There isn't an issue for empty inputs.
There is a need to specify the behaviour for empty input. Note that “empty” input can mean many things, and even combinations of them:
- zero rows but non-zero columns
- zero columns but non-zero rows
- zero rows and zero columns
- other: e.g., empty list provided to
agg()
As suggested by @shwina in the Pandas Standardisation docs, the idea is to start by writing a bunch of tests across many different Pandas operations and see how many pass across libraries.
Classic example (quiz: what should this do?)
df = pd.DataFrame({"a": [], "b": []}) df.groupby(“a”).agg({})
A starting list of operations where tests are needed would be particularly helpful, I plan to start going through them and adding all the tests.
- [ ] The above example returns a
ValueError: No objects to concatenate, is this the expected behaviour?
Comment From: attack68
I think this concept is worth exploring. I think you might have trouble establishing a consensus view in individual cases (such as this) for what is the appropriate action. For me an analogy is 0/0 in mathematics, which may be undefined or have a some asymptotic limit as a value but it depends.
However, what it might be easier to conclude is that if two similar pandas functions give different results when operating on empty DataFrames, then one of them should really be changed. Which one to which might require discussion, but I think presenting cases like this will probably help to drive forward the issue.
Comment From: rhshadrach
I believe this issue is meant only for methods that take a UDF (e.g. agg, apply, transform), is that correct? For other methods (e.g. sum, mean, fillna) I think there is a well-defined answer. It's only when given an unknown UDF that there is no "right" answer, but we should certainly strive for a consistent one.
One idea expressed in another issue (I'll have to track down where it is) is to call the UDF with an empty object, returning a default result if it raises. Something very roughly like:
# data is an empty DataFrame
try:
result = self.call_method(data)
except Exception:
result = data.copy()
return result
and documenting this behavior for working with empty objects. I'm attracted to the idea because it would allow users to write UDFs as:
def my_udf(x):
if x.empty:
return my_default_object
...
allowing them to have complete control over the result. Also, if a user does not opt-in to implementing the "empty-object" path, it returns a default which is at least easy to reason about.
For agg we would use .grouper.result_index and for transform we could use .obj.index for a more accurate result. But for apply there is no clear default because it can be used with reducers, transformers, and anything else for that matter.
Comment From: ntachukwu
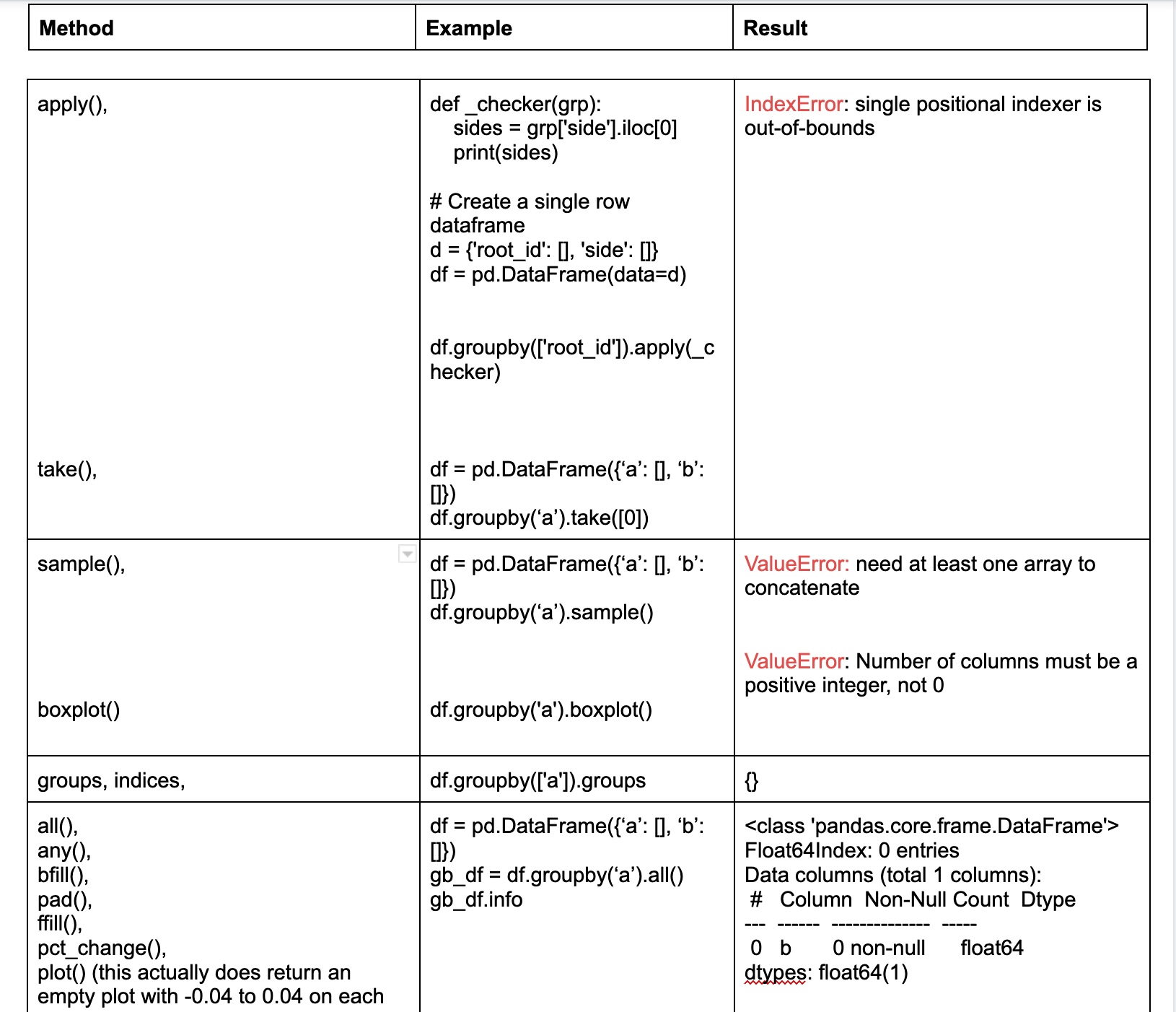
Here's a doc where I am compiling a table that shows some of pandas operations with an example and the result from running the example.
I am starting with group_by but I hope to check most of Pandas operations.
Please leave comments for suggestions and insights ( I will also like to know if this is an appropriate method of going about this issue).
Comment From: ntachukwu
The table has been completed for GroupBy methods. Please add comments and suggestions to the doc.
Comment From: asmeurer
CC @jakirkham @jcrist. I know that Dask uses empty DataFrames for metadata. Are there any Dask specific uses of empty dataframes that should be kept in mind here, or any other comments you have on how empty dataframes should behave?
Comment From: jorisvandenbossche
@Th3nn3ss thanks a lot for that google doc! That's a useful overview, and I left a few comments.
In general, I think it's certainly useful to start adding tests for all those cases (like you started in https://github.com/pandas-dev/pandas/pull/48327). Even if there is some behaviour that we would rather want to change, it's still good to have a test for it (easier to update it later if we change the behaviour), and such PRs could also trigger some discussion on specific corner cases.
One scope related suggestion: can we limit this issue to behaviour of operating on empty DataFrames/Series? (and leave the construction with empty input(eg https://github.com/pandas-dev/pandas/pull/48330) for another issue)
Comment From: jorisvandenbossche
[@rhshadrach] I believe this issue is meant only for methods that take a UDF (e.g. agg, apply, transform), is that correct? For other methods (e.g. sum, mean, fillna) I think there is a well-defined answer. It's only when given an unknown UDF that there is no "right" answer, but we should certainly strive for a consistent one.
It's true that in general it will mostly be for UDFs that it is hard (or impossible) to know what the correct output shape will be if there is no group to try the function on, while for most built-in methods the result will often be well defined. But, for some of our groupby methods, we also internally basically use the UDF path and apply some method, and so those could still give errors / inconsistencies as well.
For example, the take() mentioned in the google doc:
>>> df = pd.DataFrame({'a': [], 'b': []})
>>> df.groupby('a').take([0])
...
IndexError: indices are out-of-bounds
It's certainly debatable what the expected result should be, but the current error comes from calling the take() method on an empty DataFrame to be able to infer how the result should look like when there are no groups. For example in this case, I think it would be sensible to return an empty result (there is no group to take from, so taking the 0th element from that non-existing group also shouldn't raise, and since we know this just filters rows, we know what the result shape should look like)
Of course, we could certainly use your suggestion of checking for empty objects inside the UDF for the internal ones as well.
Comment From: rhshadrach
@jorisvandenbossche
But, for some of our groupby methods, we also internally basically use the UDF path and apply some method, and so those could still give errors / inconsistencies as well.
Agreed - if I had to guess there are likely many bugs or at least undesirable results here. But I'm suggesting that for those operations, we tackle them in a separate issues as the nature of the operation could be taken into consideration in determining the correct result. For a UDF on the other hand, we do not know the nature of the operation, and so we need to decide on a behavior without considering it. It's for this reason why I suggest to make this issue just for UDFs, to focus the scope.
Comment From: jorisvandenbossche
For future reference, the specific example of sample() with an empty dataframe has been tackled in https://github.com/pandas-dev/pandas/pull/48484
For a UDF on the other hand, we do not know the nature of the operation, and so we need to decide on a behavior without considering it. It's for this reason why I suggest to make this issue just for UDFs, to focus the scope.
Maybe we could also open a dedicated issue to discuss this specific issue for groupby with UDFs, and keep this as a general overview issue for working on empty dataframes (my understanding is that it is not meant to be limited to groupby)
Comment From: rhshadrach
@jorisvandenbossche
Maybe we could also open a dedicated issue to discuss this specific issue for groupby with UDFs, and keep this as a general overview issue for working on empty dataframes (my understanding is that it is not meant to be limited to groupby)
Just to be certain, I've been advocating making this issue about all methods that take UDFs, not just groupby. I personally find "handling of empty DataFrames" to be too wide of scope for discussion on a single issue (but would make sense to me as a tracking issue that links to other issues). However I certainly have no real objection as to its existence if that's what others want to pursue. I will point out that if we were to make an issue on how pandas methods that take UDFs handle empty objects, we now have two places where discussion could take place and that seems undesirable to me.
Comment From: rhshadrach
One idea (proposed in https://github.com/pandas-dev/pandas/issues/50588#issuecomment-1373430540 and I think some other places) is to allow users specify a second UDF or object to handle the empty case. This seems more explicit than having users bake special cases into the UDF itself, and is a more explicit change from an API standpoint (adding a new argument rather than just changing behavior). However, I don't think we should ever require such a function, so even if we do add it we're still left to decide the behavior when one isn't provided.