-
[x] I have checked that this issue has not already been reported.
-
[x] I have confirmed this bug exists on the latest version of pandas.
-
[ ] (optional) I have confirmed this bug exists on the master branch of pandas.
Code Sample, a copy-pastable example
import pandas as pd
import numpy as np
import random
# Dataset
ts = pd.DatetimeIndex([pd.Timestamp('2021/01/01 00:30'),
pd.Timestamp('2021/01/01 00:45'),
pd.Timestamp('2021/01/01 02:00'),
pd.Timestamp('2021/01/01 03:50'),
pd.Timestamp('2021/01/01 05:00')])
length = len(ts)
random.seed(1)
value = random.sample(range(1, length+1), length)
df = pd.DataFrame({'value': value, 'ts': ts})
df['td'] = df['ts'] - df['ts'].shift(1, fill_value=ts[0]-pd.Timedelta('1h'))
df['amount'] = df['value']*10
df.loc[:2,'grps'] = 'a'
df.loc[2:,'grps'] = 'b'
In [16]: df
Out[16]:
value ts td amount grps
0 2 2021-01-01 00:30:00 0 days 01:00:00 20 a
1 1 2021-01-01 00:45:00 0 days 00:15:00 10 a
2 5 2021-01-01 02:00:00 0 days 01:15:00 50 b
3 4 2021-01-01 03:50:00 0 days 01:50:00 40 b
4 3 2021-01-01 05:00:00 0 days 01:10:00 30 b
# cumsum and Timedelta work when used through pd.Series
df['td'].cumsum()
# cumsum and Timedelta do not work when used in groupby with named aggregation
agg_rules = {'td':('td', 'cumsum')}
res = df.groupby('grps').agg(**agg_rules)
Error message that is returned
res = df.groupby('grps').agg(**agg_rules)
Traceback (most recent call last):
File "<ipython-input-14-c0f4606d675a>", line 2, in <module>
res = df.groupby('grps').agg(**agg_rules)
File "/home/pierre/anaconda3/lib/python3.8/site-packages/pandas/core/groupby/generic.py", line 945, in aggregate
result, how = aggregate(self, func, *args, **kwargs)
File "/home/pierre/anaconda3/lib/python3.8/site-packages/pandas/core/aggregation.py", line 582, in aggregate
return agg_dict_like(obj, arg, _axis), True
File "/home/pierre/anaconda3/lib/python3.8/site-packages/pandas/core/aggregation.py", line 768, in agg_dict_like
results = {key: obj._gotitem(key, ndim=1).agg(how) for key, how in arg.items()}
File "/home/pierre/anaconda3/lib/python3.8/site-packages/pandas/core/aggregation.py", line 768, in <dictcomp>
results = {key: obj._gotitem(key, ndim=1).agg(how) for key, how in arg.items()}
File "/home/pierre/anaconda3/lib/python3.8/site-packages/pandas/core/groupby/generic.py", line 247, in aggregate
ret = self._aggregate_multiple_funcs(func)
File "/home/pierre/anaconda3/lib/python3.8/site-packages/pandas/core/groupby/generic.py", line 315, in _aggregate_multiple_funcs
results[base.OutputKey(label=name, position=idx)] = obj.aggregate(func)
File "/home/pierre/anaconda3/lib/python3.8/site-packages/pandas/core/groupby/generic.py", line 241, in aggregate
return getattr(self, func)(*args, **kwargs)
File "/home/pierre/anaconda3/lib/python3.8/site-packages/pandas/core/groupby/groupby.py", line 2497, in cumsum
return self._cython_transform("cumsum", **kwargs)
File "/home/pierre/anaconda3/lib/python3.8/site-packages/pandas/core/groupby/groupby.py", line 996, in _cython_transform
raise DataError("No numeric types to aggregate")
DataError: No numeric types to aggregate
Problem description
Cumsum works with Timedelta in some workflows, but for some other workflows (groupby, named aggregation) it does not.
Output of pd.show_versions()
Comment From: phofl
The error is raised, because cumsum in groupby sets numeric_only=True as default. I think the correct way to call this is:
agg_rules = {'td': 'cumsum'}
res = df.groupby('grps').agg(agg_rules, **{"numeric_only": False})
but the error persists, because the kwargs are not passed through.
Comment From: WillAyd
Looks like this is fixed on main. Could use a test
Comment From: seanjedi
I can take this and work on making a test
Comment From: seanjedi
take
Comment From: seanjedi
@WillAyd Are the results of the two examples above supposed to be the same?
I am trying to create a test utilizing some of the same logic as the sample above, however when I check the results, the results are different
Is this a bug?
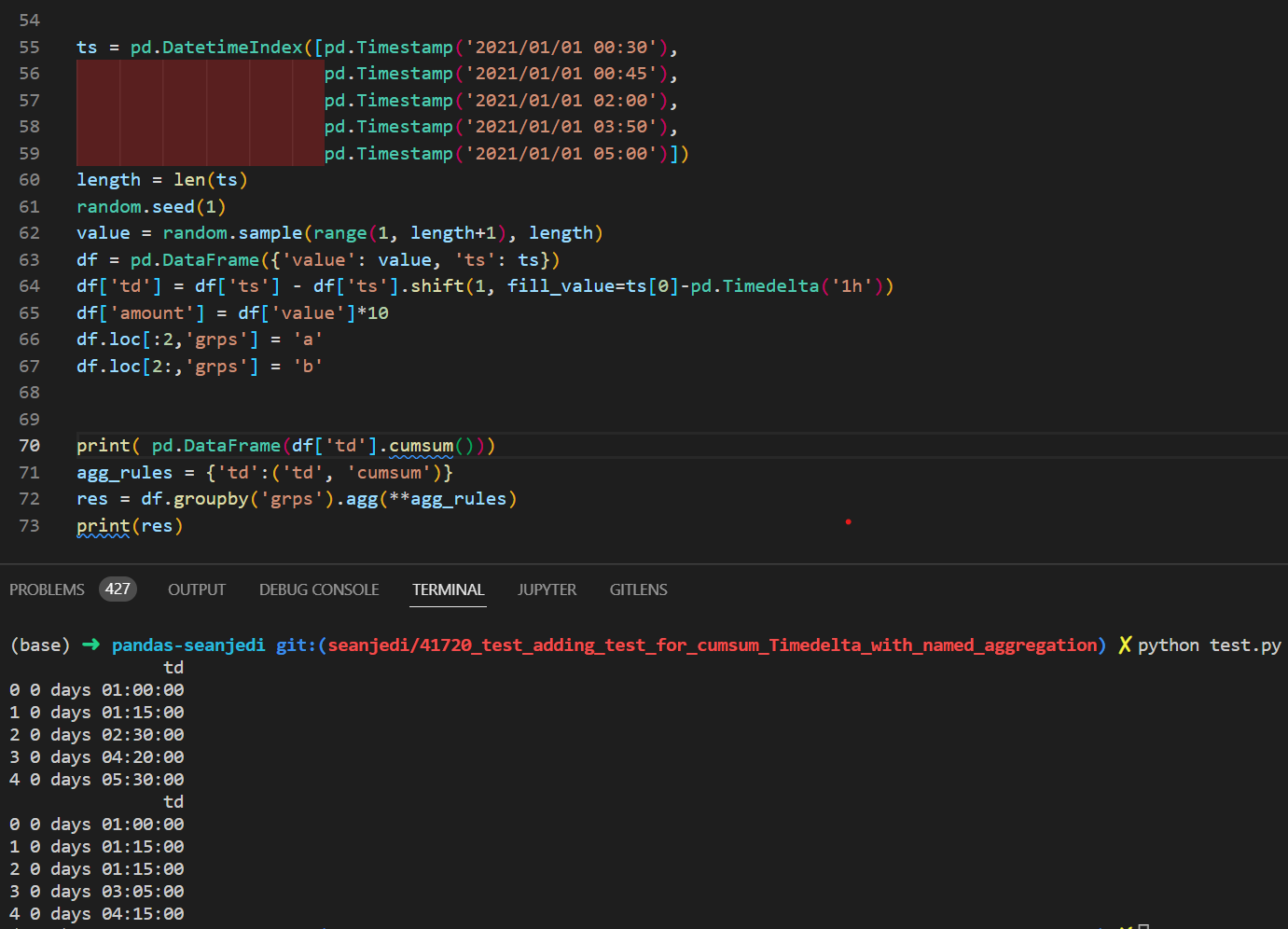
Comment From: WillAyd
No they aren't the same - the first is just a normal cumulative whereas the latter is a groupby. So should respect the groupings
Comment From: seanjedi
@WillAyd Added a new test here: https://github.com/pandas-dev/pandas/pull/50033 Im sure there will be a lot of things I can improve, as this is my first test with Pandas 😅