from collections import OrderedDict
import pandas as pd
data = OrderedDict([('ele2', OrderedDict([('b', 1), ('a', 2)])),
('ele1', OrderedDict([('b', 2), ('a', 5)]))])
pd.DataFrame(data)
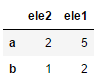
Problem description
The output shows the rows get sorted.
Expected Output
When constructing a df with OrderedDicts I would expect the order in columns and rows to stay the same.
Output of pd.show_versions()
Comment From: jreback
you can have a look but i don’t think a nested dict that is ordered is respected. problem is you have have different keys in each row and so keys are accumulated via Index.union which sorts it would be non performant otherwise
but if u want to see pls do
Comment From: xuancong84
I agree with OP, there is some design flaw and bug in the low-level DataFrame construction code that needs to be fixed. My examples below illustrates the problem:
-
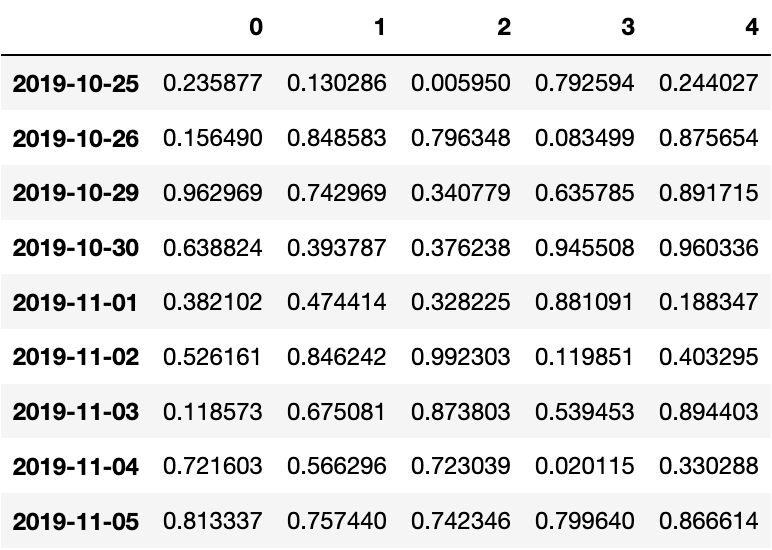
The following code shows the normal behaviour for using dict to construct row data, the result is correct and as expected:
pd.DataFrame.from_dict(OrderedDict([(d, {0:0} if ii in [2,3,6] else {i:np.random.random() for i in range(5)}) for ii,d in enumerate(pd.date_range(start='2019-10-25', end='2019-11-05'))]), orient='index') -
The 1st design flaw lies in when you pass in empty dict, the row gets omitted:
pd.DataFrame.from_dict(OrderedDict([(d, {} if ii in [2,3,6] else {i:np.random.random() for i in range(5)}) for ii,d in enumerate(pd.date_range(start='2019-10-25', end='2019-11-05'))]), orient='index') -
The 2nd design bug lies in that even when you use OrderedDict, you still cannot keep all the rows in the right order if the dictionary does not starts with the same key,
pd.DataFrame.from_dict(OrderedDict([(d, {4:0} if ii in [2,3,6] else {i:np.random.random() for i in range(5)}) for ii,d in enumerate(pd.date_range(start='2019-10-25', end='2019-11-05'))]), orient='index')
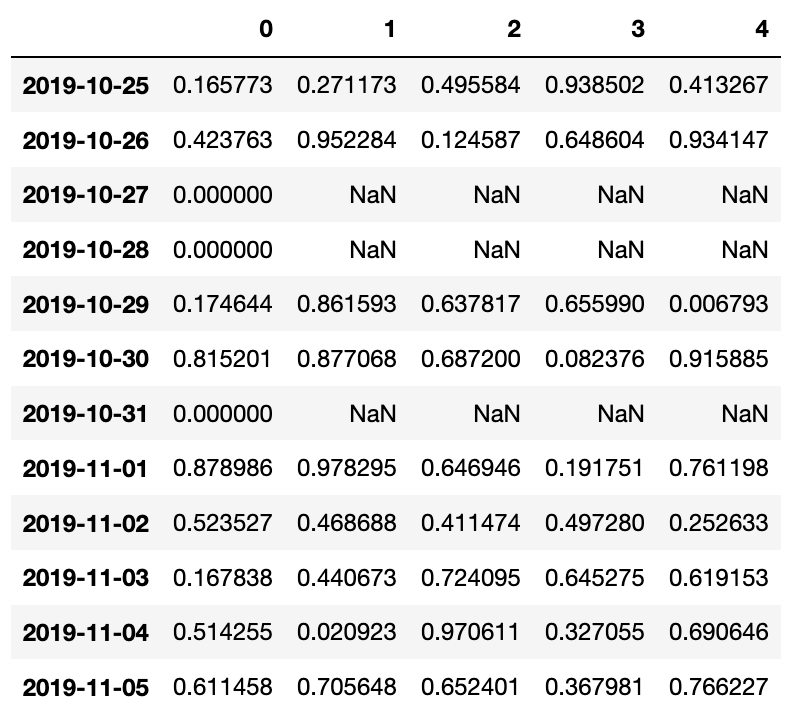

Note the last 3 rows are out of order.
Comment From: mroeschke
Looks to work on master now. Could use a test
In [19]: from collections import OrderedDict
...: import pandas as pd
...: data = OrderedDict([('ele2', OrderedDict([('b', 1), ('a', 2)])),
...: ('ele1', OrderedDict([('b', 2), ('a', 5)]))])
...: pd.DataFrame(data)
Out[19]:
ele2 ele1
b 1 2
a 2 5