Feature Type
-
[ ] Adding new functionality to pandas
-
[X] Changing existing functionality in pandas
-
[ ] Removing existing functionality in pandas
Problem Description
The ergonomics of .rank() are much worse than SQL equivalents. It's almost always something that you want to keep in the context of other data, often an ID for the thing being ranked (which is not what you have to group by). For instance, when trying to apply KNN within a dataframe
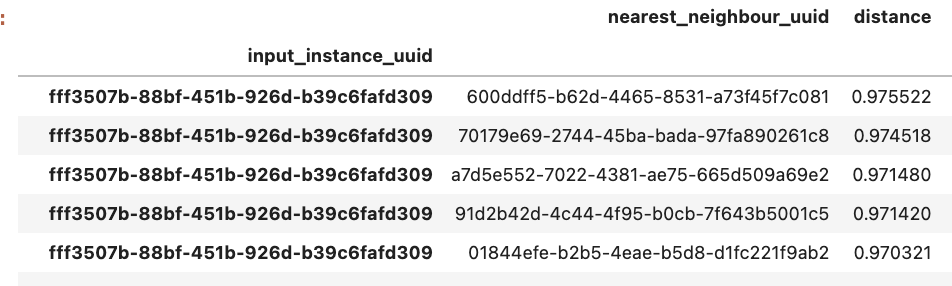
You need to groupby the input_id, but retain the neighbour_id and its class. This is bizarrely awkward to achieve currently compared to what would just be a rank() over (group by input_id, order by distance ).... in SQL.
The design is also counter-intuitive, groupby normally results in one row per the column you groupby. This is not the case with .groupby().rank()
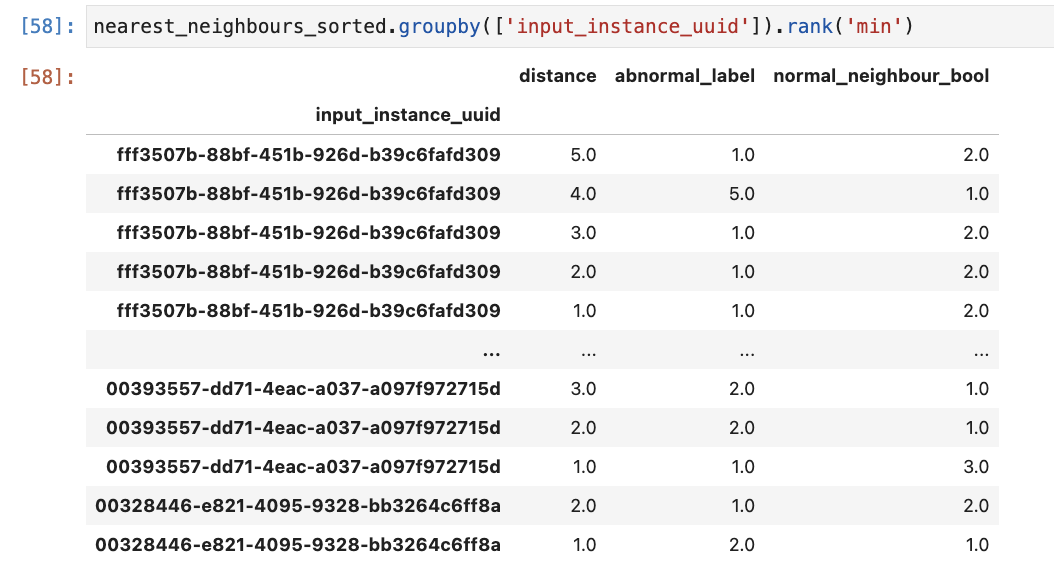
Feature Description
The ability to rank but retain the rest of the information in the dataframe.
Alternative Solutions
Using a SQL <-> pandas interface?
Additional Context
I'd be happy to try to achieve this
Comment From: GYHHAHA
Thanks for issue @GeorgePearse. Could you please refine the issue title and give minimal executable codes (including the demo data you create) for your requirement?
Comment From: rhshadrach
@GeorgePearse if you want to rank by distance, you can do e.g. df.groupby('grouping_column')['ranking_column'].rank() this give you back a Series of ranks. If you want to add that to your original DataFrame, you can do that too:
df['rank'] = df.groupby('grouping_column')['ranking_column'].rank()
The current design allows you the option of not adding to the DataFrame, which can be useful e.g. when using ranks to construct a boolean mask.
Comment From: MarcoGorelli
thanks for the request - closing for now, but please do ping if the above doesn't address your needs
in the future, please don't post screenshots of code as they're not searchable