OS: Windows 10 Python: 3.7.3 Pandas: 0.25.1
The DataFrame object has functions such as mean() and sum() which return a Series that contains the appropriate aggregation for each column of the DataFrame. Not all data types are appropriate for all aggregations. For example, strings are not suitable for mean or sum.
Current Behavior: When mean, sum, or other numerical aggregation is called on a DataFrame that has both numeric and string columns, it attempts to perform the aggregation on all of the columns. When it tries to perform the numeric aggregation on the string column it encounters an exception (TypeError). That exception is silenced and the affected column is excluded from the results.
Why this is a bug: As the number of rows in the DataFrame increases, the time it takes to attempt and fail to perform a numerical aggregation on the string column increases at (at least) an exponential rate. I doubled the number of rows and saw a x80 increase in runtime. Better detection of this issue could allow these aggregation functions to scale linearly.
Proposed Solution: Before attempting to perform an aggregation on a column, the function should first check the defined data type. If that data type is not compatible then the column should be skipped immediately without attempting the aggregation.
Alternative Solution: Some might argue that if a column contains all numeric data it should still be allowed to have the aggregation performed regardless of how that column is defined. I disagree, I believe clean code dictates that a column should behave according to the declared data type. Still, if you wanted to support this kind of implicit type cast, it should be done one row at a time, failing at the first non-numeric value. In my test dataset, all values were non-numeric, so the function could have failed after examining only one value, but instead the number of values available bloats the runtime before the error is encountered.
Note on fix implementation: It appears to me that the DataFrame aggregations are actually looping over the Series in the DataFrame and calling the Series aggregations in turn, then silencing any exceptions. An elegant solution would be to make the change to the Series aggregation functions. The Series should check its own type when the aggregation function is called, and throw an exception if the defined type is not compatible with the aggregation. The DataFrame aggregation function could then silence the exception as usual. This would increase performance without altering functionality in any way.
Comment From: mroeschke
Sorry that is issue got left unresponded for so long, but could you post a minimal example of the behavior you're seeing: https://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports
Comment From: rhshadrach
I tested this on master with the following code:
import pandas as pd
import matplotlib.pylab as plt
results = {}
for size in range(1, 21):
df = pd.DataFrame({'a': size * 1000 * ['a', 'b', 'c']})
results[size] = %timeit -o df.mean()
and the runtime seems superlinear:
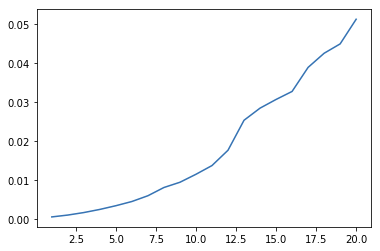
One gets constant runtime by passing the argument numeric_only=True into mean. Using this argument is what I think @insightfulquery is recommending, and so is already implemented.
However I'm a little confused as to why, when numeric_only=None, the runtime is not at most linear.
Comment From: jbrockmendel
Since numeric_only=None has now been removed, can this be closed?