With the addition of the new pyarrow engine, we now have the option to use multiple threads to read a CSV file. (This is also controllable through the pyarrow.set_cpu_count option).
Should we expose a keyword(such as num_threads maybe) to the user as a keyword, or just add an example in the docs(for this case, redirecting to pyarrow.set_cpu_count? In the case of read_csv, this keyword would probably only apply to the pyarrow engines, however it is worth noting that we have had multiple feature requests for parallel CSV reading (e.g. #37955), and it is probably worth it to be configure the number of threads used if we offer multithreading.
Personally, I would prefer having a keyword, as if we decide to add more I/O engines with multithreading capabilities, it would be more convenient to be able to control this option through a keyword.
cc @pandas-dev/pandas-core
Comment From: mroeschke
What is done for numba capabilities (engine="numba") and is the most flexible IMO is to pair engine with a engine_kwargs keywords which accepts a dict with engine configurations e.g. {"set_cpu_count": 2}
This way the pandas API isn't tied to engine specific constructs while catering to whatever capabilities each engine supports.
Comment From: jreback
we pass thru n_threads in the parquet reader
so wouldn't object to a matching keyword or @mroeschke suggestion
Comment From: lithomas1
Personally, I think it might be better to just use a standard keyword argument, since it could be confusing if this changes between engines. I think this option would probably be popular enough to warrant this.
Having a standard keyword to control multi-threading could also pave the way for a global option to config this for everything.
(btw, n_threads doesn't exist in pyarrow anymore, you have to use pyarrow.set_cpu_count)
WDYT?
Comment From: rhshadrach
I think we should prefer usage of engine_kwargs when available. This makes it clear to the user that it depends on what engine they are using. It also lessens our technical debt as engines come and go, and change argument names.
Comment From: brianpenghe
Has this been solved? Reading a large csv is too slow with only one thread!
Comment From: phofl
It does not seem so.
Comment From: jreback
you can multi threaded reading with the engine='pyarrow' (in 1,4)
Comment From: jbrockmendel
Out of curiosity, in what scenario with multi-threading available would you not want to crank it up to 11? I guess debugging?
Comment From: bashtage
Out of curiosity, in what scenario with multi-threading available would you not want to crank it up to 11? I guess debugging?
When you use multi-process you almost always want to limit or eliminate multi-threading. For example, when using linear algebra on a spark cluster, failing to set MKL_NUM_THREADS=1 or OMP_NUM_THREADS=1 can lead to a situation where you end up with ncore * ncore threads competing for ncore resources, and basically crippling congestion.
Comment From: rhshadrach
Out of curiosity, in what scenario with multi-threading available would you not want to crank it up to 11? I guess debugging?
I'll also add multi-user servers where you want to be (somewhat) nice to other processes.
Comment From: jorisvandenbossche
In general when you have multiple libraries or functions each using multi-threading with their own thread pool (nested parallelism), you can easily get what is called "oversubscription".
Typical example is scikit-learn where you could do several runs of a model with varying parameters (eg for parameter optimization) in parallel, but then the individual model algorithm (eg using MKL or BLAS) might again run things in parallel . They developed a package to better be able control the number of threads that varying libraries use (https://github.com/joblib/threadpoolctl) to cope with such kind of issues.
Comment From: jbrockmendel
Thanks for those explanations of use cases for disabling/limiting multi-threading. They all seem like cases where you'd want to do it across the board at a process level, so seem like a use case for pd.set_option as opposed to fine-grained keywords.
Comment From: WillAyd
Out of curiosity I wanted to see what callgrind thought about our read_csv timings, using the 5GB csv file of Oct data taken from here:
https://www.kaggle.com/datasets/mkechinov/ecommerce-behavior-data-from-multi-category-store/discussion
Here are the results:
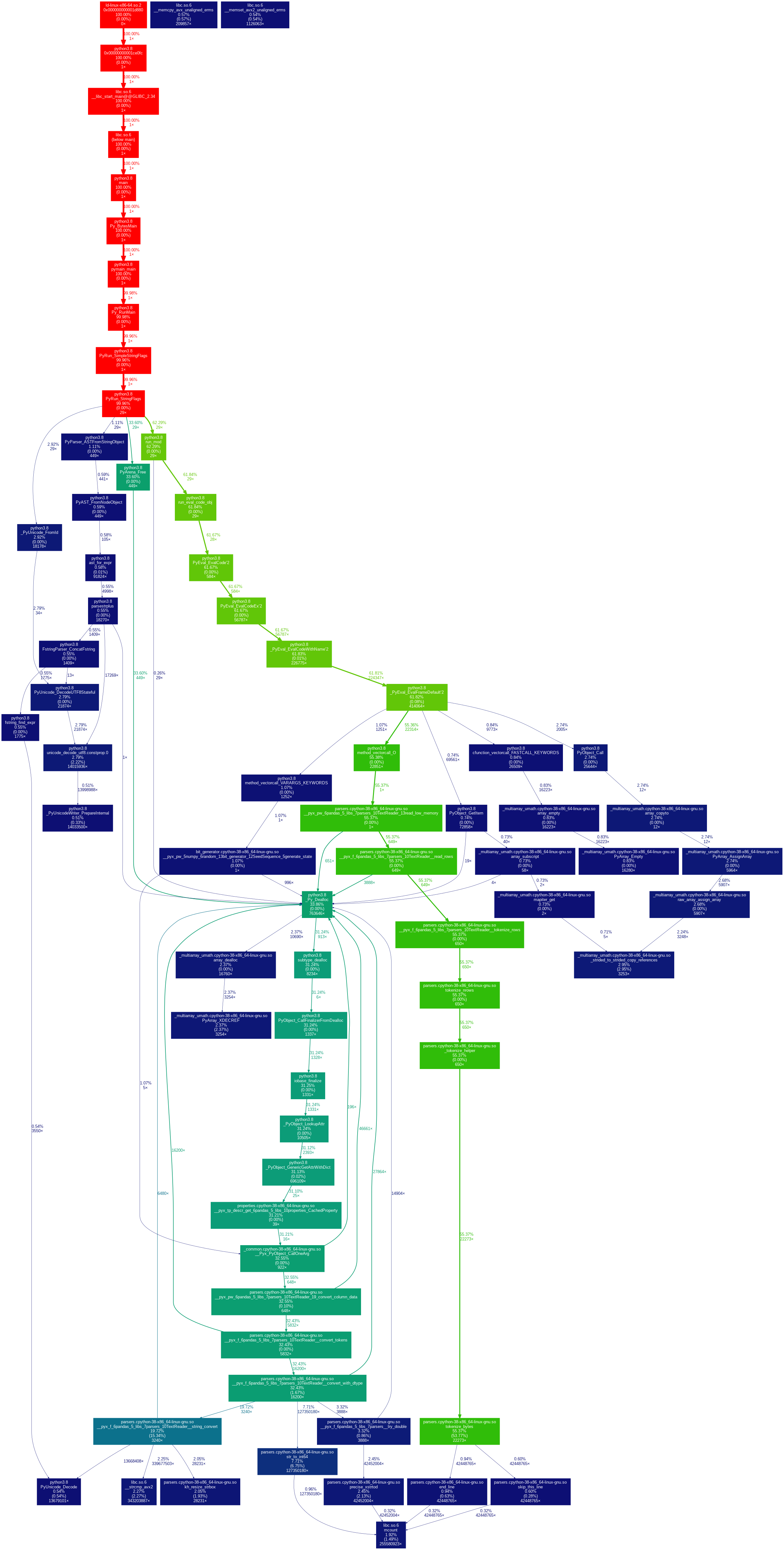
I am by no means an expert on the topic, but my initial thought in reading these results is that I/O itself is not much of a bottleneck, and by extension I'm not sure adding threads to the mix would buy us a lot. The big bottlenecks appear to be the tokenize_bytes and convert_with_dtype functions (the latter especially with strings).
Comment From: jorisvandenbossche
I/O itself is not much of a bottleneck, and by extension I'm not sure adding threads to the mix would buy us a lot
But also the parsing/tokenizer step can in theory be parallelized?
Comment From: Dr-Irv
But also the parsing/tokenizer step can in theory be parallelized?
Beware of the GIL! I was thinking you could do something by chopping up the file horizontally (e.g., if you have 1M rows, split it into 4 pieces of 250K rows each), process the splits in parallel into 4 DataFrames, then concat all of them.
But I think (although I'm not sure) that you might not get speedups because the different threads would get locks due to the GIL. Even if the GIL isn't involved, if they are sharing a malloc() operation way down under the hood, there will be a lock there that could end up constraining any speedup. I ran into this many years ago when writing some code in C that parallelized an algorithm.
Comment From: WillAyd
I think it can be parallelized but I also think we are mixing threads and processes. Assuming the tokenizer is CPU bound (which I believe it is - don't see any IO therein) adding threads on the same process isn't going to help the processing time, only hurt it.
Multiprocessing would seem a better fit, but the disadvantage I think we have is a lack of well defined IPC like Arrow has. The Python multiprocessing library has an Array object that might help