https://en.wikipedia.org/wiki/List_of_countries_by_road_network_size
Copy/paste the table HTML in a file
df=pd.read_html(table) df=pd.DataFrame(df[0])
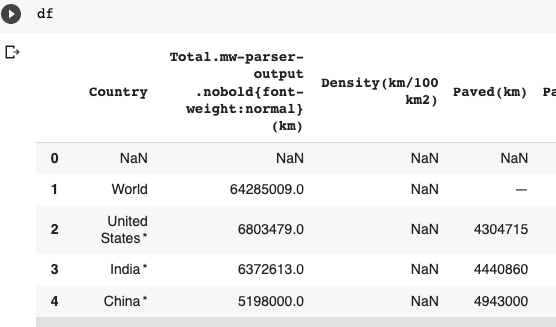
The result is shown in the image. The Density column values are missing.
Comment From: phofl
Hi, thanks for your report.
Can you please provide a minimal and reproducible example? You can define your html table as
data = """Put your html table here
"""
pd.read_html(StringIO(data))
Also, please provide your pandas versions and dependencies, e.g. fill out the issue template
Comment From: manzikki
here's a few first lines of the table in question. Pandas 1.3.5. I'm running it on Google Colab.
import pandas as pd from io import StringIO; roadtable = """
| Country | Total (km) |
Density (km/100 km2) |
Paved (km) |
Unpaved (km) |
Controlled-access (km) |
Source & Year | |||
|---|---|---|---|---|---|---|---|---|---|
| World | 64,285,009 | 47 | — | — | — | 2021 | |||
| United States * | 6,803,479 | 69 | 4,304,715 | 63% | 2,581,895 | 38% | 95,932 | 1.4% | [3] 2019 |
Comment From: phofl
Can you try on the newest pandas version? 2.0.0rc0
Comment From: manzikki
Unfortunately the issue is there with 2.0.0rc0 pd.version '2.0.0rc0'
print(df.columns) Index(['Country', 'Total .mw-parser-output .nobold{font-weight:normal}(km)', 'Density (km/100 km2)', 'Paved (km)', 'Paved (km).1', 'Unpaved (km)', 'Unpaved (km).1', 'Controlled-access (km)', 'Controlled-access (km).1', 'Source & Year'], dtype='object') print(df['Density (km/100 km2)']) 0 NaN 1 NaN 2 NaN Name: Density (km/100 km2), dtype: float64
Comment From: phofl
Good, now please reduce everything from your html table that is not necessary to reproduce. The example should be minimal
Comment From: m-ganko
Hi, it seems the problem is related to style="display:none". When one of elements in table cell has this style attribute, pandas returns NaN, while it should only skip this element. Below reproducible example:
html_table = """
<table>
<tr>
<th>Col 1</th>
<th>Col 2</th>
<th>Col 3</th>
</tr>
<tr>
<td>1</td>
<td>2</td>
<td>3</td>
</tr>
<tr>
<td><span style="display:none"></span>4</td>
<td>5</td>
<td>6</td>
</tr>
</table>
"""
pd.read_html(html_table)[0]
Out[1]:
Col 1 Col 2 Col 3
0 1.0 2 3
1 NaN 5 6
I can try to fix this problem.
Comment From: m-ganko
take
Comment From: m-ganko
I have created PR which should resolve main issue.
But in this wikipedia example we can see another one, read_html reads also <style> element text. I would suggest adding new argument to read_html function e.g. skip_style_elements. I could also work on this, just let me know if it make sense for you and if I should create new issue.