Pandas version checks
-
[X] I have checked that this issue has not already been reported.
-
[X] I have confirmed this bug exists on the latest version of pandas.
-
[ ] I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
Unfortunately, I can't provide a reproducible example as it seems to be a really specific case (see issue description)
Issue Description
I am trying to do a simple SQL query to an Oracle database using an SQLAlchemy connection and read_sql. The code is like as follows:
df = pd.read_sql(sql_query, db)
I can't provide specific info on the SQL query, as it uses names that I'm restricted to provide. What I can say is that it is structured like this:
SELECT
t1.id_column,
t1.date_column
FROM
schema.table t1
LEFT JOIN schema.table2 t2 ON t1.id = t2.id
LEFT JOIN schema.table3 t3 ON t2.id = t3.id
LEFT JOIN schema.table4 t4 ON t3.id = t4.id
WHERE
t1.id_column = id
My SQLAlchemy connection (I've already used this connection many times, and is working perfectly) is created with:
db_connection = create_engine(f'oracle://{DB_USERNAME}:{quote(DB_PASSWORD)}@{dsn_tns}', echo=False)`
The same SQL query returns differente results when using Dbeaver and read_sql. Not only different numbers, as I've seem in other issues, but instead of returning a date for example, it returns None.
Here is an example when running the exact same SQL query:
-
read_sql results:
-
dbeaver query results:
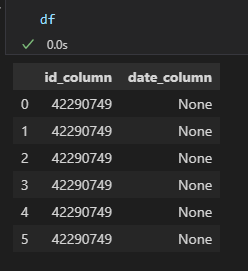
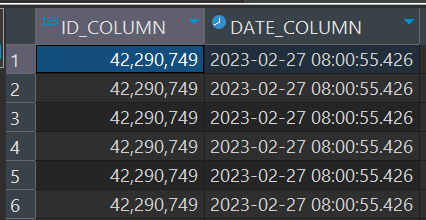
Inside my SQL query, i have an filter like WHERE id_column = id (this id is a integer). If i put every other number in this, it returns as expected, but with this specific case, it doesn't (hence the difficulty in providing a reproducible example).
I've tried to parse date columns and other stuff like using an cx_Oracle connection instead of SQLAlchemy, and still doesn't work.
(sorry for this bad, not reproducible issue)
Expected Behavior
The same code, the same SQL query, just changing the filtered id:
-
read_sql results with other id
-
dbeaver results with other id
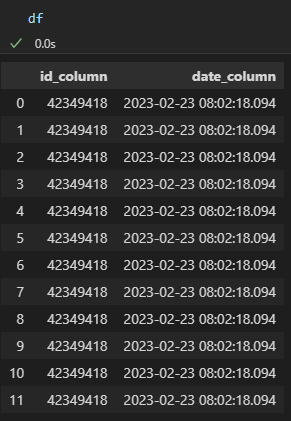
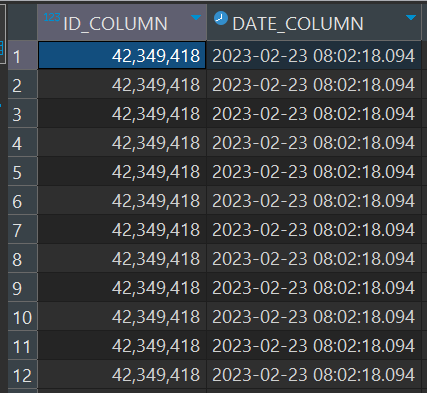
Installed Versions
Comment From: phofl
Hi, thanks for your report. There isn't much that we can do without an example.
I'd suggest looking into read_sql on your side. At one point, we use fetch all() to get the data from the database before converting it into a DataFrame. I'd recommend checking the list of tuples that is returned there to see if the conversion goes wrong when converting to a DataFrame or before. If the erroneous data come from Alchemy, then this is probably a problem with your Query or with Alchemy themselves
Comment From: phofl
Closing for now, please ping to reopen if you can provide more information