Pandas version checks
-
[X] I have checked that this issue has not already been reported.
-
[X] I have confirmed this bug exists on the latest version of pandas.
-
[ ] I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
reference/source for this code example: https://github.com/pandas-dev/pandas/issues/37577
import pandas as pd
from dataclasses import dataclass
@dataclass
class Record:
id: int
name: str
constant: float
df = pd.DataFrame([
Record(0, 'Landau', 3.1415926),
Record(1, 'Kapitsa', 2.718281828459045),
Record(2, 'Bogolyubov', 6.62607015),
])
print(df.dtypes)
Issue Description
I would expect that the dtype from the dataclass is inherited / used in pandas as well.
id int64 name string constant float64 dtype: object
Expected Behavior
id int64 name string constant float64 dtype: object
Installed Versions
Comment From: phofl
Hi, thanks for your report. We don't use those dtypes, same with NamedTuple, but even if we would, str maps to object, the panda string dtype can be set with „string“ not str
Edit: Sorry initial response was only half-correct
Comment From: butterbach
I actually thought so and but don't get why or is it basically a feature request because Pandas just supports string since 1.0?
For other complex datatypes I might get that behaviour - but getting out of pandas again causes issues like ending up getting a void type.
Comment From: butterbach
@phofl: Sorry to highlight you personally, but I can see that str maps to object in pandas but I can just assume that this was implemented before pandas even had the dtype "string" which is exactly the same as str in Python, isn't it?
What is the reason not to change the mapping? I just want to understand the reason. I get it that object is the default for all other datatypes that are not supported.
When I read the first paragraph of the pandas documentation about the dtype "string", I would assume it should be the opposite:
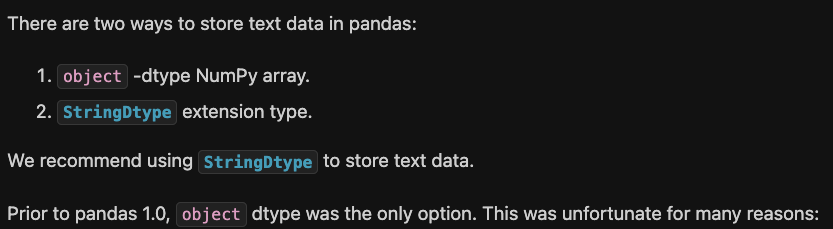
And specifying str in a dataclass instead of Any (?) is close to the pandas recommendations to actively set dtype=string (series examples in the pandas docs). In this case it should be taken into account by the DataFrame generator.