Indexing for entries in a series or dataframe with a multi-index has dramatically worse performance when using partial keys.
For example, for a series with a 3-level multi-index, series[x] is dramatically slower than series[(x,y,z)]. Please see the session below for a minimal reproduction:
```In [1]: %paste from datetime import datetime import pandas as pd import numpy as np import timeit
dates = pd.date_range('1997-01-01', '2020-12-31') cats = list('abcdefghijklmnop')
multi = pd.MultiIndex.from_product([dates, cats, cats])
series = pd.Series(np.random.rand(len(multi)), index=multi) date = datetime(year=2020, month=1, day=1)
generate cache
series.loc[(date, 'a', 'a')]
repeats = 1000 len(series)
-- End pasted text --
Out[1]: 2244096
In [2]: # Performance of indexing with full keys
In [3]: timeit.timeit(lambda: series.loc[(date, 'a', 'a')], number=repeats) Out[3]: 0.08493588299825205
In [4]: # Performance of indexing with partial keys
In [5]: timeit.timeit(lambda: series.loc[date], number=repeats) Out[5]: 4.771169905001443 ```
From looking at the code, it seems that BaseMultiIndexCodesEngine (pandas/_libs/index.pyx) essentially creates a hash table (a libindex.UInt64Engine) with entries for each full key. This makes full-key lookups fast. Meanwhile, for partial key lookups on a sorted index, MultiIndex._get_level_indexer will do two binary searches for each provided level of the key.
Instead of a flattened-index approach (again, via libindex.UInt64Engine), it would be excellent if Pandas implemented nested indeces (nested hash tables, if you will) for this. This would have a small impact on the performance of full key lookups (current lookup complexity is O(1), new complexity would be O(number_of_levels)). However, partial key lookups would greatly benefit, going from O(log(size_of_series)) to O(number_of_levels_in_key).
Comment From: jreback
xref https://github.com/pandas-dev/pandas/issues/20803 possible implementation via KDTrees: https://github.com/pandas-dev/pandas/issues/9365
Comment From: mroeschke
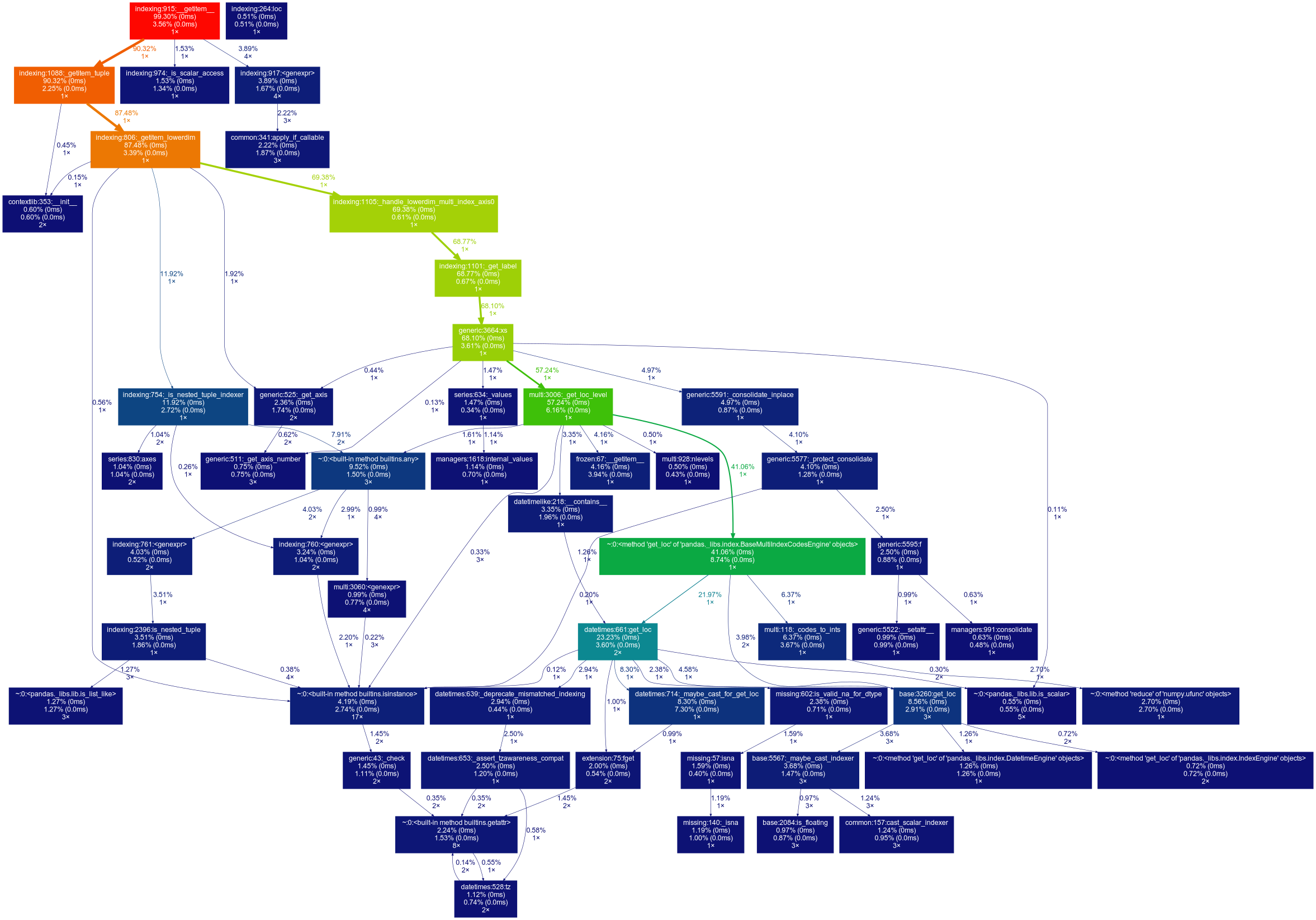
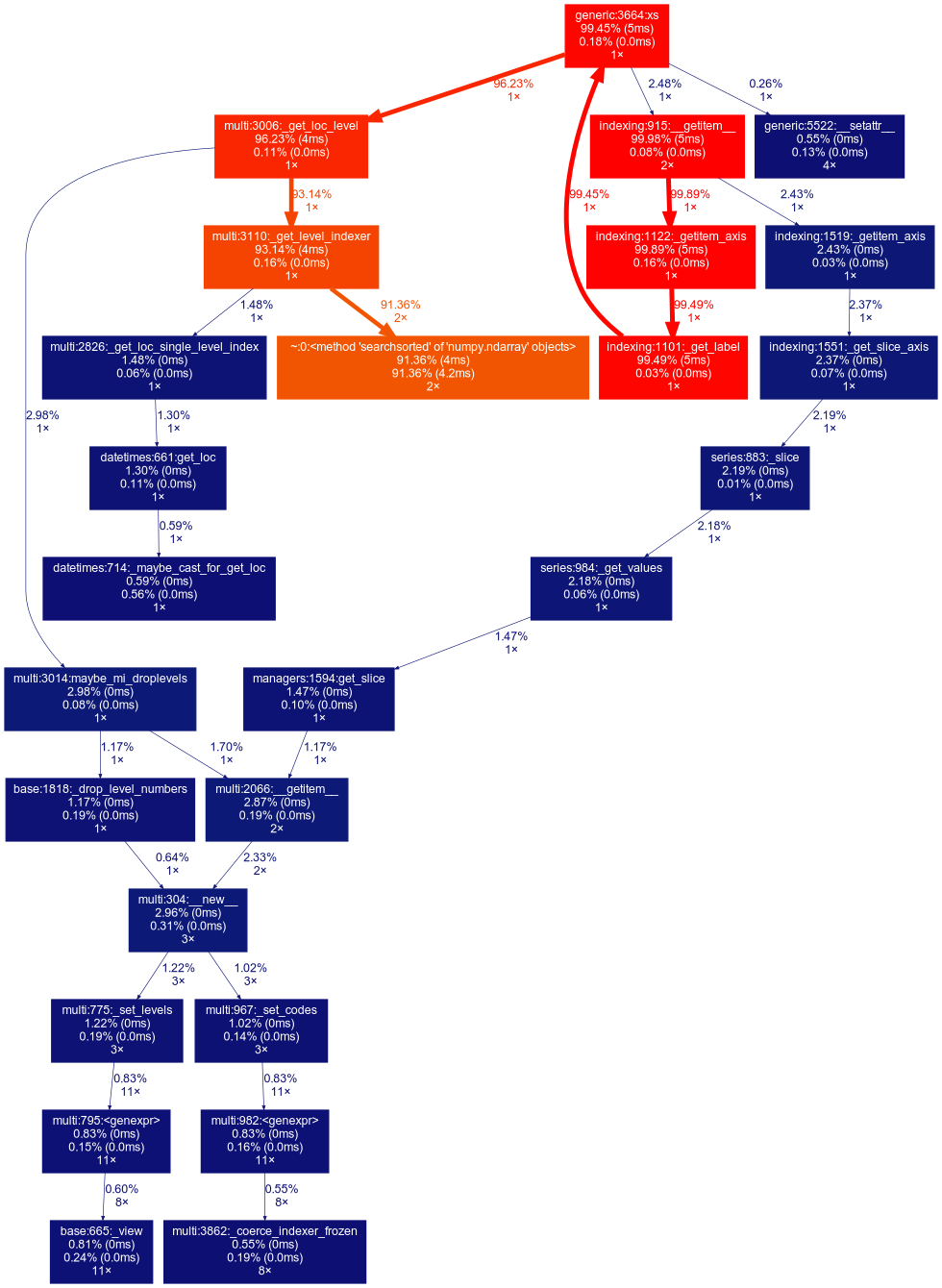
Here are the graphiz profiling of the two calls. It appears that most of the bottleneck is in the binary search calls for the partial key lookup so leveraging a new data structure would probably yield a performance improvement.
Full key
Part key
Comment From: jbrockmendel
The full-key timing is almost exactly unchanged (.083s), but the partial-indexing timing is down from 4.77s to .289s