Pandas version checks
-
[X] I have checked that this issue has not already been reported.
-
[X] I have confirmed this bug exists on the latest version of pandas.
-
[X] I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
import numpy as np
import pandas as pd
df = pd.DataFrame({'idx_L1': ['Level_1'] * 10 + ['Level_2'] * 10 + ['Level_3'] * 10,
'idx_L2': ([1] * 5 + [2] * 5 + [3] * 5) * 2,
'vals': np.arange(30)})
df = df.set_index(['idx_L1', 'idx_L2'])
df.groupby(level=['idx_L1', 'idx_L2']).rolling(3).sum()
Results in:
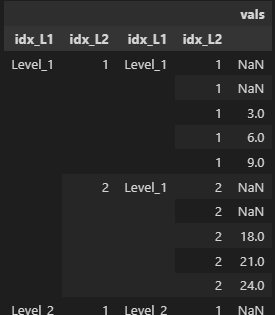
Issue Description
When applying a rolling operation on a dataframe grouped by a multi-index, the indexes are duplicated in the resulting dataframe.
Notice that this bug has already been reported in the past: https://github.com/pandas-dev/pandas/issues/15350
Expected Behavior
The expected behavior is that the index is not duplicated.
This is the behavior when using apply instead of rolling directly, but this approach is slower compared to the first:
import numpy as np
import pandas as pd
df = pd.DataFrame({'idx_L1': ['Level_1'] * 10 + ['Level_2'] * 10 + ['Level_3'] * 10,
'idx_L2': ([1] * 5 + [2] * 5 + [3] * 5) * 2,
'vals': np.arange(30)})
df = df.set_index(['idx_L1', 'idx_L2'])
df.groupby(level=['idx_L1', 'idx_L2'], group_keys=False)[['vals']].apply(lambda x: x.rolling(3).sum())
Results in:
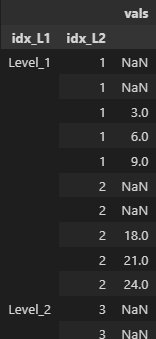
Installed Versions
Comment From: phofl
Hi, thanks for your report.
This is a duplicate, see #47181 for example
Comment From: dvfariaf-bops
Hi, thanks for the quick response.
Now that I read the linked issues I understand better the purpose of keeping all multi indexes (e.g. do not remove an index date), but having duplicate indexes without any warning is somewhat unexpected and could lead to bugs.
IMO having a parameter that could control this (like group_keys) would be very useful.