Is your feature request related to a problem?
I would like to use pandas read_xml function to parse shallow xml data about products and related data. My data has numeric like identifiers (ean), which are automatically casted to numbers in read_xml, and there after I can not use them to identify records in the data. There is a simple solution: support and forward extra kwargs to _parse and then TextParser. dtype=str solves the problem for me.
from pandas.io.xml import _parse
data = _parse(xml_str, './*', None, False, False, None, 'utf-8', 'lxml', None, 'infer', None, dtype=str)
->
from pandas import read_xml
data = read_xml(xml_str, dtype=str)
Without dtype=str:
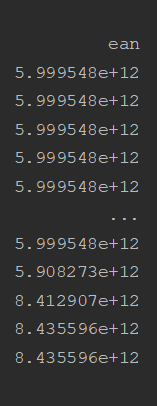
If I try to convert data data after parsing with astype(str) I get strings like "5999548048023.0"
With dtype=str:
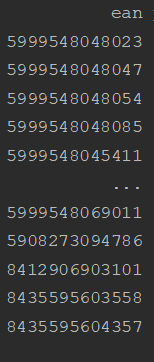
Comment From: ParfaitG
Did you try current dev version of pandas? In forthcoming pandas 1.5, pandas.read_xml will support dtype parameter including converters. See dev docs.
Comment From: mroeschke
Appears dtype and converters should suffice the need here so closing. If it doesn't meet the original use case we can reopen