I experience a weird pandas groupby behavior. Sometimes the groupby doesn't work, it just outputs the original dataframe. See my gist ( .ipynb file ) here: https://gist.github.com/jablka/d1b6461692e5c4a05727efaa85d86bbd Anybody knows what's wrong? It looks so trivial, but I got stuck...
Comment From: MarcoGorelli
The inconsistency has been fixed, if you try with the 2.0.0 release candidate you'll get matching results
In [2]: df.groupby("Animal").head()
Out[2]:
Animal Max Speed
0 Parrot 24.0
1 Falcon 380.0
2 Parrot 26.0
3 Falcon 370.0
In [3]: df.groupby("Animal").nth[:]
Out[3]:
Animal Max Speed
0 Parrot 24.0
1 Falcon 380.0
2 Parrot 26.0
3 Falcon 370.0
Comment From: phofl
Can you provide a reproducible example in your issue? There is a template that you can fill out. The examples from your notebook are generally good, but please include them here
Comment From: phofl
Good point, this is explicitly documented as well
https://pandas.pydata.org/docs/dev/reference/api/pandas.core.groupby.DataFrameGroupBy.head.html
Comment From: jablka
@MarcoGorelli look carefully, isn't that returning just the original dataframe? Shouldn't the expected behavior be quite opposite? I mean grouped like this:
Animal Max Speed
0 Falcon 380.0
1 Falcon 370.0
2 Parrot 24.0
3 Parrot 26.0
The inconsistency has been fixed, if you try with the 2.0.0 release candidate you'll get matching results
```python In [2]: df.groupby("Animal").head() Out[2]: Animal Max Speed 0 Parrot 24.0 1 Falcon 380.0 2 Parrot 26.0 3 Falcon 370.0
In [3]: df.groupby("Animal").nth[:] Out[3]: Animal Max Speed 0 Parrot 24.0 1 Falcon 380.0 2 Parrot 26.0 3 Falcon 370.0 ```
Comment From: MarcoGorelli
Is the issue just the sorting?
I don't know, but cc'ing the expert @rhshadrach for comments (and reopening for now)
Comment From: jablka
I can also provide another example, that is a bit complex.
I use Falcon, Parrots dataframe taken from the documentation.
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.groupby.html
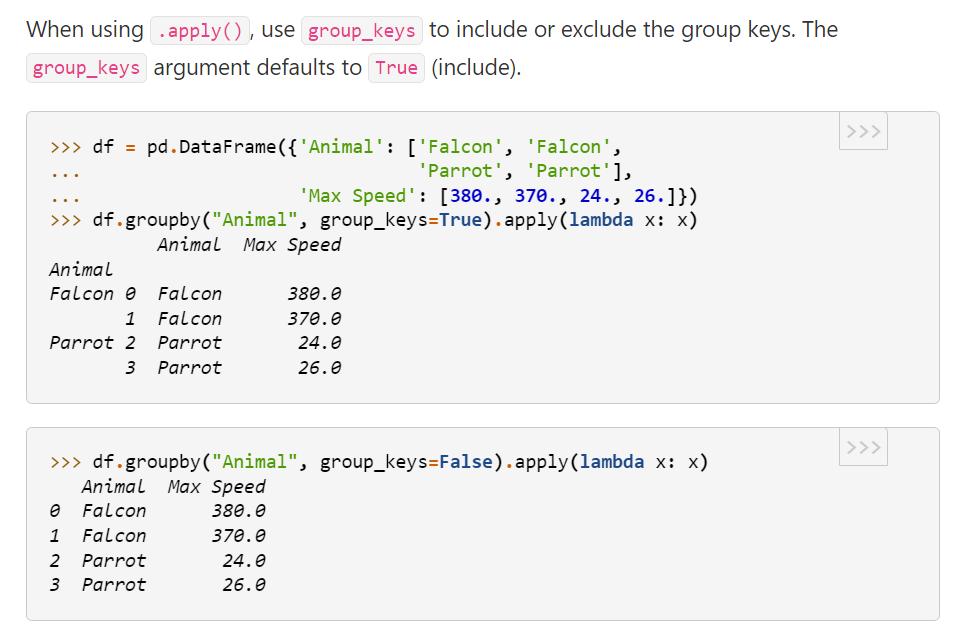
But in documentation, the behavior is not recognisable, because the dataframe is quite tidy. So let's shuffle it to: Parrot, Falcon, Parrot, Falcon so that we see the behavior. First and Second groupby works, Third and Fourth groupby doesn't:
import pandas as pd
df = pd.DataFrame({'Animal': ['Parrot', 'Falcon',
'Parrot', 'Falcon'],
'Max Speed': [24., 380., 26., 370.]})
print(df)
print()
print(df.groupby("Animal", group_keys=True).apply(lambda x: x))
print()
print(df.groupby("Animal", group_keys=True, sort=False).apply(lambda x: x))
print()
print(df.groupby("Animal", group_keys=False, sort=True).apply(lambda x: x)) # doesn't work
print()
print(df.groupby("Animal", group_keys=False, sort=False).apply(lambda x: x)) # doesn't work
( here is my notebook: https://gist.github.com/jablka/31f7eee7dd8635f73b3037c0bd466469 )
But this example seems more complex, since the code has more parameters than just .head() example above, but it is probably connected.
Comment From: rhshadrach
Filters, which includes head, tail, and nth, only subset the original DataFrame. In particular, as_index and sort have no effect (though this fact for the latter of these two is not currently well documented). So for example, if none of your groups have more than 5 rows, then groupby(...).head() will indeed give back the original DataFrame.
In the examples with apply, with group_keys=False it is inferred that the operation is a transformation and again, sort has no impact when used with transformations.
Comment From: jablka
so please, having this dataframe:
df = pd.DataFrame({'Animal': ['Parrot', 'Falcon', 'Sparrow',
'Parrot', 'Falcon', 'Sparrow'],
'Max Speed': [24., 380., None,
26., 370., None ]})
'''
Animal Max Speed
0 Parrot 24.0
1 Falcon 380.0
2 Sparrow NaN
3 Parrot 26.0
4 Falcon 370.0
5 Sparrow NaN
'''
how to achieve, to be grouped to this desired output: (I don't mean sorted like sort_values(), I want Animals to appear in order they are encountered... )
Animal Max Speed
0 Parrot 24.0
3 Parrot 26.0
1 Falcon 380.0
4 Falcon 370.0
2 Sparrow NaN
5 Sparrow NaN
Comment From: Dr-Irv
how to achieve, to be grouped to this desired output: (I don't mean sorted like sort_values(), I want Animals to appear in order they are encountered... )
Here's two rather ugly solutions to your problem:
>>> tdf = df.set_index("Animal", append=True).reorder_levels([1,0])
>>> (tdf.loc[pd.concat([i.to_frame()
for i in tdf.groupby("Animal", sort=False).groups.values()]).index]
.reset_index("Animal")
)
Animal Max Speed
0 Parrot 24.0
3 Parrot 26.0
1 Falcon 380.0
4 Falcon 370.0
2 Sparrow NaN
5 Sparrow NaN
OR
>>> (df.assign(ord=lambda df: df["Animal"]
.map({x:i for (i,x) in enumerate(df["Animal"].unique())}))
.rename_axis(index="ind")
.reset_index()
.sort_values(["ord", "ind"])
.drop(columns=["ind","ord"])
)
Animal Max Speed
0 Parrot 24.0
3 Parrot 26.0
1 Falcon 380.0
4 Falcon 370.0
2 Sparrow NaN
5 Sparrow NaN
Comment From: rhshadrach
If you'd like to maintain the order throughout an algorithm, I'd recommend considering using an ordered categorical:
df['Animal'] = pd.Categorical(df['Animal'], categories=df['Animal'].unique(), ordered=True)
df.sort_values(by='Animal')
If you don't want to use categorical, you can use the key argument to sort_values:
def by_occurrence(ser):
return ser.map({v: k for k, v in enumerate(ser.unique())})
df.sort_values(by='Animal', key=by_occurrence)
Instead of a named function, you may prefer to use a lambda.
Comment From: jablka
thank you for the solutions.
But, wouldn't it be handy if also a groupby can come up with similar output?
For example:
df.groupby('Animal').filter(lambda x:True)
(which was proposed in StackOverflow... but seems it doesn't work https://stackoverflow.com/questions/36069373/pandas-groupby-dataframe-store-as-dataframe-without-aggregating/36069578#36069578 )
or the example from documentation:
df.groupby('Animal').apply(lambda x : x)
If it's not a bug, then perhaps a feature request? Thank you.
Comment From: rhshadrach
If it's not a bug, then perhaps a feature request? But, wouldn't it be handy if also a groupby can come up with similar output?
Certainly! But I don't think it's a good user experience to point users toward groupby to accomplish a sort, and I don't think we should be introducing groupby ops that do the same thing yet differ from how other agg / transform / filter methods behave.
Comment From: MarcoGorelli
In particular, as_index and sort have no effect (though this fact for the latter of these two is not currently well documented)
Should we just treat this as a documentation issue, document this, and close it?
Comment From: rhshadrach
@MarcoGorelli - agreed; I believe as_index is well-documented but sort is not.
Comment From: natmokval
I'd like to work on it.
Comment From: rhshadrach
51704 is adding that sort has no impact on filters to the User Guide; the only other place I know offhand where this should be mentioned is the API docs for DataFrame.groupby and Series.groupby.
Comment From: jablka
follow-up to my code puzzle: accidentally, I just found some excellent solution:
df.sort_values(by='Animal', key=lambda x: x.factorize()[0] )
👏 :-)
If you'd like to maintain the order throughout an algorithm, I'd recommend considering using an ordered categorical:
df['Animal'] = pd.Categorical(df['Animal'], categories=df['Animal'].unique(), ordered=True) df.sort_values(by='Animal')If you don't want to use categorical, you can use the
keyargument to sort_values:``` def by_occurrence(ser): return ser.map({v: k for k, v in enumerate(ser.unique())})
df.sort_values(by='Animal', key=by_occurrence) ```
Instead of a named function, you may prefer to use a lambda.