- [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the latest version of pandas.
- [x] (optional) I have confirmed this bug exists on the master branch of pandas.
Hello,
While using pandas in my project, I saw the memory usage of my process raising. After some digging, it looks like there is a memory leak in the JSON encoding code.
This simple test should be able to reproduce the issue:
import pandas as pd
if __name__ == "__main__":
df = pd.DataFrame([[1,2], [1,2], [3,4], [3,4], [3,6], [5,6], [7,8], [7,8]], columns=["a", "b"], index = pd.date_range('1/1/2000', periods=8, freq='T'))
for i in range(10000):
str = df.to_json(orient="table")
df = pd.read_json(str, orient="table")
Which ran using Valgrind should show that kind of result:
$ PYTHONMALLOC=malloc valgrind --leak-check=yes --track-origins=yes --log-file=valgrind-log.txt python test.py
...
==214631== 3,358,152 bytes in 79,956 blocks are definitely lost in loss record 15,015 of 15,015
==214631== at 0x483E77F: malloc (vg_replace_malloc.c:307)
==214631== by 0x4F811482: int64ToIso (in /lib/python3.7/site-packages/pandas/_libs/json.cpython-37m-x86_64-linux-gnu.so)
==214631== by 0x4F81364B: encode (in /lib/python3.7/site-packages/pandas/_libs/json.cpython-37m-x86_64-linux-gnu.so)
==214631== by 0x4F813514: encode (in /lib/python3.7/site-packages/pandas/_libs/json.cpython-37m-x86_64-linux-gnu.so)
==214631== by 0x4F8135F7: encode (in /lib/python3.7/site-packages/pandas/_libs/json.cpython-37m-x86_64-linux-gnu.so)
==214631== by 0x4F813514: encode (in /lib/python3.7/site-packages/pandas/_libs/json.cpython-37m-x86_64-linux-gnu.so)
==214631== by 0x4F813A80: JSON_EncodeObject (in /lib/python3.7/site-packages/pandas/_libs/json.cpython-37m-x86_64-linux-gnu.so)
==214631== by 0x4F811119: objToJSON (in /lib/python3.7/site-packages/pandas/_libs/json.cpython-37m-x86_64-linux-gnu.so)
==214631== by 0x4993B18: _PyMethodDef_RawFastCallKeywords (in /usr/lib/libpython3.7m.so.1.0)
==214631== by 0x4993713: _PyCFunction_FastCallKeywords (in /usr/lib/libpython3.7m.so.1.0)
==214631== by 0x499364C: ??? (in /usr/lib/libpython3.7m.so.1.0)
==214631== by 0x498E0CD: _PyEval_EvalFrameDefault (in /usr/lib/libpython3.7m.so.1.0)
...
Which points to the int64ToIso() function in this case but mostly any function used in the getStringValue() function is allocating memory and this memory appears to not be freed after that (if I'm not missing something).
https://github.com/pandas-dev/pandas/blob/2d51ebb77f5dc7f7824fd0b7b7edd538f2eaa819/pandas/_libs/src/ujson/lib/ultrajsonenc.c#L1082
It would be great if someone can confirm my deduction. If I'm right, I will try to submit a PR.
Thanks.
The environment I used:
pd.show_versions()
INSTALLED VERSIONS
------------------
commit : 7d32926db8f7541c356066dcadabf854487738de
python : 3.7.10.final.0
python-bits : 64
OS : Linux
OS-release : 5.11.2-1-MANJARO
Version : #1 SMP PREEMPT Fri Feb 26 12:17:53 UTC 2021
machine : x86_64
processor :
byteorder : little
LC_ALL : en_US.UTF-8
LANG : en_US.UTF-8
LOCALE : en_US.UTF-8
pandas : 1.2.2
numpy : 1.19.5
Comment From: jbrockmendel
cc @WillAyd
Comment From: WillAyd
Wow thanks for the details - very nice debugging. At an initial glance I think you are correct. We might need to make those date time functions look similar to Object_getBigNumStringValue where they set the cStr struct member (which I think is freed when the context ends) rather than just returning the object that was allocated
https://github.com/pandas-dev/pandas/blob/7af47c999dc3d2782caf63fe8c42f0858937867b/pandas/_libs/src/ujson/python/objToJSON.c#L1989
Comment From: Dollars
Thanks for the reply.
I think there is still an issue there. All the function linked to the JT_UTF8 type (linked to calling getStringValue) do not have the same expectations about the handling of the returned string.
As an example, PyBytesToUTF8 which calls PyBytes_AS_STRING, a macro of PyBytes_AsString.
https://github.com/pandas-dev/pandas/blob/7af47c999dc3d2782caf63fe8c42f0858937867b/pandas/_libs/src/ujson/python/objToJSON.c#L1560-L1561
https://github.com/pandas-dev/pandas/blob/3b4aec235fde541ccc30d794a6656fc65af14f04/pandas/_libs/src/ujson/python/objToJSON.c#L321-L326
As specified by the cpython documentation:
It must not be deallocated
On the contrary for the function int64ToIso the returned string must be freed by the caller.
May be, we could use a mustFree flag in the TypeContext struct or just use split the type to JT_UTF8_FREE and JT_UTF8_NOFREE something like that.
Comment From: Dollars
Oh sorry, now that I have read the code one more time, I understand why using the cStr struct member would be a good solution. Indeed.
Comment From: mikicz
Hi, I'm gonna piggyback on this issue a bit to mention that I'm pretty sure it's not just time related objects, see my comment here on a closed issue from quite a while ago (I wasn't sure if to create a new ticket): https://github.com/pandas-dev/pandas/issues/24889#issuecomment-799531430
There I used a DF which didn't have any time data, just numeric columns and the to_json() was leaking memory as well:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randint(0, 100, size=(100, 4)), columns=list('ABCD'))
for i in range(1000000):
# leak
body = df.to_json()
memory-profiler output:
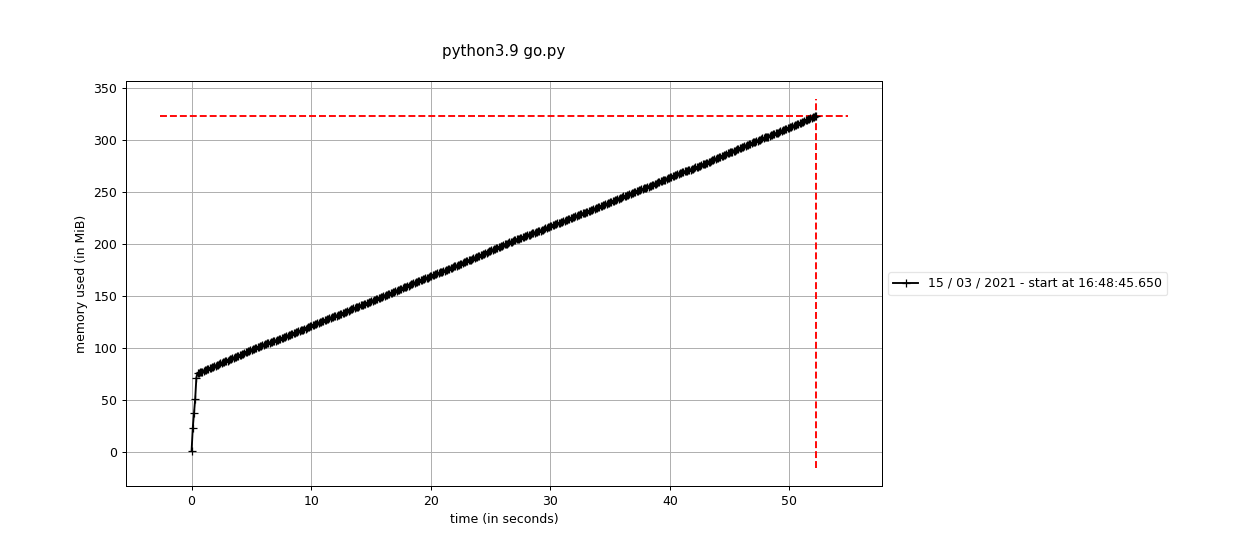
Comment From: Dollars
@mikicz: I have ran your small test script using Valgrind and it appears the memory leak comes from numpy.
PYTHONMALLOC=malloc valgrind --leak-check=yes --track-origins=yes --log-file=valgrind-log.txt python test.py
...
==72889== 191,989,728 (159,991,680 direct, 31,998,048 indirect) bytes in 1,999,896 blocks are definitely lost in loss record 14,834 of 14,834
==72889== at 0x483E77F: malloc (vg_replace_malloc.c:307)
==72889== by 0x6DF7611: array_alloc (in /usr/lib/python3.7/site-packages/numpy/core/_multiarray_umath.cpython-37m-x86_64-linux-gnu.so)
==72889== by 0x6E4467C: PyArray_NewFromDescr_int (in /usr/lib/python3.7/site-packages/numpy/core/_multiarray_umath.cpython-37m-x86_64-linux-gnu.so)
==72889== by 0x6E3E52F: PyArray_View (in /usr/lib/python3.7/site-packages/numpy/core/_multiarray_umath.cpython-37m-x86_64-linux-gnu.so)
==72889== by 0x6EDBF82: array_view (in /usr/lib/python3.7/site-packages/numpy/core/_multiarray_umath.cpython-37m-x86_64-linux-gnu.so)
==72889== by 0x4993ABF: _PyMethodDef_RawFastCallKeywords (in /usr/lib/libpython3.7m.so.1.0)
==72889== by 0x499B37E: _PyMethodDescr_FastCallKeywords (in /usr/lib/libpython3.7m.so.1.0)
==72889== by 0x49935F4: ??? (in /usr/lib/libpython3.7m.so.1.0)
==72889== by 0x498D3C6: _PyEval_EvalFrameDefault (in /usr/lib/libpython3.7m.so.1.0)
==72889== by 0x499A88A: ??? (in /usr/lib/libpython3.7m.so.1.0)
==72889== by 0x49A18CB: ??? (in /usr/lib/libpython3.7m.so.1.0)
==72889== by 0x4999A5C: _PyObject_GenericGetAttrWithDict (in /usr/lib/libpython3.7m.so.1.0)
==72889==
==72889== LEAK SUMMARY:
==72889== definitely lost: 159,993,568 bytes in 1,999,916 blocks
==72889== indirectly lost: 31,998,729 bytes in 1,999,887 blocks
...
It's clear both those issues do not have the same cause.
Comment From: mikicz
Thanks for doing that! Do you think I should report this to numpy directly or make a new issue here? I don't really understand pandas internals, so am not sure if the issue is in numpy directly or in the usage of numpy here?
Comment From: jmg-duarte
I know I'm coming late to the party but I would like to recommend memray. I would've never be able to detect this one https://github.com/python-lz4/python-lz4/issues/247 without it. If no one is interested, I can try to pick up where @Dollars left off
Comment From: Dollars
Hello, indeed I have not done much about this issue at the moment. It is not always easy to find time 😅. The profiler memray looks very nice. For me you are welcome to push this forward. I can review it if you ask me to.