Research
-
[X] I have searched the [pandas] tag on StackOverflow for similar questions.
-
[X] I have asked my usage related question on StackOverflow.
Link to question on StackOverflow
https://stackoverflow.com/questions/74417232/pandas-groupy-aggregate-does-not-see-column
Question about pandas
Hello guys, I am not getting the difference about .agg and .agregate behavir on this situation. I´ve posted it on stackoverflow an time ago but no one helped me yet.
I am working on a huge database where I did a pandas apply to categorize the type of cliente based on the type of the product he consumed:
Sample DF:
import pandas as pd
columns = pd.MultiIndex(
levels=[['id', 'product', 'type'], ['', 'afiliates', 'giftcards']],
codes=[[0, 1, 1, 2], [0, 1, 2, 0]],
names=[None, 'product'],
)
base = pd.DataFrame([[2, 1, 0, 'afiliates'], [4, 0, 1, 'gift']], columns=columns)
So far, so good. If I run an groupby.agg, I get these results:
results = base[['type','id']].groupby(['type'], dropna=False).agg('count')
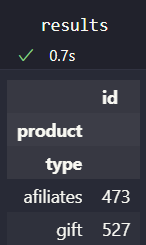
but if instead of agg I try an aggregate, it does not work.
results = base[['type','id']].groupby(['type']).aggregate({'id': 'count'})
Output exceeds the size limit. Open the full output data in a text editor
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[10], line 2
1 #results = base[['type','id']].groupby(['type'], dropna=False).agg('count')
----> 2 results = base[['type','id']].groupby(['type']).aggregate({'id': 'count'})
File c:\Users\fabio\AppData\Local\Programs\Python\Python311\Lib\site-packages\pandas\core\groupby\generic.py:894, in DataFrameGroupBy.aggregate(self, func, engine, engine_kwargs, *args, **kwargs)
891 func = maybe_mangle_lambdas(func)
893 op = GroupByApply(self, func, args, kwargs)
--> 894 result = op.agg()
895 if not is_dict_like(func) and result is not None:
896 return result
File c:\Users\fabio\AppData\Local\Programs\Python\Python311\Lib\site-packages\pandas\core\apply.py:169, in Apply.agg(self)
166 return self.apply_str()
168 if is_dict_like(arg):
--> 169 return self.agg_dict_like()
170 elif is_list_like(arg):
171 # we require a list, but not a 'str'
172 return self.agg_list_like()
File c:\Users\fabio\AppData\Local\Programs\Python\Python311\Lib\site-packages\pandas\core\apply.py:478, in Apply.agg_dict_like(self)
475 selected_obj = obj._selected_obj
476 selection = obj._selection
--> 478 arg = self.normalize_dictlike_arg("agg", selected_obj, arg)
...
606 # eg. {'A' : ['mean']}, normalize all to
607 # be list-likes
608 # Cannot use func.values() because arg may be a Series
KeyError: "Column(s) ['id'] do not exist"
What am I missing?
Comment From: frbelotto
I believe is something related to the "tuple" columns due to unstack, but I couldn't make it work!
Comment From: phofl
Can you trim down your example? Please post only necessary steps to reproduce and reduce the size of your DataFrames. Also, which pandas version are you on?
Comment From: frbelotto
Hello I've posted all the codes needed to create a data sample and codes for execution.
I am using 1.5.2
Comment From: phofl
Yes, but your example is huge, please reduce your code to the smallest code snippet possible to reproduce
Comment From: frbelotto
I´ve removed all code lines I could without breaking the reproducible steps.
Comment From: MarcoGorelli
your dataframe has 1000 rows - is that necessary for the example to fail? does it also fail with, say, 5 rows?
Comment From: frbelotto
As it creating a sample Df for exemplifying the question, I've just set a number of rows to seem like a real dataframe. Adjust the code to just 5 rows would make it smaller, so I thought it wasn't something to worry.
Comment From: MarcoGorelli
I think the issue is just that base columns are a multiindex - a simple reproducible example would be a small dataframe with multiindex columns which throws the above error
Comment From: frbelotto
I agree that it must be something related to the multiindex, that is way I keep all track of how I've "constructed" the base Df.
I've tried to change the last "group by aggregate" for columns with names composed of tuples (the way I've learned to access columns from multiindex), but I couldn't get it to work.
Comment From: frbelotto
The columns names appers in this form with a base.info()
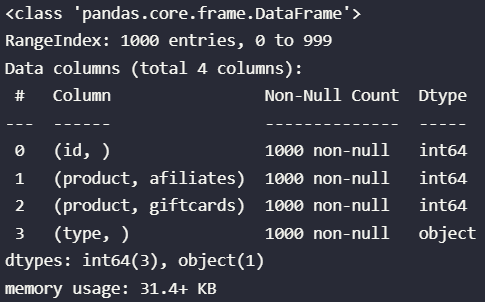
So I´ve tried using this code
results = base[['(type, )','(id, )']].groupby(['(type, )']).aggregate({'(id, )': 'count'})
The error message changes but still does not work
Output exceeds the [size limit](command:workbench.action.openSettings?[). Open the full output data [in a text editor](command:workbench.action.openLargeOutput?5ce7f723-4688-4692-a679-32f940231fe3)
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[8], line 2
1 #results = base[['type','id']].groupby(['type'], dropna=False).agg('count')
----> 2 results = base[['(type, )','(id, )']].groupby(['(type, )']).aggregate({'(id, )': 'count'})
3 #results = base[['type','id']].groupby(['type']).aggregate({'id': 'count'})
File c:\Users\fabio\AppData\Local\Programs\Python\Python311\Lib\site-packages\pandas\core\frame.py:3811, in DataFrame.__getitem__(self, key)
3809 if is_iterator(key):
3810 key = list(key)
-> 3811 indexer = self.columns._get_indexer_strict(key, "columns")[1]
3813 # take() does not accept boolean indexers
3814 if getattr(indexer, "dtype", None) == bool:
File c:\Users\fabio\AppData\Local\Programs\Python\Python311\Lib\site-packages\pandas\core\indexes\multi.py:2623, in MultiIndex._get_indexer_strict(self, key, axis_name)
2620 if len(keyarr) and not isinstance(keyarr[0], tuple):
2621 indexer = self._get_indexer_level_0(keyarr)
-> 2623 self._raise_if_missing(key, indexer, axis_name)
2624 return self[indexer], indexer
2626 return super()._get_indexer_strict(key, axis_name)
File c:\Users\fabio\AppData\Local\Programs\Python\Python311\Lib\site-packages\pandas\core\indexes\multi.py:2641, in MultiIndex._raise_if_missing(self, key, indexer, axis_name)
2639 cmask = check == -1
2640 if cmask.any():
-> 2641 raise KeyError(f"{keyarr[cmask]} not in index")
...
2642 # We get here when levels still contain values which are not
2643 # actually in Index anymore
2644 raise KeyError(f"{keyarr} not in index")
KeyError: "['(type, )' '(id, )'] not in index"
Comment From: MarcoGorelli
This doesn't look right:
https://github.com/pandas-dev/pandas/blob/073e48b7cfe85b7a1173a275296471b51276826d/pandas/tests/tools/test_to_datetime.py#L142-L148
If the input is invalid, errors='ignore' should return the input
Comment From: rhshadrach
@frbelotto - regarding a minimal reproducible example, from the discussion above it seems to me the issue is the line:
results = base[['type','id']].groupby(['type']).aggregate({'id': 'count'})
So for a minimal example, all the steps that go into constructing base are very likely unnecessary, and only presenting base, constructed directly, is sufficient. Also, being able to see all the data (e.g. 2 rows) goes a long way in understanding the issue, assuming it can be reproduced like that.
columns = pd.MultiIndex(
levels=[['id', 'product', 'type'], ['', 'afiliates', 'giftcards']],
codes=[[0, 1, 1, 2], [0, 1, 2, 0]],
names=[None, 'product'],
)
base = pd.DataFrame([[2, 1, 0, 'afiliates'], [4, 0, 1, 'gift']], columns=columns)
print(base)
# id product type
# product afiliates giftcards
# 0 2 1 0 afiliates
# 1 4 0 1 gift
results = base[['type','id']].groupby(['type']).aggregate({'id': 'count'})
Comment From: frbelotto
This doesn't look right:
https://github.com/pandas-dev/pandas/blob/073e48b7cfe85b7a1173a275296471b51276826d/pandas/tests/tools/test_to_datetime.py#L142-L148
If the input is invalid,
errors='ignore'should return the input
Was this message for this discussion?
Comment From: frbelotto
columns = pd.MultiIndex( levels=[['id', 'product', 'type'], ['', 'afiliates', 'giftcards']], codes=[[0, 1, 1, 2], [0, 1, 2, 0]], names=[None, 'product'], ) base = pd.DataFrame([[2, 1, 0, 'afiliates'], [4, 0, 1, 'gift']], columns=columns) print(base)
id product type
product afiliates giftcards
0 2 1 0 afiliates
1 4 0 1 gift
results = base[['type','id']].groupby(['type']).aggregate({'id': 'count'})
Thanks. I am not really good handling multiindex, I really didn´t know how to recreate it without all steps that I´ve made. I will update the code above using your code given it seems to fully reproduce the error.
Comment From: MarcoGorelli
Was this message for this discussion?
so sorry, had too many tabs open 😳
Comment From: rhshadrach
@frbelotto - you can see how to access your columns using:
print(base.columns.tolist())
[('id', ''), ('product', 'afiliates'), ('product', 'giftcards'), ('type', '')]
When you have a MultiIndex for columns, you need to specify each level as a tuple. So you can do:
base[['type','id']].groupby(['type']).aggregate({('id', ''): 'count'})
Regarding the title of this issue - agg and aggregate are aliases, they do not behave differently.
Comment From: frbelotto
Thanks! That worked! It was really confusing given that the "base[['type','id']].groupby(['type'])" are "simple" columns names and the aggregate({('id', '') uses the tuple name.
Comment From: rhshadrach
I suppose there is a bit of an oddity here - why can you do base[['id']] but not specify {'id': ...} in agg? The reason is because column selection can return multiple columns (e.g. in the example here, base[['product']] returns a DataFrame with two columns), whereas agg must have one column and one column only. Thus, it is necessary to specify all levels in agg.
We could make it so that if specifying a subset of levels uniquely identifies the column it would work in agg, but I'm not certain this is a good idea.
Comment From: frbelotto
Got it. Thanks. Now I understood the reason for each behavior, I don't seem any change as needed.