Is your feature request related to a problem?
Doing groupby().diff() with a big dataset and many groups is quite slow. In this image, it is shown how in certain cases optimizing it with numba can get 1000x speed.
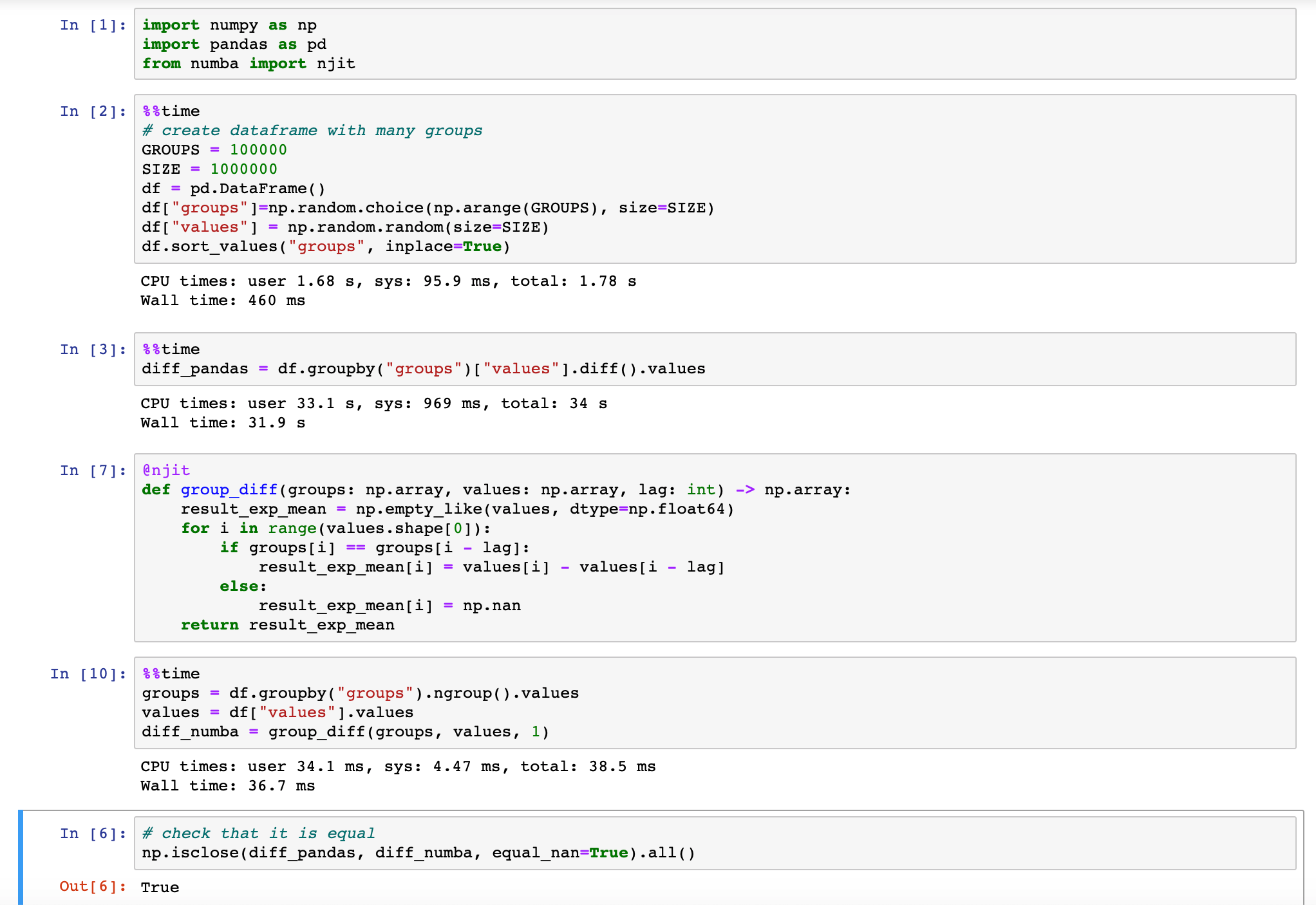
Describe the solution you'd like
Now, my question is, can this be optimized in pandas? I realise the case is somehow special, but i've had to work with small groups and I'm finding some speed issues.
API breaking implications
[this should provide a description of how this feature will affect the API]
Describe alternatives you've considered
[this should provide a description of any alternative solutions or features you've considered]
Additional context
Here's the python code in text format
import numpy as np
import pandas as pd
from numba import njit
# create dataframe with many groups
GROUPS = 100000
SIZE = 1000000
df = pd.DataFrame()
df["groups"]=np.random.choice(np.arange(GROUPS), size=SIZE)
df["values"] = np.random.random(size=SIZE)
df.sort_values("groups", inplace=True)
diff_pandas = df.groupby("groups")["values"].diff().values
@njit
def group_diff(groups: np.array, values: np.array, lag: int) -> np.array:
result_exp_mean = np.empty_like(values, dtype=np.float64)
for i in range(values.shape[0]):
if groups[i] == groups[i - lag]:
result_exp_mean[i] = values[i] - values[i - lag]
else:
result_exp_mean[i] = np.nan
return result_exp_mean
groups = df.groupby("groups").ngroup().values
values = df["values"].values
diff_numba = group_diff(groups, values, 1)
# check that it is equal
np.isclose(diff_pandas, diff_numba, equal_nan=True).all()
Comment From: dsaxton
Seems related to some work @mroeschke has done
Comment From: jbrockmendel
PR would be welcome
Comment From: lukemanley
Does https://github.com/pandas-dev/pandas/pull/45575 address this? It was merged after this issue was opened. It doesn't use numba but it did get 1000x for a handful of cases
Comment From: jbrockmendel
Any idea how thorough the "handful of cases" were? or if there is non-trivial room for further improvement by implementing something in groupby.pyx?
Comment From: lukemanley
Any idea how thorough the "handful of cases" were? or if there is non-trivial room for further improvement by implementing something in groupby.pyx?
45575 shows the ASV which covers a lot of different cases. Not all are 1000x but most cases see a significant improvement
Comment From: jbrockmendel
OK. im happy to consider this resolved. good job!