow external third parties to slowly scan the entire cluster, handling cases where slots may have moved during the course of the migration.
- [x] Once https://github.com/redis/redis/pull/11695 is merged, we will implement an optimization in the server so that clients who include a hashtag in their command, will just scan in the provided range.
Comment From: NikolaBorisov
I would also really like this command. I would propose SLOTSCAN 16300 [same arguments as SCAN]
Comment From: avcad
In my case I have code like this: SCAN 0 MATCH "{myCache1}-*"
I don't know the internals, but it appears Redis is not smart enough to optimize knowing to only apply the regex on keys in the slot for {myCache1}
Comment From: madolson
@avacd Redis is not smart enough to tell that, it doesn't introspect into the pattern to see that it contains a hash tag. It seems pretty straight forward to add that. As long as the full pattern is contained before any *, we can say for sure that the key would hash to a given slot, and we can check that structure for it.
Would you mind describing what process you do today? Is the motivation here primarily performance?
Comment From: avcad
@madolson
The motivation is performance.
We developed a caching framework that uses Redis. We decided to use hash-tags so we can operate atomically and with LUA. We use sets for secondary indexes, but for clear() operations we implemented SCAN {cacheName}-* + DEL, but then we found that as the SCAN always loops over the whole database, clearing small and big caches takes almost the same time.
Comment From: NikolaBorisov
My motivation is to be able to efficiently SCAN a large redis cluster. Basically I would like to spin a process to scan each slot and do some sort of migration
Comment From: madolson
@avacd I'm going to propose an alternative for you that I've been thinking about. I want to logically store keys with the same tag together and allow doing flushtag {tag} on them. Flushtag would be O(1) when done async, as it would unlink all of the keys together. You would also be able to scan all keys within the tag as well.
@NikolaBorisov I see, well that is an option. Ideally we probably want to be able to cooperatively scan the main dictionary with multiple iterators. I think it's likely possible, but I haven't spent much time thinking about it. In either case, the fallback to what you proposed could work.
Comment From: NikolaBorisov
@madolson I wanted to mention that basically if you have a redis cluster and you want to scan the whole cluster there are no nice ways to do it right now. You have to first find out who are the current master and then do scans on them. If in the mean time the cluster resizes or slots move you are in trouble. If i can scan by slot and get MOVED error I can restart my scan agains the new node for this slot.
Comment From: molian6
Hi @madolson ,
Since we are actively working on changing the db structure to one dict per slot for cluster[1], does it makes sense for us to reconsider the scan slot command? I think it would be much easier when [1] is merged.
I understand we have GETKEYSINSLOT. However, that is not paginated, making it hard to pack all the keys in a single response, if there are too many keys. The use cases I'm thinking are 1) scan the cluster in parallel, similar as @NikolaBorisov mentioned. 2) During slot migration, we might want to selectively delete some keys in a slot if memory is full preventing us from moving forward.
[1]https://github.com/redis/redis/issues/10589
Comment From: zuiderkwast
One dict per slot makes implementing slot scan very easy. I like it.
Comment From: PingXie
I think another area that can benefit from having a scan-slot command with pagination support is identifying large keys/values, especially the ones that end up impacting slot migration. GETKEYSINSLOT kind of supports the use case but as @molian6 mentioned it is unwieldy and it hogs the server unnecessarily so it is hard to build a low impact online key analysis tool on top of it.
Comment From: PingXie
@madolson since you guys are almost ready to post the one-dict-per-slot changes, I wonder if we could use this thread to close on the command shape. I like @NikolaBorisov's suggestion to keep it identical to SCAN, conceptually. Implementation wise, what would be a better option, a subcommand of SCAN opted in via a new slot token or a top level command?
BTW, @avcad I think you have a bit more sophisticated use case here than the proposed scan-slot command. That said, I think it can still be built as an add-on to the scan-slot command, either inside of Redis or via a hashtag-to-slot translation layer in your own app.
Comment From: madolson
Well, I was very optimistic about the "almost ready" part. It's a lot harder than we thought :/, but we'll post it when we can.
One tenet I would like to try to upload is that "end clients" shouldn't know about slots. It's a struct that client developers should be aware, but is transparently handled by them so that end users don't see it. So, I would really like this to be a transparent optimization. One earlier use case that was mentioned was attaching a hashtag to the SCAN operation, which could be optimized to just scan the SLOT where data can exist.
Are there other use cases for this SLOT scan we need to handle? I'm not seeing them in this thread.
Comment From: NikolaBorisov
Having access to this command is important to be able to iterate over the database efficiently. In a large cluster, slots are often moving between servers. Given this, if you just use SCAN trying to iterate over the cluster, you will miss some keys. If you use redis as a persistent database, you often have to iterate and migrate data from one format to another.
I would prefer SLOTSCAN, but adding an argument to scan is fine, too.
Comment From: zuiderkwast
It's a nice idea that end users shouldn't need to know about slots, but in practice it's not always true. Slots are far from invisible to applications. For slot migration (GETKEYSINSLOT) and for consistently iterating of the keys as @NikolaBorisov mentioned. Atomicity and consistency (transactions) are per slot actually and it's well documented.
An extreme case is for balancing the data evenly over the cluster. To be able to create the keys (or even tags) in a way that distributes them evenly over the slots, in one application that I know of they reverse-engineered the CRC16 algorithm to be able to do this efficiently.
Comment From: madolson
So we have three use cases:
* I need a consistent view of all keys in a single slot. The main use case is for slot migration. cluster getkeysinslot covers this case.
* I want to run a background operation that needs to hit all keys in the cluster that existed for the entire duration of the scan. (This is the same guarantee as regular scan in cluster mode disabled). This is typically the type of guarantee you want for database like use cases and also works for analytics. This could be achieved with a custom cursor that is slot aware, and issues moved if you send it to the wrong node. Since clients already generally handle moves. If a slot migration is ongoing, we might return keys multiple times, since the data might be migrated and we need to restart on the new node, but this is also possible for regular scans. This could also be made more transparent by a new command that includes the slot.
* I want to accelerate scan to just scan a specific slot based on a hash tag. We can do this optimization transparently on top of scan without a new command.
I want to make sure I've fully captured the requirements for 2, and there isn't some fourth case I'm missing.
Comment From: madolson
Based on what I just said, I think to solve 2\ we want a new cluster aware SCAN, for now let us say it's scan with a cluster argument, with a cursor that covers all the cluster keys. If we really want a SCAN SLOT command, I would like to understand the specific use case it is solving.
Comment From: NikolaBorisov
Here is the use case i had for scan slot. Imagine a large redis cluster. 100s of servers, 50 TB of memory, hundrets of billions of keys. Now imagine you need to iterate over all the keys, and let's say change the data a bit. Imagine you are storing users' accounts and hashes, and you want to reformat the phone numbers or something. When you do such a large iteration over the whole database, you want it to go in parallel. So you start N processes, and each of them connects to one of the master on the cluster and uses regular SCAN to iterate. The problem i had was that with large clusters, while you perform, the scan slots can move between masters. When this happens, you no longer have the scan garantees. You have to restart the scan to be sure all keys got iterated on. SCAN SLOT will allow us to implement this kind of iteration better because we can detect slot migrations and only restart those.
If you just implement cluster scan with somehow single cursor over the whole cluster, it won't help with scanning large clusters in parallel.
Hope this explains why SCAN SLOT is needed.
Comment From: vitarb
Once https://github.com/redis/redis/pull/11695 is landed we are going to encode slot id in the least significant bits of the SCAN cursor. This has two implications in the context of this issue: * It should be extremely easy to implement slot specific scan API extension (e.g. extra parameter to SCAN), which would only scan single slot specific dictionary instead of the entire DB. * Even without this API extension user should be able to achieve similar functionality by passing slot ID in the cursor, here is example that I ran on that PR's branch:
127.0.0.1:6379> scan 777 COUNT 1
1) "1049353"
2) 1) "key:000694984249"
127.0.0.1:6379> CLUSTER KEYSLOT key:000694984249
(integer) 777
The only caveat with the later approach is that you will need to figure out yourself when to stop, because SCAN will continue to the next slot automatically after you've iterated through all keys in the slot (stop condition should be when cursor & 16383 changes value to the next slot).
Comment From: NikolaBorisov
Sounds great. I think the documentation of scan should be updated, to reflect the this. I would really love SCAN 0 SLOT 777 syntax.
Comment From: vitarb
We'll update the documentation once change makes its way into the release.
Note that with https://github.com/redis/redis/pull/11695, correct starting cursor for slot 777 would be 777, not 0, hence there is no point in specifying both cursor and a slot in the command, as they'll be the same (at least when slot iteration starts).
I believe that all we need on top of the above PR is to address these use cases: * SCAN API with cursor that points to a slot that is not owned by the node should return an error. * When slot has no keys in it or slot iteration is completed, SCAN should complete, instead of jumping to the next slot.
This can be easily achieved by either passing a separate flag passed to SCAN (e.g SLOT), or adding a new API, I don't have a strong opinion on that.
That said, although addressing above issues would provide quality of life improvements, they should be relatively easy to overcome on the client side.
Comment From: avcad
I'd like to bring back my original request. I am not sure if it can be discussed here, or if it should be a new item: can we have scans like this recognize that they are restricted to a single slot automatically? without having to use new syntax? SCAN {user}-*
Comment From: zuiderkwast
can we have scans like this recognize that they are restricted to a single slot automatically? without having to use new syntax? SCAN {user}-*
@avcad This is an optimization that doesn't require any API design decision, so it should be easier to accept. I think this contains two parts:
- A client optimization. The client can detect this and send the SCAN command only to the node responsible for the slot.
- A Redis optimization. I think we should wait until #11695 is merged, because it drastically changes how this optimization would be implemented.
Comment From: madolson
Note that with https://github.com/redis/redis/pull/11695, correct starting cursor for slot 777 would be 777, not 0, hence there is no point in specifying both cursor and a slot in the command, as they'll be the same (at least when slot iteration starts).
I think the main thing worth mentioning is we still want clients to treat the cursor as opaque, so that we can change the implementation under the hood.
Comment From: madolson
@zuiderkwast I summarized the two improvements on the top. @redis/core-team, would like to conceptual approval for the work mentioned, I think it would be good to target for Redis 8.
Comment From: oranagra
I certainly agree with the optimization (SCAN {user}-*), is that what you meant in your second bullet in the top comment? we can't have it scan the entire slot in that case, just keys that fall into that pattern...
anyway, i'm not certain about the new interface. 1. what are the use cases for that? is it more of an administrative command (maybe a sub-command of CLUSTER, next to CLUSTER KEYSLOT)? 2. how will clients handle routing this command (without relying on an excessive round-trip and MOVED response)? it's not a key and isn't covered by key-specs. 3. what if the user provides slot-range that doesn't all belong in one node? get a CROSSSLOT error?
Comment From: zuiderkwast
@madolson
Regarding CSCAN, I suppose the main point is that it can "guarantee that all data at the start and end of the scan will still hit at least once", just like a scan on a standalone node.
Implement a
CSCAN(...) which does an incremental scan of the cluster in place. If the command is sent to the wrong node, it will automatically be redirected to the correct one, allowing for incremental scanning.
I'm trying to understand what this means. Is the following scenario understood correctly?
- A client starts a scan without pattern at cursor 0 (meaning slot 0 but that's opaque) by sending the command to a random node. If the command is sent to a node that doesn't hold slot 0, the node MOVED-redirects to the node that holds slot 0.
- When the node that holds slot 0 has exhausted its continuous slot range starting at 0, lets say slots 0-5, the node returns the cursor value 6, meaning the start of slot 6.
- If the client then continues scanning cursor 6 using the same node, the node then redirects to the node that holds slot 6, where the scan continues until that node redirects to the node owning the next range.
- And so on, until the node owning slot 16383 finally returns the cursor 0.
Some thoughts:
- If each node holds many small scattered slot ranges, it means many redirects during one scan.
- Some existing clients may be able to handle this out of the box (e.g.
redis-cli -c), but many clients do a slotmap update whenever they see a MOVED redirect. In this case they shouldn't, so it would be sorta breaking to them. Maybe an ASK redirect would be better as it doesn't imply that anything is moved? - CSCAN looks very much like the regular SCAN. Can't we just add redirects, and the SLOTRANGE option, to the regular SCAN in cluster mode? Would that be a breaking change? (In standalone mode it can return an error if SLOTRANGE is present.)
- Are there any alternatives? Scanning all masters concurrently
P.S. Why don't AWS people use the terms "standalone mode" and "cluster mode" like in the code base and the docs? :grin: (Or even CEY and CEN, since the config is actually cluster-enabled yes and cluster-enabled no... :grimacing:)
Comment From: hpatro
Implement a CSCAN
[SLOTRANGE start end] [MATCH pattern] [COUNT count] [TYPE type], which does an incremental scan of the cluster in place. If the command is sent to the wrong node, it will automatically be redirected to the correct one, allowing for incremental scanning.
@madolson I guess we would need to have a custom routing based on the slot number provided here. Do we want to build this semantic and make it accessible for other APIs for e.g. FLUSH [SLOT ID] to clean data for a slot and gets redirected to the correct node based on the slot information parsed.
Are there any concern on making the regular SCAN command cluster mode aware then with a new optional parameter SLOTRANGE given most of the API is the same ?
Comment From: madolson
CSCAN looks very much like the regular SCAN. Can't we just add redirects, and the SLOTRANGE option, to the regular SCAN in cluster mode? Would that be a breaking change? (In standalone mode it can return an error if SLOTRANGE is present.)
I was expecting clients to want to handle this command specially, since I think in many cases SCAN is handled special too, and clients have generally asked to make special commands entirely separate instead of subcommands. I also wanted to avoid fundamentally changing behavior when slotrange was provided to include moves.
I also generally want to require clients to know about slots, so they should be able to provide no arguments and do a complete cluster scan. I think that is easier to do with a new command.
P.S. Why don't AWS people use the terms "standalone mode" and "cluster mode" like in the code base and the docs? 😁 (Or even CEY and CEN, since the config is actually cluster-enabled yes and cluster-enabled no... 😬)
The hardest problem in computer science is naming right? I actually have not really noticed the term standalone before.
Comment From: madolson
I don't think -ASKING is right, since it's only sent when doing a oneoff request to a different node. Today most clients don't do topology rediscovery, but most clients won't understand how to route this command anyways. There is another option as well, we could deconstruct the cursor into two parts, and array with slot + cursor. The command could then become something more like CSCAN CURSOR SLOT filters, and could target a specific slot, similar to what @hpatro mentioned. Clients could learn that in addition to a key to hash, there can be slots to directly route commands to.
Comment From: madolson
what are the use cases for that? is it more of an administrative command (maybe a sub-command of CLUSTER, next to CLUSTER KEYSLOT)?
So far no one has asked for an admin command, it's mostly been to make sure all keys are accessed as part of scan.
how will clients handle routing this command (without relying on an excessive round-trip and MOVED response)? it's not a key and isn't covered by key-specs.
The normal scan command isn't covered today, so I'm not sure what your point is. Clients will need to implement special logic, they won't get it for free.
Comment From: zuiderkwast
@madolson
I don't think
-ASKINGis right, since it's only sent when doing a oneoff request to a different node.
Fair enough.
Today most clients don't do topology rediscovery,
That's really surprising. Apart from redis-cli, I haven't seen a client that doesn't send CLUSTER SLOTS or NODES at -MOVED. I haven't worked with short-lived connections though.
There is another option as well, we could deconstruct the cursor into two parts, and array with slot + cursor.
Then we could just as well document that the 14 LSB is the slot (leaving the remaining bits opaque) and allow clients to use this information with SCAN and its own routing by slot.
The command could then become something more like CSCAN CURSOR SLOT filters, and could target a specific slot, similar to what @hpatro mentioned.
A SLOTSCAN command for a single slot seems simpler to use and to route. We can keep an opaque cursor and it turns to 0 when the slot has no more keys. A -MOVED slot host:port redirect would also make more sense. I like that more than CSCAN.
I actually have not really noticed the term standalone before.
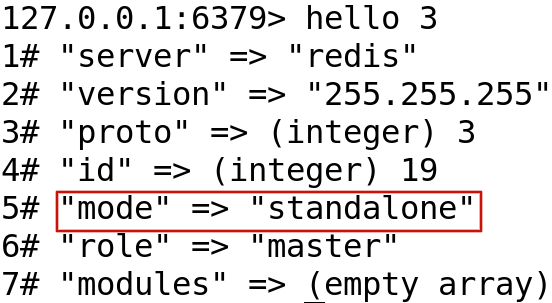
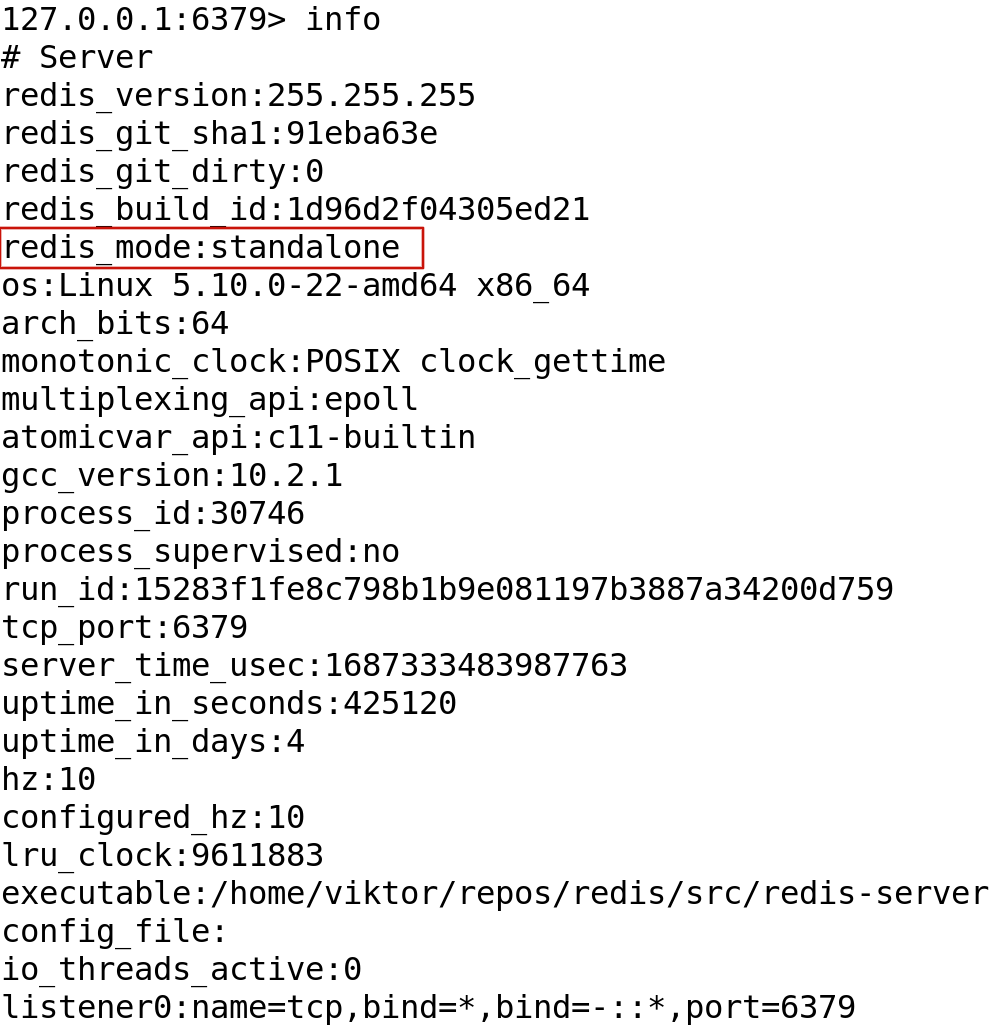
Really??? I have found some examples for you: :grinning:
 |
 |
|---|---|
 |
 |
Comment From: madolson
That's really surprising. Apart from redis-cli, I haven't seen a client that doesn't send CLUSTER SLOTS or NODES at -MOVED. I haven't worked with short-lived connections though.
This loops all the way around to us not having a standard client specification we expect clients to implement. You have convinced me though, we probably shouldn't return -MOVED either since that breaks the semantic.
Then we could just as well document that the 14 LSB is the slot (leaving the remaining bits opaque) and allow clients to use this information with SCAN and its own routing by slot.
I would really prefer to keep the cursor opaque if we can, just so that we can make minor modifications in the future and it won't impact the correctness at all. We already have one slot command, https://redis.io/commands/cluster-getkeysinslot/, albeit it is not really intended to be used by normal clients.
A SLOTSCAN command for a single slot seems simpler to use and to route. We can keep an opaque cursor and it turns to 0 when the slot has no more keys. A -MOVED slot host:port redirect would also make more sense. I like that more than CSCAN.
The main thing I don't like about slot scan is that it breaks the abstraction Redis has around data, which is that clients don't need to know about slots, keys are just hashed into slots and you aren't supposed to access data that doesn't share a {hashtag} (although you might get lucky). SLOTSCAN draws attention to it, maybe I shouldn't be such a purist though.
I would still prefer to call it C(cluster)SCAN and have it return a two part cursor. The documented behavior is you should call it with 0 0, and it will automatically increment the the slot to the next one once it's done. If a client would like to implement the logic themselves and do multi-part scans, they have all the information they need.
Really??? I have found some examples for you: 😀
In my defense, I want to get rid of sentinel and this so called "standalone" mode and have only one configuration left. I wonder if anyone is using this information for anything in HELLO.
Comment From: zuiderkwast
I would still prefer to call it C(cluster)SCAN and have it return a two part cursor. The documented behavior is you should call it with 0 0, and it will automatically increment the the slot to the next one once it's done. If a client would like to implement the logic themselves and do multi-part scans, they have all the information they need.
OK, I get the point now. The slot is what a -MOVED redirect refers to. Routing and redirects are handled by the client lib while the end user can call CSCAN as a regular command without caring about slots. One abstraction for the client lib and another abstraction for the end user. :+1:
Will you update the top comment to CSCAN something like this then?
CSCAN <slot> <cursor> [MATCH pattern] [COUNT count] [TYPE type]
alternatively
CSCAN <slot-cursor> <within-slot-cursor> [MATCH pattern] [COUNT count] [TYPE type]
and the return value as a three-element array:
- The slot where to continue scanning
- a cursor where to continue scanning within the returned slot
- the array of keys returned
In my defense, I want to get rid of sentinel and this so called "standalone" mode and have only one configuration left. I wonder if anyone is using this information for anything in
HELLO.
We can probably get rid of "mode" in HELLO. I'd be happy to get rid of all non-cluster modes too, but that's a larger discussion.
Comment From: madolson
Sometimes I feel like my ideas are bad, but I thought of another option. We already have this notion of "not a key", which is used by sharded pubsub, to route commands based on channel names. In various threads we've discussed extending the cluster hashing so that clients can specify the specific slot they want the key to end up on. (Maybe something like "{:1234}foo" puts the key in slot 1234).
Combining these two concepts together, we could emit a cursor that is marked as "not a key", but can be interpreted as a key for the purposes of routing. Say, "{:0}cursor". This makes it drop in API compatible with SCAN (just swap SCAN for CSCAN and still use 0 as initial condition) and re-call it with the returned value.
We don't even technically need the new {:1234} format, since we could just reverse engineer a valid 3 byte key for each slot. (I like the :1234 since it makes the life easier for Nikola, but once people know the cursor, they could reverse engineer it themselves. It also removes the unnecessary crc16 computation, but maybe that's the price we pay for simplicity)
Comment From: hpatro
Combining these two concepts together, we could emit a cursor that is marked as "not a key", but can be interpreted as a key for the purposes of routing. Say, "{:0}cursor". This makes it drop in API compatible with SCAN (just swap SCAN for CSCAN and still use 0 as initial condition) and re-call it with the returned value.
Trying to make sense of the proposal. So, some of these question might be repetitive but not sure if it's still valid.
- Does the client needs to start with {:first-slot}0 on a given node ? possibly determined from
CLUSTER NODESresponse. - Does the server returns back a cursor after iterating a single slot ? For clients who would like to scan particular slots specifically.
- After all slots (forward looking) are covered for a given node, do we return back a terminal cursor or provide
{:first-slot-of-another-node}cursorto let client redirection appropriately work ?
Comment From: madolson
Does the client needs to start with {:first-slot}0 on a given node ? possibly determined from CLUSTER NODES response.
No, it can just start with 0.
Does the server returns back a cursor after iterating a single slot ? For clients who would like to scan particular slots specifically.
It someone wants to scan a particular slot, they'll have to look at the contents of the cursor.
After all slots (forward looking) are covered for a given node, do we return back a terminal cursor or provide {:first-slot-of-another-node}cursor to let client redirection appropriately work ?
Let the cursor do redirection transparently, so it can return the start of the next slot.
Comment From: hpatro
No, it can just start with 0.
I believe your proposal is to go node by node and complete scanning of keyspace in each of them.
I've a slightly different take how about scanning one slot after another. For a 0 cursor request, it would get redirected to the node owning the first slot and the cursor response is {:slot}cursor which supports iterating over the slots [0-16384). With this the client doesn't need to maintain the nodes traversed and also be unaware of the topology changes happening while this scan request is ongoing.
One downside which I can think of is if the slots are fragmented, there will be more redirection.
node1 (6379) slot ownership 0-5460
node2 (6380) slot ownership 5461-10922
node3 (6381) slot ownership 10923-16383
# Client connects to node2
6380> CSCAN 0
# Redirected to 1st node
# Redirects to node 1 as it owns the first slot and sends the same request
6379> CSCAN 0
1) cursor
2) "{:5461}0"
3) keyspace
4) 1) 1092
2) 1) "key:10"
2) "key:44"
3) 4113
4) 1) "data1231"
# Sends the next request with the provided cursor in the previous response
6379> CSCAN {:5461}0
# Redirected to 2nd node and so on.
It someone wants to scan a particular slot, they'll have to look at the contents of the cursor.
Would we have separate SLOTCOUNT to restrict scanning of particular no. of slot(s) together ?
Comment From: madolson
I believe your proposal is to go node by node and complete scanning of keyspace in each of them.
No, my suggestion is largely in-line with what you are proposing. The very first request would need to perform a redirect as you indicated, but it could be sent to any node. We could also potentially come up with a special "initial" index which happens to map to slot zero.
Comment From: hpatro
@madolson awesome. I like this idea. 👍
Comment From: soloestoy
Finally finished reading this thread, here are my thoughts:
- Initially, I thought SLOT-SCAN was good because it is flexible and allows users to control the slot, and help users better understand the distribution of keys and slots in the cluster.
- Then, when reading https://github.com/redis/redis/issues/2702#issuecomment-1609397052 I thought about it and realized CSCAN is also good. It can include the next required slot in the reply, which can help the client select the slot.
-
However, upon careful consideration, I realized that these two options are quite similar:
- With SLOT-SCAN, users can increment the slot by 1 (when the returned cursor is 0) to automatically find the next slot.
- With CSCAN, users can ignore the slot in the reply and manually specify the next slot to use in the next CSCAN. Redis also doesn't restrict consecutive slots for two CSCAN calls.
So, these two API designs are not significantly different. Considering this, I feel SLOT-SCAN is slightly better because it is simpler to implement and easier for users to understand. 4. I am not a fan of the new tag design {:1234}. It is neither a slot nor the current hashtag design. It could lead users to confusion and easily mix it up with the hashtag in the key.
IMHO, when you try to hide some details from users to make it easier for them to understand, it can backfire. When you try to simplify something using various methods, it can actually make it more complex.
These hidden details make it difficult for users to understand, just like the slots in the cluster. We use various methods (hashtag or new format) to hide them, but it makes it harder for users to understand and use, if the new command lack the information about the key/slot distribution in the cluster.
AFAIK, when using hashtags, users also calculate the crc16 of the hashtag to prevent different hashtags from mapping to the same slot. And users usually calculate the slot based on the hashtag to distribute it to the specified node and avoid data skew.
All in all, I vote for SLOT-SCAN, because simple is better.
Comment From: madolson
These hidden details make it difficult for users to understand, just like the slots in the cluster. We use various methods (hashtag or new format) to hide them, but it makes it harder for users to understand and use, if the new command lack the information about the key/slot distribution in the cluster
I don't agree with this. Redis clustering exposes an API that is intended to NOT expose the underlying hashing algorithm. This is for a very good reason, which is that users don't need to understand how keys are being distributed in the cluster. There are no datastructure commands that expose the slot today, and unless there is a very compelling reason, and I have yet to see a compelling reason for why we should start.
I am not a fan of the new tag design {:1234}. It is neither a slot nor the current hashtag design. It could lead users to confusion and easily mix it up with the hashtag in the key.
I've mostly fallen out of favor with this, specifically because of what I mentioned early. There are some reasons it was useful, but in almost all cases it made the end user story more complicated.
Comment From: mgravell
On the {:1234} routing; if this is only ever for CSCAN, maybe, but it seems like an odd and unusual special case. For general-purpose clients, if ever used more widely: this becomes a routing nightmare, since it is unclear how we would retrofit "oh, btw arg 7 should check for slot hashtags" - noting that under existing routing rules {:1234} already has a defined but different meaning (it would compute the hash as the key :1234). Honestly, I think it would be better to take a dummy key arg just used for routing, and have the server send the key to use for the next op (presumably from a precomputed table of short keys for each slot), and just have clients use their existing routing rules.
Comment From: mgravell
This takes 0.004s (not even remotely optimized) on my low-power laptop (in battery profile) to compute all the slots using printable ASCII (excluding space - basically: 33 thru 127) up to three characters: https://gist.github.com/mgravell/bbbb83c1e13b1f05328064f41400436f
I forgot to add rules but as it happens: none of the generated keys have hash-tag ambiguity. So, at cost of 48KiB a corpus of known tags for slots could be embedded, either from a file or computed at launch (presumably using \0 for shorter-than-three-char keys, or we could just tweak the code and generate exclusively exact length-three keys, which would need less processing at runtime)
Comment From: madolson
For general-purpose clients, if ever used more widely: this becomes a routing nightmare, since it is unclear how we would retrofit "oh, btw arg 7 should check for slot hashtags" - noting that under existing routing rules {:1234} already has a defined but different meaning (it would compute the hash as the key :1234).
This is a great point I didn't even consider.
ASCII (excluding space - basically: 33 thru 127)
It's depressingly so close to only requiring 2 characters. I also have a POC using 3 bytes, and it does a lazy invocation that also takes a couple of ms. I'll probably change it to startup, since we probably don't want to suddenly pay the 4ms randomly during runtime. Maybe I'll finish it tonight so we can base our followup on that, I think a PoC would be better than arguing about cursor options over text.
Comment From: mgravell
It's depressingly so close to only requiring 2 characters.
If we use binary-safe keys (ignoring { and } to avoid problems with hash-tags), then this is indeed possible - and at least in my code, is faster to pre-compute; this makes the space needed only 32KiB (obviously). So if you're happy for text-protocol consumers to use the escape codes, this is an option.
https://gist.github.com/mgravell/d0c53ae3c370b16871077aa3eab7a3e0 (actually it finds all combos by 46957 - doesn't need all 64k)
Comment From: zuiderkwast
I too prefer SLOT-SCAN (explicit slot) over CSCAN, for the following reasons:
- Explicit is simpler than implicit.
- SLOT-SCAN allows scanning slots in parallel (for batch operations in all keys in a cluster) which CSCAN doesn't.
- It can be used as a paginated CLUSTER GETKEYSINSLOT.
I would also argue that scanning per slot is mainly an admin operation so we don't really need to hide the slot from the user here. Why? A user who doesn't care about slots would use tags instead. To scan related keys they would scan with a pattern like SCAN {tag}* which we should also optimize, both in server and cluster clients. Scanning all keys in a cluster is certainly and administrative operation (e.g. converting data to match updated application code).
Comment From: NikolaBorisov
Let's just do SLOT-SCAN
Keeping it simple. The key thing is to get notified when the slot has moved to another server. Without this command, you can not reliably iterate reasonably fast over large cluster.
KISS
Comment From: madolson
KISS
Then I'm going to go back to my original PoV, that this isn't a needed feature. You can already do a parallel scan today by scanning the underlying nodes in the cluster. There is no reason to introduce a new command, that won't be well supported by clients. Admins already know about the underlying nodes in the cluster, so they can incrementally call SCAN on each node until they've completed the migration. Following KISS, we should just encourage the usage of what we have and fix the gaps (maybe support multiple SCAN on a single node).
I would also argue that scanning per slot is mainly an admin operation so we don't really need to hide the slot from the user here.
If it's a user feature, I don't want them to deal with slots, if it's an admin feature, they can deal with nodes. I don't really see a place for SLOT-SCAN in Redis.
To scan related keys they would scan with a pattern like SCAN {tag}* which we should also optimize, both in server and cluster clients. Scanning all keys in a cluster is certainly and administrative operation (e.g. converting data to match updated application code).
I think this is the only real followup from this thread.
Comment From: zuiderkwast
There is no reason to introduce a new command, that won't be well supported by clients.
I though a key point you acknowledged earlier is a cluster-wide scan (parallel or not) with the scan guarantee that each key hits at least once. Maybe it won't be well supported by clients initially but at least provide a way to get this guarantee.
It's not even a new command if we add a SLOT argument to the regular SCAN command. Regarding keyspecs, this argument would be just like the slot in CLUSTER GETKEYSINSLOT. It doesn't really need to do redirects either, if we want minimalism. If we reject it, I suspect some users will go @vitarb's way and reverse engineer the cursor to get this feature.
Admins already know about the underlying nodes in the cluster, so they can incrementally call SCAN on each node until they've completed the migration.
Do you mean that if SCAN is called in parallel and incrementally on all nodes, you get the guarantee that all data at the start and end of the scan will hit at least once? Regardless of any migrations and failovers? If that's true, it is a very interesting observation.
Is it true though? Assuming we fix the seed issue you mentioned in #12440?
If it's a user feature, I don't want them to deal with slots, if it's an admin feature, they can deal with nodes. I don't really see a place for SLOT-SCAN in Redis.
~~CLUSTER GETKEYSINSLOT is currently a problem since it's O(N). I suppose the solution you have in mind for this use case is to implement a different (atomic) slot migration. I hope we'll get this soon though then. :)~~ Edit: CLUSTER GETKEYSINSLOT has a count option, so migration can be done incrementally.
Comment From: mgravell
CLUSTER GETKEYSINSLOT is currently a problem since it's O(N).
The N in that is the count that the caller passes in, which makes it broadly comparable to SCAN, citation (emphasis mine):
Basically with COUNT the user specified the amount of work that should be done at every call in order to retrieve elements from the collection.
But yes, if you wanted to get all the keys in a given slot, you'd need to pass in a big count, making it painful to iterate all the keys in a single slot (as opposed to on a single node). I do agree that semantically adding a SLOT arg to SCAN might work, but I don't know (in either a positive or negative sense - I'm simply ignorant) whether that works with the cursor semantics.
Comment From: zuiderkwast
@mgravell Right! Sorry, I missed that CLUSTER GETKEYSINSLOT slot count has a count argument.
Comment From: madolson
Do you mean that if SCAN is called in parallel and incrementally on all nodes, you get the guarantee that all data at the start and end of the scan will hit at least once? Regardless of any migrations and failovers? If that's true, it is a very interesting observation.
As long as no slot migrations are in progress. If there was a migration, you do need to repeat the scan. That provides the same guarantees, although it's less efficient since you are doing scans multiple times.
Comment From: NikolaBorisov
If you have a large cluster slots will be moving while you do this full scan. If a slot moves what should we do? If we do nothing we missed some data. We basically now need to monitor any moves and if a move does happen you need to restart the scan from the beginning on that node.
Any large database needs a way to traverse all the data reliably. The single node redis has this. The redis cluster needs this.
It also does not seem like this is hard command to implement. You can either make a new command or add it to the SCAN.
When the cluster is large running on 1000+ nodes the chance of slot migrating is high.
On Tue, Aug 22, 2023, 11:10 AM Madelyn Olson @.***> wrote:
Do you mean that if SCAN is called in parallel and incrementally on all nodes, you get the guarantee that all data at the start and end of the scan will hit at least once? Regardless of any migrations and failovers? If that's true, it is a very interesting observation.
As long as no slot migrations are in progress. If there was a migration, you do need to repeat the scan. That provides the same guarantees, although it's less efficient since you are doing scans multiple times.
— Reply to this email directly, view it on GitHub https://github.com/redis/redis/issues/2702#issuecomment-1688683040, or unsubscribe https://github.com/notifications/unsubscribe-auth/AABNAATAXBH7LAFIZHFPNCTXWTY2RANCNFSM4BMHC3LQ . You are receiving this because you were mentioned.Message ID: @.***>
Comment From: madolson
Explicit is simpler than implicit.
Redis cluster is already implicit. You aren't required to know which slot a key maps too, the client is doing that transparently for you. I think that makes sense, since it provides a very simple end user experience for interacting with Redis. I want to extend that here. Unless you absolutely have to, it's simpler for the end user not to have to understand that there are slots.
SLOT-SCAN allows scanning slots in parallel (for batch operations in all keys in a cluster) which CSCAN doesn't.
This isn't that difficult to solve. We can support an operation that says given me the nth iterator, and it will do that without exposing the slots. This doesn't seem like that much of a "difficult" problem to solve, and could also always be solved later.
It also does not seem like this is hard command to implement. You can either make a new command or add it to the SCAN.
I still think you're misunderstanding the point. Your suggestion is not not difficult, but it exposes a new construct into Redis cluster, "slot". There are no non-admin APIs today that expose slots. The only ones are admin commands such as cluster setslot, and I want to keep it that way. Clients and application developers should NOT need to understand slots, they only care about a uniform keyspace where data is placed by some magic. The administrators of the clusters care about slots.
I have still not seen a good reason why slots are worth exposing as a construct to end developers.
Comment From: NikolaBorisov
I have still not seen a good reason why slots are worth exposing as a construct to end developers.
Ok. Please let me know how I can iterate over a redis cluster and make sure I see every key at least once like with SCAN. I also need to do this in parallel, because the cluster is large and I want to finish this SCAN not in days. It is critical to make sure this also works reliably while the cluster is in motion (aka slots are being moved). I don't want to re-scan half the cluster because one slot moved.
What API are you proposing to do this? If you want we can do a call and discuss this further.
Comment From: madolson
@NikolaBorisov I do want to chat about this, it just has been low on my list. However, this license change has made a good time to re-evaluate stuff. If you want to follow up, we moved here https://github.com/placeholderkv/placeholderkv/issues/33.