Ref: https://github.com/pandas-dev/pandas/issues/43068#issuecomment-900504112
Copying from the comment above:
The documentation of
ExcelWritersays: "None of the methods and properties are considered public.".
It seems this line the documentation would be easy to miss, and it'd be better to make this more clear via the standard naming convention of a single leading underscore.
Comment From: Liam3851
Given xlsxwriter documents the use of the book attribute when using that engine to add more granular functionality (see "Accessing xlsxwriter from pandas"), should probably at least check upstream or see if there's some other way to support the interface? Our firm at least definitely uses writer.book per their examples (e.g. to add charts to sheets created with to_excel).
Comment From: twoertwein
As far as I understand, it is possible for users to interact with .book in any way they like to (even overwriting it) unless the file is opened in append mode. If the Excel file is opened in append mode, users should not overwrite .book https://github.com/pandas-dev/pandas/issues/39576#issuecomment-882918931 but I think it would still be fine to call all/most(?) methods on .book.
Comment From: feefladder
Yes, in fact I quite like working with .book It is like working with Openpyxl with some power functions written by Pandas. Fumbling around with the code I did not see a clear reason why "none of the methods are considered public" It seems that the code is quite mature already and the structure is there. As @Liam3851 says, there is already even documentation on how to (mis)use that.
The main problem why I think it is considered private, is that the internals for different engines work differently and nobody wants to write documentation for that..
I know quite some people do use it, maybe we could just accept that and write some documentation on how to properly use .book?
Comment From: rhshadrach
I think the worry is to have code that does something like (taken from the xlsxwriter docs):
# Create a Pandas dataframe from the data.
df = pd.DataFrame({'Data': [10, 20, 30, 20, 15, 30, 45]})
# Create a Pandas Excel writer using XlsxWriter as the engine.
writer = pd.ExcelWriter('pandas_simple.xlsx', engine='xlsxwriter')
[Do something directly with writer]
# Convert the dataframe to an XlsxWriter Excel object.
df.to_excel(writer, sheet_name='Sheet1')
Doing something directly with the writer may lead to unexpected behavior on the call to df.to_excel, but I haven't yet tried to come up with any examples where this can occur.
It's been suggested (https://github.com/pandas-dev/pandas/pull/42222#discussion_r693280177) that perhaps we should just deprecate ExcelWriter entirely. The one use case for ExcelWriter that I am aware of is when you want to write multiple DataFrames to the same excel workbook/sheet. I don't believe there is currently a way to do that using DataFrame.to_excel without using ExcelFile, but I could be mistaken here.
Assuming DataFrame.to_excel gained an argument like mode that supported appending, what use cases remain for ExcelWriter?
Comment From: jreback
agree with @rhshadrach lets depreciate ExcelWriter
Comment From: Liam3851
Re deprecation of ExcelWriter, will to_excel with mode='append' allow writing multiple sheets to the excel file at once in some manner? Won't there be perf loss if you're writing a bunch of sheets to an Excel file and you have to close and reopen it each time, esp. if it's stored on a remote? e.g. currently this works:
with pd.ExcelWriter('s3://my_bucket/my_obj.xlsx') as writer:
for i in range(50):
dfs[i].to_excel(writer, sheet_name=vars[i])
Just want to make sure there's no loss to the (I'd imagine substantially more common) case of writing a multiple-sheet workbook once, as the ability to modify/add sheets to existing workbooks is added.
I'd also note that things like #42222 (writing multiple frames to one sheet) also seem more useful to me than modifying existing workbooks, FWIW. I assume the supported means of using fancier formatting, nonstandard locations, or charts going forward would just be using openpyxl or xlsxwriter directly without any reference to pandas' to_excel function; which, you know, fair enough. It just seems like that was a useful, if unsupported, integration, so losing it is rather disappointing.
Comment From: rhshadrach
agree with @rhshadrach lets depreciate ExcelWriter
Not sure it should be deprecated yet @jreback - but looking into the impacts it may have.
Won't there be perf loss if you're writing a bunch of sheets to an Excel file and you have to close and reopen it each time, esp. if it's stored on a remote? e.g. currently this works:
@Liam3851 are you able to benchmark this? You can compare the time to write using code you posted against just calling df.to_excel('s3://my_bucket/my_obj.xlsx') repeatedly. Even though the latter overwrites, it would show the performance difference in reopening the remote file. A small DataFrame would show worst case (i.e. almost all overhead). But I suppose it may depend on the connection itself?
I assume the supported means of using fancier formatting, nonstandard locations, or charts going forward would just be using openpyxl or xlsxwriter directly without any reference to pandas' to_excel function
I don't believe this is the case. For nonstandard locations, isn't this just using startrow/startcol? For fancier formatting, see https://github.com/pandas-dev/pandas/pull/40231#discussion_r596308741. Not sure about charts.
Comment From: Liam3851
A small DataFrame would show worst case (i.e. almost all overhead). But I suppose it may depend on the connection itself?
I'd think the overhead would actually come from large excel files, if I'm understanding correctly (I may not be). My impression is that instead of ExcelWriter, we'd use df.to_excel with mode='a', repeatedly appending to the same file. In the remote case though, instead of committing the file as one operation via the end of the ExcelWriter, we would now write a file (sending it to S3), then open it for append, requiring reading it back (retrieving it from S3), close the file again (sending it back to S3), etc. You're basically looking at 2n-1 file transfers to make a workbook of n sheets, and need to transfer O(n^2) bytes of data back and forth. If I write a workbook of 15 sheets of 5 MB each I need to transfer 1.1 GB of data. Of course this is true without the remote too, but the perf cost is clearer if you picture the transfer going across a 100 Mbps WAN.
I don't believe this is the case. For nonstandard locations, isn't this just using startrow/startcol? For fancier formatting, see #40231 (comment). Not sure about charts.
You're absolutely right about startrow/startcol and the addition of styler.to_excel obviating the need for much of the fancier formatting that used to exist. Conditional formatting in the cells is something I use sometimes in case a downstream recipient wants to add to it, but that is definitely a more niche use case and more suited to an external.
Comment From: rhshadrach
Thanks for the comments on overhead @Liam3851 - agreed. For any of the charts/formatting examples coming from e.g. the xlsxwriter docs, I think this can still be accomplished in two steps - write the excel file and then open the excel file with xlsxwriter. Let me know if you think this is incorrect.
This leaves (a) the overhead for writing multiple DataFrames and (b) perhaps slightly more convenient for users as the reasons for keeping ExcelWriter.
I tracked down the origin of the comment about all attributes/methods being protected to https://github.com/pandas-dev/pandas/pull/22359#issuecomment-413783289, but there is no reason given there. @jorisvandenbossche do you have any recollection as to why this was added?
One last thing to note is that ExcelWriter itself is used for df.to_excel('foo.xlsx'), so deprecating it would just be making it protected, rather than being able to remove the code.
Comment From: feefladder
One use case I had for fumbling with the ExcelWriter.book is that you can put a dataframe at the end of a sheet (with headers):
import pandas as pd
sheetname = "some_existing_sheet_in_file"
with ExcelWriter("file.xlsx",engine="openpyxl",if_sheet_exists="overlay") as writer:
ws = writer.book[summary_sheet]
srow = ws.max_row + 1
df.to_excel(writer, sheet_name=sheetname, startrow=srow)
overlay is in #42222
which will not be possible otherwise.
There is also the thing that data validation is not supported by openpyxl, so whenever appending to a workbook with data validation, this has to be re-added by openpyxl. Yes, you could re-open the book, but that could take also quite some (un-needed) time with large excel files.
Doing something directly with the writer may lead to unexpected behavior on the call to df.to_excel, but I haven't yet tried to come up with any examples where this can occur.
I also cannot think of something useful that would break everything. Regarding writer.book: It is not directly assigned in the ExcelWriter class, but rather in each of the sub-classes OdsWriter, XlsxWriter, OpenpyxlWriter, XlwtWriter.
Comment From: rhshadrach
I also cannot think of something useful that would break everything.
The concern is for users to do something like this:
with ExcelWriter("test.xlsx", mode="r+", engine="openpyxl") as writer:
writer.close()
This raises "ValueError: I/O operation on closed file", and other than all attributes being declared protected, there is nothing in the documentation informing a user what the can and cannot do. Certainly if we were to open up the attributes for user access, the close method should be protected from calls. Now this is straightforward, but with all the attributes on writer it quickly becomes unclear what can be called/modified and what cannot.
Looking at the code for OpenpyxlWriter, everything touching self.book is in either save() or write_cells(...). It appears to me that allowing user access to read/modify self.book should be "safe" (i.e. not produce unexpected results / errors).
Assuming this is the case for other engines, I am +1 on making all other attributes either read-only or protected, and allowing user read/write access to book.
Comment From: feefladder
I think the main problem is this line in the docstrings:
Default is to use xlwt for xls, openpyxl for xlsx, odf for ods. See DataFrame.to_excel for typical usage.
This is a problem, because there are good examples in the docstring itself.
The writer should be used as a context manager. Otherwise, call
close()to save and close any opened file handles.
...and this will make people call writer.close(). To me, this is unclear, maybe clarify further as:
The writer should be used as a context manager. e.g. inside a
withstatement. Otherwise ...
and I think there will be quite some people calling writer.close because they will be using it as a file, so that will need a deprecation cycle.
Looking at the code for OpenpyxlWriter, everything touching self.book is in either save() or write_cells(...). It appears to me that allowing user access to read/modify self.book should be "safe" (i.e. not produce unexpected results / errors).
Good! openpyxl is the most complex one, in the other ones, there is only so much touching them, which is also __init__(), save() or write_cells():
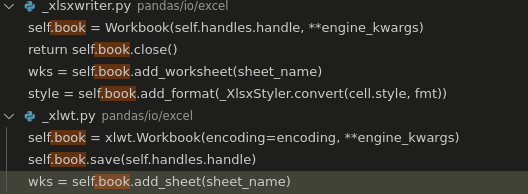
OK, so one edge case where this would result in different behaviour, is when a user creates sheets themselves. Then the Excelwriter will not know about the new sheet, and create another one with the same name. (Not sure if this will create an error). The following lines in write_cells of xlwt,xlsxwriter and odswriter:
if sheet_name in self.sheets:
wks = self.sheets[sheet_name]
else:
wks = Table(name=sheet_name) #odswriter, xlsxwriter: self.book.add_worksheet(sheet_name), xlwt: wks = self.book.add_sheet(sheet_name)
self.sheets[sheet_name] = wks
So self.sheets will not keep track of the sheets that are actually in the book. Maybe we could in stead look at self.book.sheetnames or something like that.. But that would result in very engine-specific implementations, or re-constructing the sheets dict on every write_cells. I think we could just add a warning about this in the docs that Excelwriter will not track the sheets you create with the underlying engine. For example:
>>> with pd.ExcelWriter("path_to_file.xlsx",engine="xlsxwriter") as writer:
... writer.book.add_worksheet("sheet")
... pd.DataFrame([1,2]).to_excel(writer,sheet_name="sheet")
throws a DuplicateWorksheetName error.
This could then again be solved by manually adding this to sheets like so:
>>> with pd.ExcelWriter("path_to_file.xlsx",engine="xlsxwriter") as writer:
... new_sheet = writer.book.add_worksheet("sheet")
... writer.sheets["sheet"] = new_sheet
... pd.DataFrame([1,2]).to_excel(writer,sheet_name="sheet")
...
which is really an edge case
another note is that the above snippet is different from the if_sheet_exists behaviour. Now we have it, I think that should be implemented in all the engines? But then the default of error is very inconvenient because it will break previous behaviour.
I could start working on a PR if that's wanted.
Comment From: rhshadrach
Thanks for the detailed comment @Joeperdefloep - agree on the bit about close, that part needs to remain public I think.
So self.sheets will not keep track of the sheets that are actually in the book. Maybe we could in stead look at self.book.sheetnames or something like that.. But that would result in very engine-specific implementations
Typically workbooks have < 100 sheets, and as a result recreating self.sheets is very cheap to the point of insignificant (but need to confirm this). If that's the case, then the best behavior to me would be to remove writer.sheets altogether. We could add a method, abstract in the base class, to be implemented by each writer.
Comment From: rhshadrach
For xlsxwriter, I'm seeing 0.1ms for 1000 sheets to create sheets:
sheets = {name: writer.book.get_worksheet_by_name(name) for name in writer.book.sheetnames}
Comment From: feefladder
Hmm, I do think it is nice that sheets is a more general form. ODSwriter puts the tables (sheets) together inside the save function, whereas the others just save the .book. So that would be different implementations...
Still it sounds nice to have indeed sheets be recreated/updated on everey write_cells. Should be possible I think.
Comment From: jbrockmendel
@rhshadrach IIRC some of this got done, is this still active?
Comment From: rhshadrach
Thanks @jbrockmendel - completed by #50093.