Pandas version checks
-
[X] I have checked that this issue has not already been reported.
-
[X] I have confirmed this bug exists on the latest version of pandas.
-
[ ] I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
import pandas as pd
import os
df = pd.DataFrame({("A", 1): [0], ("", 1): [1]})
df.to_excel(os.path.expanduser("merge_empty.xlsx"), merge_cells=True)
Issue Description
When an empty string is present in a MultiIndex header, to_excel will treat it as the merge it incorrectly with the previous column entry on that level. In the example above, the first and second columns should not merge because their first level entries are different.
See the screenshot below:
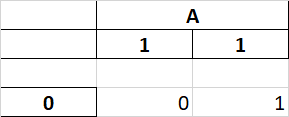
The issue arises from the use of an empty string as the sentinel in MultiIndex.format
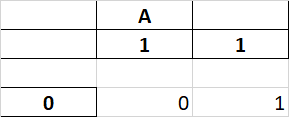
Expected Behavior
The column header should not merge past empty strings.
See the screenshot below:
Installed Versions
Comment From: tehunter
The following code snippet should be able to replace level_lengths so that to_excel handles empty strings correctly
(In pandas.io.formats.excel)
class ExcelFormatter:
# ...
def _format_header_mi(...):
# ...
level_lengths = pandas.io.formats.format.get_level_lengths([[False] + [lev_codes[i] == lev_codes[i+1] for i in range(len(lev_codes)-1)] for lev,lev_codes in zip(columns.levels, columns.codes)], sentinel=True)
Rather than getting level lengths based on the output of columns.format, it gets the level lengths from the column codes directly.
I haven't tested multi-index rows, but it's probably the same problem and solution.
Comment From: tehunter
take
Comment From: tehunter
Looking into this more, there's more ramifications than expected. The problem I discussed above references the behavior when writing. However, similar behavior exists when reading.
For the following Excel sheet, the reader calls a fill_mi_header function which will replace empty header cells with the preceding non-empty value. In other words, it will be read in as DataFrame({("A", "1"): [0], ("A", "1"): [0]})
If I fix the problem addressed in the original issue, then reading the exported sheet will not return the same dataframe as the one that was written. Should the read and write functions have options on how to handle empty string header cells?
Comment From: ariabtsev
Hello, any update on this bug?