I've code which run fine about ~10 month ago and now fails due to running out of memory. The code basically does this:
groups = [[1,2,3][222,333,444, 555], ...] # from a 1.4MB json file
# about 30k such groups, results in ~70k replacements
for replace_list in groups:
replacement = sorted(replace_list)[0]
for replace_id in replace_list:
if replace_id == replacement:
continue
replace_dict[replace_id] = replacement
# len(_col) == 974757
_col = df[column].astype("int64")
_col.replace(replace_dict, inplace=True)
I've now split the replacement_dict into 2k chunks and and this works (takes about 20 seconds for each chunk).
Comment From: jreback
can you provide the file, pandas, numpy version that it was better on and what you are trying on now?
also, try wi/o the in-place operation
Comment From: jankatins
The replacement file is no problem, but the dataframe is internal and about 400MB csv unziped :-(
Now I do it similar to this:
groups = [[1,2,3][222,333,444, 555], ...] # from a 1.4MB json file
# about 30k such groups, results in ~70k replacements
count = 0
_col = df[column].astype("int64")
replace_dict = {}
for replace_list in groups:
count +=1
replacement = sorted(replace_list)[0]
for replace_id in replace_list:
if replace_id == replacement:
continue
replace_dict[replace_id] = replacement
if count > 2000:
_col = _col.replace(replace_dict)
replace_dict = {}
count = 0
_col = _col.replace(replace_dict) # for the last chunk
This works (takes about 11min) and 4.7GB of RAM are in use.
pandas._np_version
Out[3]: '1.8.0'
pandas.__version__
Out[4]: '0.13.1-489-g7ffa655'
I don't remember the numpy/pandas version from 10 month ago (The replacement file was generated on 17.05.2013, so during that week it worked) :-( It was probably whatever was on pandas master and the latest numpy release (I compile pandas from head and install numpy from cgolhlkes installers).
Comment From: jreback
@cpcloud ?
Comment From: dsm054
Something seems strange here.
@JanSchulz: how long does _col.apply(lambda x: replace_dict.get(x, x)) take?
Comment From: jankatins
WTF:
replacements_by_XXX.json (16:35:42): groups: 31612 replacements: 77846 => 1.36s
replacements_by_XXXY.json (16:35:43): groups: 19576 replacements: 33845 => 1.03s
replacements_manual.json (16:35:44): groups: 16 replacements: 17 => 864ms
Wall time: 3.26 s
This took 20min with the above "2k chunks" code.
Comment From: jreback
@JanSchulz I don't understand your problem exactly, but instead of replacing, why wouldn't you use these as indexers.
e.g. say you are replacing string to numbers; just construct a list (or series) of the strings, then
do s.take(numbers) (or s.iloc)?
will be orders of magnitude faster
Comment From: dsm054
@JanSchulz: are those the numbers you get when you use the apply/get combination?
@jreback: I think the issue is that the following doesn't feel right at all:
>>> to_replace = {i: 10**7+i for i in range(10**6)}
>>> series_length = 10**3
>>> col = pd.Series(np.random.randint(0, 10**6, series_length))
>>>
>>> %time slow = col.replace(to_replace)
CPU times: user 30 s, sys: 0 ns, total: 30 s
Wall time: 30 s
>>> %time fast = col.apply(lambda x: to_replace.get(x,x))
CPU times: user 4 ms, sys: 0 ns, total: 4 ms
Wall time: 1.53 ms
>>>
>>> (slow == fast).all()
True
We should be getting O(n) values * O(1) lookup, making this very fast, and we're not. [Okay, I haven't varied the parameters enough to pick up the actual scaling -- could just be a really big constant, from what I've shown.]
Comment From: jreback
hmm.....seems doing lots of work inside....
if you do this:
df = DataFrame({ 0 : col })
df.replace({ 0 : to_replace })
much faster....
prob a bug
Comment From: dsm054
I don't actually trust {0: to_replace} at the moment; see the discussion in #6689.
Comment From: cpcloud
this is very weird ... looking now
Comment From: cpcloud
prun of @dsm054's example shows that BlockManager.replace_list is to blame...figuring out the line ... lprun 1.0b3 breaks with newest ipython :cry:
Comment From: jankatins
@jreback each row in my data set has a "owner" and but sometimes (actually quite a lot of times) one owner has received several IDs and in that step I want to merge them into one. So in the final dataframe, the ID has to be set to the right (or at least to only one) value, so that I can df.groupby("id").
The shorter numbers are from the apply/get (2 seconds vs 20 mins from "chunked replace").
Comment From: jankatins
Anyway: the initial problem is not so much the time it takes but that it now takes much more memory than in last year with ~0.11.
Comment From: dsm054
I'd bet a shiny penny (now a collector's item in Canada) that the time and memory issues aren't independent.
Comment From: cpcloud
Time seems to be linear in the number of keys
if __name__ == '__main__':
import time
import numpy as np
from pandas import Series
start = 1
stop = 10 ** 6 + 1
step = 10 ** 5
sizes = np.arange(start, stop, step)
to_rep = {n: {i: 10 ** 5 + i for i in range(n)} for n in sizes}
col = Series(np.random.randint(0, 10 ** 6, size=10 ** 3))
times = Series(dtype=float, index=to_rep.keys())
for k, v in to_rep.iteritems():
tic = time.time()
col.replace(v)
toc = time.time() - tic
times[k] = toc
times.plot(ax=ax)
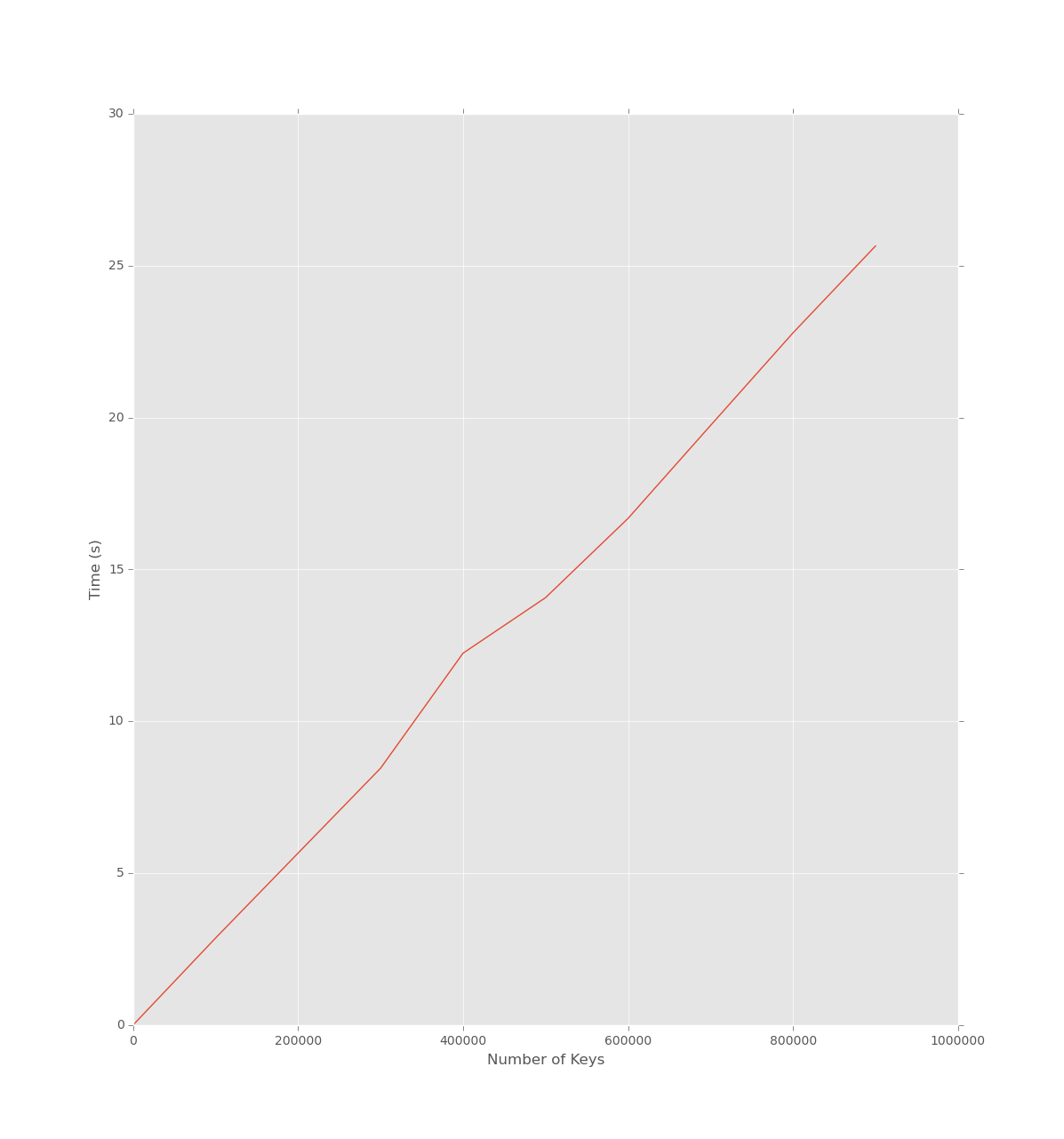
Comment From: dsm054
I think you can see the linearity in the code. Suppressing irrelevant detail, the structure looks like
for blk in self.blocks:
for i, (s, d) in enumerate(zip(src_list, dest_list)):
result = blk.replace(args)
and so it calls a replace (or a putmask on the non-object branch) for every key, value pair. It looks like we're trying to leverage numpy to speed things up. That might be good in the few-keyval long array regime, but it's going to be beaten by a simple listcomp + dict lookup pretty quickly in others.
Comment From: cpcloud
Yep .... was just looking at that block can't really get too deep into it right now can look this evening.
Comment From: jreback
@cpcloud any luck with this?
Comment From: cpcloud
I haven't really looked at this. Getting the dtype issue fixed from #6689 more important i think ... i'm actually working on the that right now
Comment From: cpcloud
I've just done %memit between v0.11.0 and master and I can't see any kind of memory usage difference between these two commits.
Commits between the date provided by @JanSchulz and the v0.11.0 tag date (2013-04-22):
git log --oneline --no-merges --after={2013-04-22} --before={2013-05-17} --name-only
shows
f9eea30 RLS: Version 0.11
RELEASE.rst
doc/source/v0.11.0.txt
setup.py
f24b923 BUG: respect passed chunksize in read_csv when using get_chunk function. close #3406
RELEASE.rst
pandas/io/parsers.py
pandas/io/tests/test_parsers.py
d385d25 DOC: Adding parameters to frequencies, offsets (issue #2916)
pandas/tseries/frequencies.py
pandas/tseries/offsets.py
so it looks like nothing was touched regarding DataFrame.replace() (e.g., making it faster)
memit numero uno
v0.11.0
In [5]: pd.version.version
Out[5]: '0.11.0'
In [6]: paste
from pandas import Series
from numpy.random import randint
def rep_test():
s = Series(randint(10 ** 6, size=1000))
to_rep = {i: 10 ** 5 + i for i in range(10 ** 6)}
return s.replace(to_rep)
## -- End pasted text --
In [7]: %load_ext memory_profiler
In [8]: %memit rep_test()
peak memory: 1511.13 MiB, increment: 1422.84 MiB
y dos
In [3]: pd.version.version
Out[4]: '0.13.1-594-ge84efe5'
In [4]: %memit rep_test()
peak memory: 1381.62 MiB, increment: 1287.60 MiB
Comment From: cpcloud
Wow changing rep_test from this
def rep_test():
s = Series(randint(10 ** 6, size=1e3))
to_rep = {i: 10 ** 5 + i for i in range(10 ** 6)}
return s.replace(to_rep)
to
def rep_test():
s = Series(randint(10 ** 6, size=1e6))
to_rep = {i: 10 ** 5 + i for i in range(7 * 10 ** 4)}
return s.replace(to_rep)
crashes the interpreter. Back to the drawing board.
Comment From: cpcloud
ah i see the issue ... replace with dicts is now using replace list ... before the ndarray refactor Series had its own replace method that was different than the generic one. some nice stuff in the series replace method i may move some of that old code into current replace
Comment From: cpcloud
@JanSchulz can you provide a sample dataset that is a faithful "reproduction" of the one you're using? Meaning, enough info so that I can create a fake frame to test the issue with. I still get huge memory usage for replace even in v0.11.0 so i'm not sure where your issue lies. The issue is that when there's an overlap between keys and values a mask is built up for each replacement value and stored in a dict which is where the bulk of the memory usage is coming from, this is how it worked in v0.11.0, so i'm not sure why you weren't seeing this before
Comment From: cpcloud
@JanSchulz also are you using the exact same dataset to test this as when you used this with pandas 0.11?
Comment From: jankatins
The sample is basically this:
record, authorid
1, 1111111111
2, 2222222222
3, 3333333333
4, 4444444444
5, 5555555555
6, 6666666666
7, 1111111111 # a second entry of author 111111111
....[about 1mio of such lines]...
The replacements would then replace 1111111111 with 2222222222 or 4444444444 and 5555555555 with 6666666666 ("merge two or more authors into one"), but leave some authorids alone. I've about 70k such replacements. The author IDs were int64.
The data is the same, only the mergelist was slightly different (found about 20 "manual" merges, the automatic merges were 70k).
Comment From: cpcloud
@JanSchulz can you try your replacement on pandas version 0.11.0 and report back to let me know if there's a difference? I'm having trouble isolating the memory issue without the exact dataset.
Also, it would be great if you could come up with a reproducible example that doesn't depend on your dataset. I can't reproduce the changes in memory usage (i.e., this has been a memory hog since at least v0.11.0) with the examples I've shown above. Without such an example, I'm essentially shooting in the dark.
Comment From: cpcloud
@jreback can i push to 0.15? i can't repro this
Comment From: chedatomasz
Has there been any progress on this? I feel like it could be a great improvement, as - to the best of my knowledge - there is currently no fast way to replace a DataFrame column based on a dict, and that is a fairly common use case
Comment From: mmcdermott
Any update on this? It would be greatly appreciated.
Comment From: jreback
@mmcdermott this is a very old issue - check whether this still exists in master - if not investigations welcome
Comment From: mmcdermott
I found this issue because my code was OOM when I tried to run df[col].replace(replace_dict), where replace_dict is a very large dictionary. As suggested by this thread, I replaced this code with df[col].apply(lambda x: replace_dict.get(x, x)) and it works fine, so the issue is still present.
Comment From: DCunnama
I can confirm this is still happening, just ran into this
Comment From: mmcdermott
The "apply" solution works fine for me to resolve this issue, but someone also recently pointed me to the map function: https://pandas.pydata.org/docs/reference/api/pandas.Series.map.html which I've been told (but haven't tested myself) doesn't have the memory leak/footprint issue of replace with a large dict, in case it helps others.
Comment From: DCunnama
Thanks, the "apply" solution works for me too, I will give the map function a try too.
Comment From: jbrockmendel
Best guess based on having spent a lot of time in the relevant code recently (but not having done any profiling specific to this issue):
replace_dict.items() ends up getting passed to Block.replace_list. There we pre-compute (I think the pre-compute bit was an optimization more recent than this issue) a mask for each key in replace_dict. So we end up with len(replace_dict) ndarrays of block.values.size bytes each.
In the OP replace_dict had about 70k entries and len(df) was 974757 then we're looking at about 68GB worth of ndarrays.
Option 1) avoid that pre-allocation at potential speed hit Option 2) when len(replace_dict) >> len(values) go down a different path that just iterates over values once doing a dict lookup for each one.
Comment From: iKolt
This code works fine:
df['col'] = df['col'].map(replacing_dict).combine_first(df['col'])
or
df['col'] = df['col'].map(replacing_dict).fillna(df['col'])
Usage of fillna is faster for small Series (checked some atrificial cases - 2x speedup) than combine_first, but combine_first is more self-commenting for me and the difference in speed is fading than Series is ~10K lines or more
Comment From: lithomas1
Taking a look at this.