Research
-
[X] I have searched the [pandas] tag on StackOverflow for similar questions.
-
[X] I have asked my usage related question on StackOverflow.
Link to question on StackOverflow
https://softwareengineering.stackexchange.com/questions/442574/roadmap-to-understand-pandas-dev-pandas-open-source-project
Question about pandas
tldr:
What topics do I need to study to understand how everything in the pandas repo meshes together (py, pyx, c files, cmake) to reach the final result which is a hybrid library that is consumed purely from a python api (import pandas as pd)?
Context
I have been trying for a while to understand how pandas is built by looking at the repo. It seems it keeps .pyx files that are later converted by Cython into c files (?), there are also have some .h and .c files under https://github.com/pandas-dev/pandas/tree/main/pandas/_libs.
I'm looking for a sequence of topics (or materials) that a python developer that has never touched Cython, cmake or similar, needs to study to gain the knowledge necessary to understand the pandas project source code, or something equivalent. Alternatively, an explanation on how the project internally meshes together would be amazing.
I read the pandas how to contribute page but it was not enough to answer this question.
Comment From: lithomas1
Hi, I'm one of the core devs that works on the build system. To answer your questions:
pandas current build system is based on setuptools, and Cython. There also is a library called versioneer, that writes the version string, into the library with information from git.
It seems it keeps .pyx files that are later converted by Cython into c files (?), there are also have some .h and .c files under https://github.com/pandas-dev/pandas/tree/main/pandas/_libs.
Yes, you are correct that pandas/_libs is where we keep our C extensions' code(and Cython files that compile into C extensions). There is also a couple of .pyx files in the pandas/io/sas folder, but they really should live in _libs too(I just haven't found the time to move them yet). The reason why we use these C extensions in pandas is for performance, and many other libraries like numpy do this too.
Even though, the files all compile down to C extensions, we actually have 3 different types of source files.
-
The .c and .h files. These tend to exist because we vendored C code from other libraries. They live in pandas/_libs/src and pandas/_libs/tslibs/src/datetime. Some of them compile into C extensions, like the parser(reads text files, used mainly for CSV reading and some other I/O functions) code and the JSON code. The json module is originally from ultrajson(https://github.com/ultrajson/ultrajson), but modified to read/write pandas objects. The parser is originally from https://github.com/WarrenWeckesser/textreader (IIRC).
Others are used by the Cython code(The datetime stuff we vendored from numpy, see https://github.com/numpy/numpy/blob/main/numpy/core/src/multiarray/datetime.c and https://github.com/numpy/numpy/blob/main/numpy/core/src/multiarray/datetime_strings.c). We also vendor khash(from https://github.com/attractivechaos/klib)
-
.pyx, .pxi, .pxd files. These are Cython files. You can read more about them here. https://cython.readthedocs.io/en/latest/src/userguide/language_basics.html#cython-file-types (.pyi files are the typing stubs)
-
.pxi.in These are templates for Cython files. We process them through something called Tempita to turn them into .pxi files. Tempita is actually kind of a dead project right now, but a copy of it lives on inside Cython. The official website appears to point to a dead link, but these docs look correct. (https://pyrocore.readthedocs.io/en/latest/tempita.html)
The reason why we use them is to compile functions with support for many dtypes. Normally, we would use fused types in Cython for this, but the khash code is of the form kh_{type}_t(like kh_int8_t), so we need to use templates to substitute the types in. So, whenever you seem something that interacts with the hashtable code, expect that there is a .pxi.in file somewhere.
Hopefully this explains everything.
If you're still a little confused about everything, feel free to ping, but don't worry about it too much.
Our current build system is pretty confusing and we're actually in the process of overhauling our build system to use meson, which should result in a cleaner build overall.
Comment From: jmferreirab
Thank you for the quick answer @lithomas1. If I may, I would still like more clarity on the "binding" process. An example may help illustrate this:
For example, when I call:
>>> s = pd.Series([2, np.nan, 5, -1, 0])
>>> s.cumsum()
0 2.0
1 NaN
2 7.0
3 6.0
4 6.0
dtype: float64
It seems that under the hood this:
-> Calls Series.cumsum(), defined in pandas/core/series.py,
-> Calls NDFrame.cumsum(), defined in pandas/core/generic.py, then,
-> Calls NDFrame._accum_func("cumsum", ...), then
--- some unclear steps that seem to resolve into code unreachable via vscode go to definition ----
-> Calls group_cumsum() (C function) defined in pandas/_libs/groupby.pyi as interface and implemented in pandas/_libs/groupby.pyx, but actually executed from pandas/_libs/groupby.cp37-win_amd64.pyd. This .pyd being the compiled C code that was translated into C from the .pyx with Cython. (This part item just an assumption, I could be wrong )
What are these "unclear" steps that bind the python code with the C extensions? Can you elaborate on the flow?
Not sure if this a good example, if there is a better one we could use, that would also be welcome.
Comment From: eli-schwartz
implemented in
pandas._libs.groupby.pyx, but actually executed frompandas._libs.groupby.cp37-win_amd64.pyd.
This is kind of a confusing way to look at it. The dot notation here mixes python import names with on-disk file extensions.
It's actually implemented in the source file and compiled binary file:
pandas/
└── _libs/
├── groupby.pyx # source file (will be translated into .c)
├── groupby.c # cythonized intermediate file (will be compiled)
└── groupby.cp37-win_amd64.pyd # binary file
Behind the scenes, a build system (setuptools, Meson) may actually choose to place the second and third files in a mirrored directory tree such as build/pandas/_libs/....... to keep build artifacts separate and avoid e.g. accidentally checking them into git -- that's not super important though.
This .pyd being the compiled C code that was translated into C from the .pyx with Cython. (This part is just an assumption, I could be wrong )
That is correct. :)
Comment From: jmferreirab
I have corrected the message so that the file paths actually use / instead of ..
If possible, I would still like and answer from the pandas devs on my last question please. How does NDFrame._accum_func("cumsum", ...) end up calling group_cumsum()? Where are the lines of code that set it up to point to that c function?
Comment From: lithomas1
@jmferreirab
--- some unclear steps that seem to resolve into code unreachable via vscode go to definition ----
-> Calls
group_cumsum()(C function) defined inpandas/_libs/groupby.pyias interface and implemented inpandas/_libs/groupby.pyx, but actually executed frompandas/_libs/groupby.cp37-win_amd64.pyd. This .pyd being the compiled C code that was translated into C from the .pyx with Cython. (This part item just an assumption, I could be wrong )
This is close, but not quite right. _accum_func is actually defined in generic.py here https://github.com/pandas-dev/pandas/blob/3d0d197cec32ed5ce30d28b922f329510c03f153/pandas/core/generic.py#L10842.
I dunno how to use VS code's debugger, but you can do this from the command line with pdb.
import pandas as pd
import numpy as np
import pdb
s = pd.Series([2, np.nan, 5, -1, 0])
pdb.run("s.cumsum()")
Now you can just keep spamming s (to step) and n to get to the end of a funciton. If you're a little lost, l (will print out a bit of source code around where you're at).
Having stepped through this code myself now, it looks like this function just calls into numpy and not our Cython code.
Comment From: lithomas1
If you want to interact with the C extensions, in my opinion, the JSON code is a good place to start.
We actually hand wrap the C code there, and you can access it from Python. (If you import pandas._libs.json, you get our json module, which basically works like the Python JSON module).
I wouldn't recommend trying to look at a Cython module for now. Cython does all the necessary stuff to transform Cython(which is basically Python code with some changes) to the C extension code. Also, the C code that is generated by Cython is usually not very human readable.
Comment From: lithomas1
If you do decide to debug the JSON code, remember to compile pandas with debug symbols on.
(See our debugging guide: https://pandas.pydata.org/docs/development/debugging_extensions.html)
Also, btw, I noticed that your extension module was compiled with Python 3.7. We've actually dropped support for Python 3.7, so you'll need 3.8+ to work on pandas.
Comment From: jmferreirab
It seems I took a bad example because as lithomas1 pointed out,
Having stepped through this code myself now, it looks like this function just calls into numpy and not our Cython code.
I have found a better example and in fact a solution to the sub-question of,
"How come it is binding to the c-code?"
Solution
Take the function:
>>> s = pd.Series([2, 5, 0])
>>> s.apply(lambda x: x*2)
0 4
1 10
2 0
Part of this function resolves as follows:
- Create a SeriesApply instance: https://github.com/pandas-dev/pandas/blob/3d0d197cec32ed5ce30d28b922f329510c03f153/pandas/core/series.py#L4547
- Resolve apply() to apply_standard() https://github.com/pandas-dev/pandas/blob/3d0d197cec32ed5ce30d28b922f329510c03f153/pandas/core/apply.py#L1001
- Within apply_standard() call a c-function lib.map_infer() https://github.com/pandas-dev/pandas/blob/3d0d197cec32ed5ce30d28b922f329510c03f153/pandas/core/apply.py#L1052
Now, how come that we bind in step 3 to a c-function from python?
lib.map_infer comes from the lib*.pyd file that cython created and that behaves like a dll; albeit its interface is defined in the lib.pyi, and its implementation and docs within the lib.pyx. The following code confirms this:
>>> import importlib.util
>>> lib.map_infer.__module__
'pandas._libs.lib'
>>> lib.map_infer.__doc__
'Substitute for np.vectorize with pandas-friendly dtype inference....'
>>> importlib.util.find_spec(lib.map_infer.__module__)
ModuleSpec(
name='pandas._libs.lib',
loader=<_frozen_importlib_external.ExtensionFileLoader object at 0x000001917818B108>,
origin='...\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages\\pandas\\_libs\\lib.cp37-win_amd64.pyd')
But how does the lib*.pyd end up getting imported?
With the proper setup, when working with cython for c-extensions, all you need is something equivalent to:
https://github.com/pandas-dev/pandas/blob/3d0d197cec32ed5ce30d28b922f329510c03f153/pandas/core/apply.py#L25
That will automatically point to the matching .pyd in that path, and not the .pyx or .pyi because that's how the internal pandas ExtensionFileLoader that handles imports in python works. Details here.
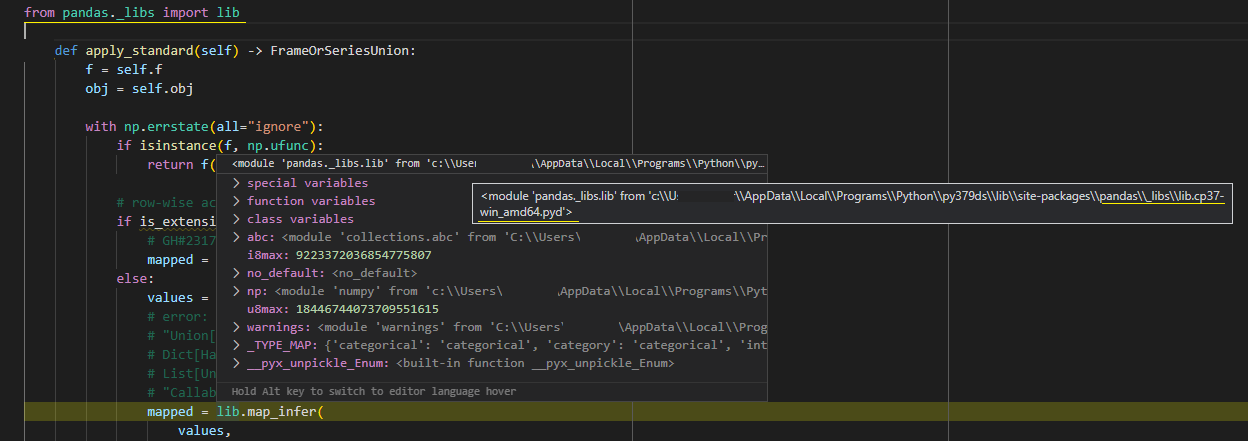
Hopefully I reached a valid answer now, corrections are welcome if I gave any misinformation. Along with the explanations from earlier regarding the file types involved and the build system from lithomas1 and eli-schwartz, I think we are good. If the information is right, could you please close the issue?
Comment From: avm19
This is a very nice thread, especially lithomas1' first response. It will help inexperienced contributors if a link to this discussion (or a re-worked version of it) is included into Contributing to Pandas Guide.