Pandas version checks
-
[X] I have checked that this issue has not already been reported.
-
[X] I have confirmed this bug exists on the latest version of pandas.
-
[ ] I have confirmed this bug exists on the [main branch] (https://pandas.pydata.org/docs/dev/getting_started/install.html#installing-the-development-version-of-pandas) of pandas.
Reproducible Example
import pandas as pd
import numpy as np
from pandas.core.dtypes import common
class MyFrame(pd.DataFrame):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
for col in self.columns:
if not common.is_numeric_dtype(self[col]):
self[col] = pd.to_numeric(self[col], errors='ignore')
@property
def _constructor(self):
return type(self)
def get_frame(N):
return MyFrame(
data=np.vstack(
[np.where(np.random.rand(N) > 0.36, np.random.rand(N), np.nan) for _ in range(10)]
).T,
columns=[f"col{i}" for i in range(10)]
)
frame = get_frame(int(1e5))
frame.dropna(subset=["col0", "col1"])
Issue Description
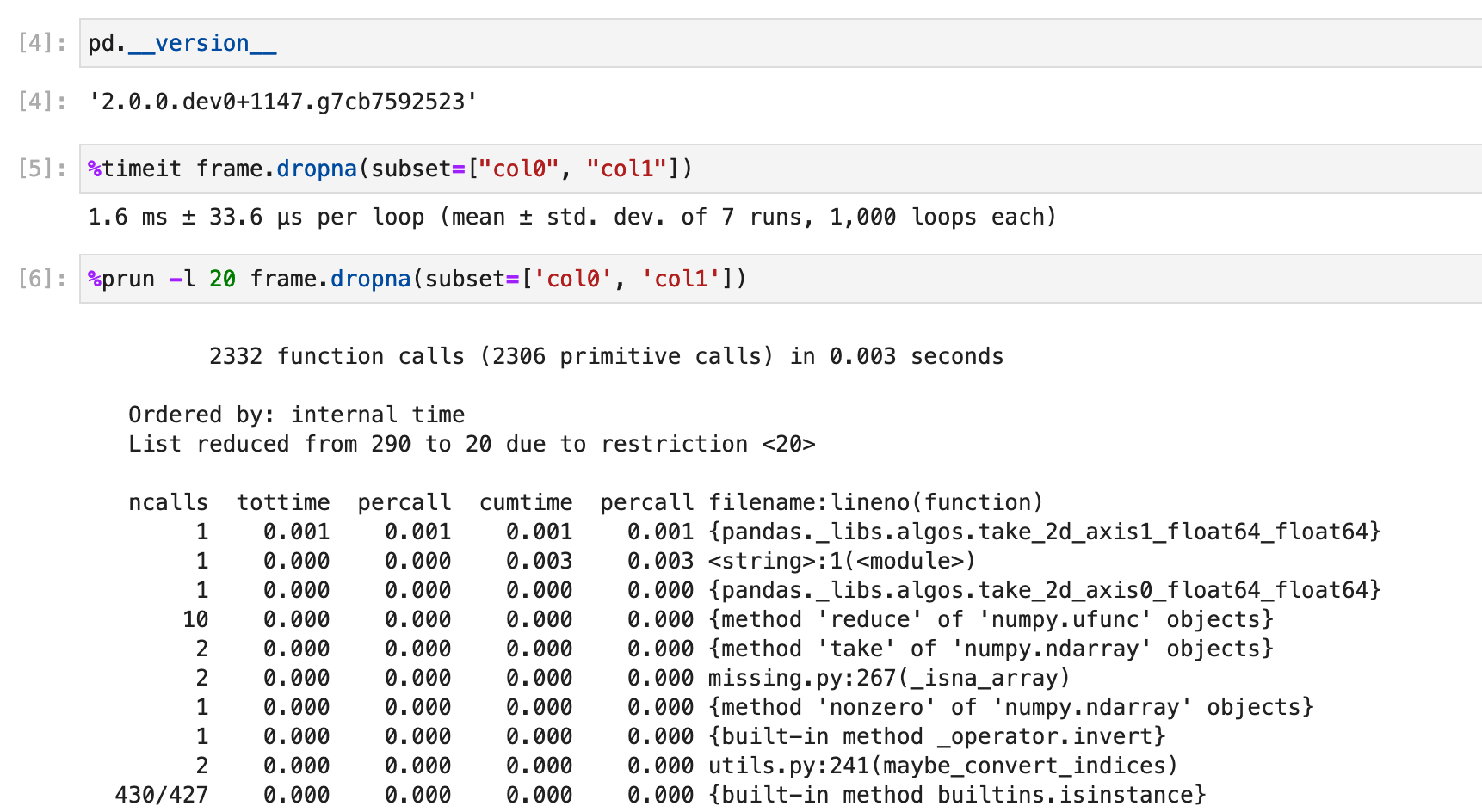
Using a subclass setup that accesses the columns of the dataframe inside __init__ we are finding that pandas=1.5.x,1.4.x is much slower than than pandas=1.3.5/2.0.0.dev. This looks to be resolved in the most recent nightlies so, if not already tested, could some additional testing be done to ensure no further regressions in this area?
Timings by pandas version:
1.3.5 - 2ms
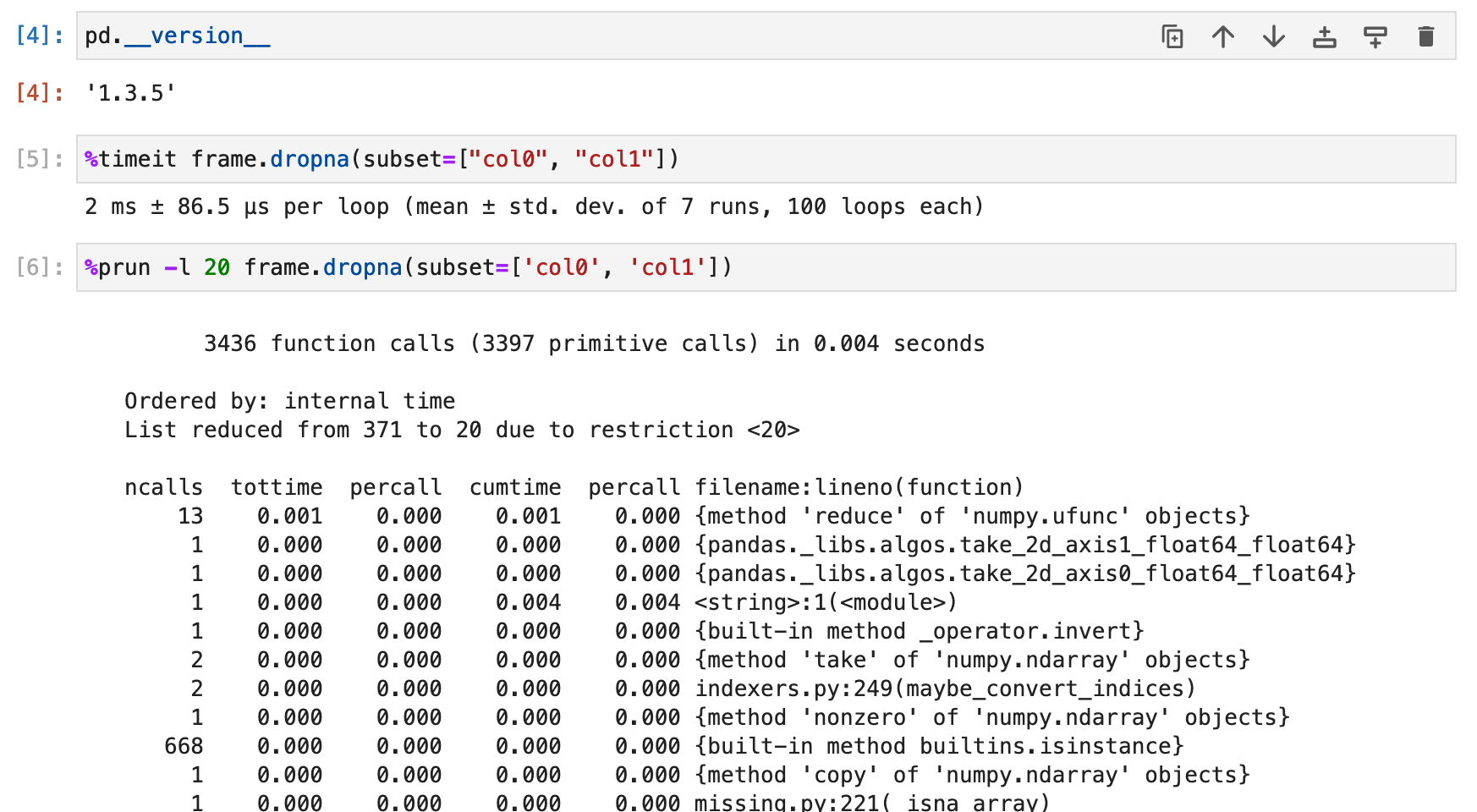
1.4.4 - 1.84s
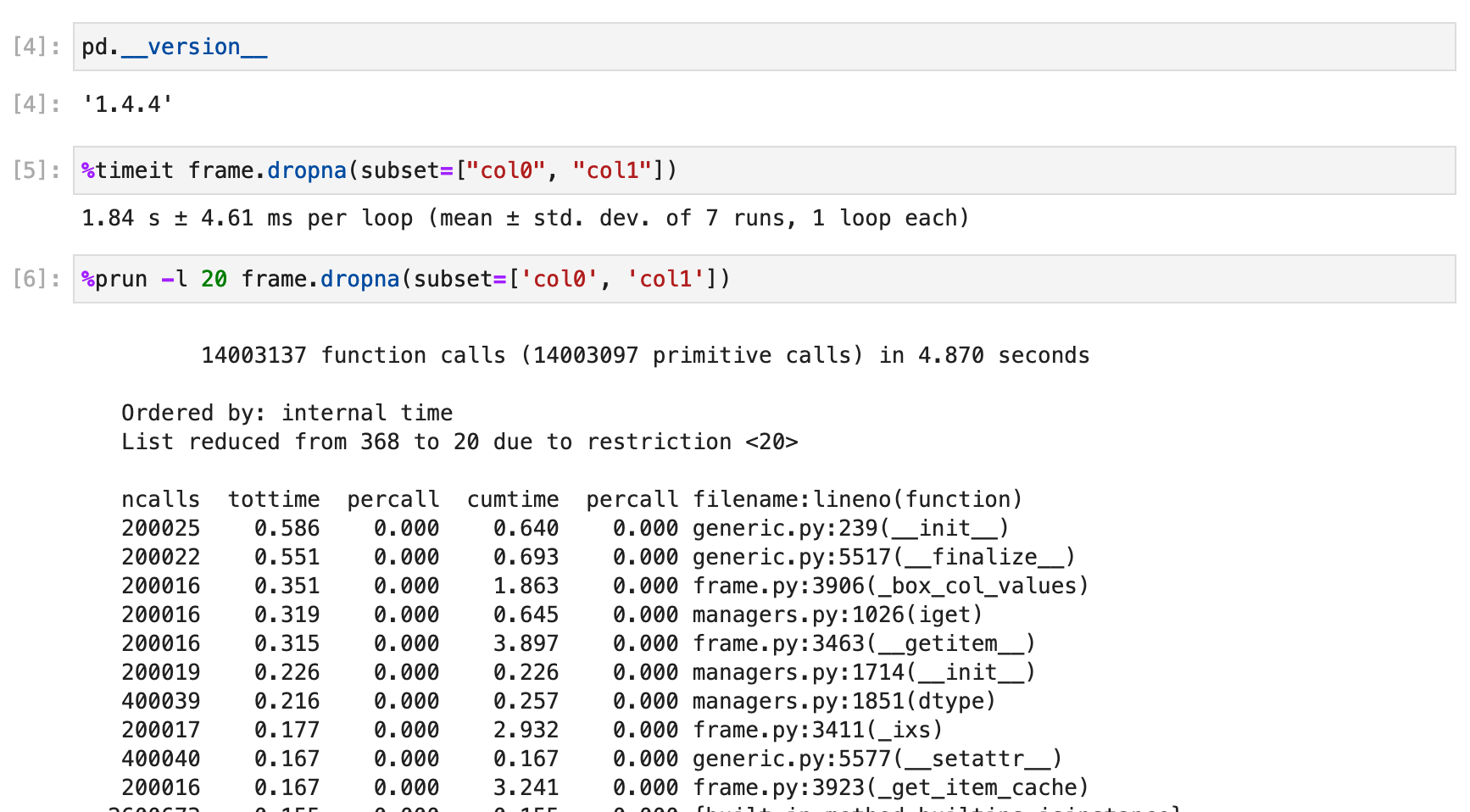
1.5.2 - 2.2s
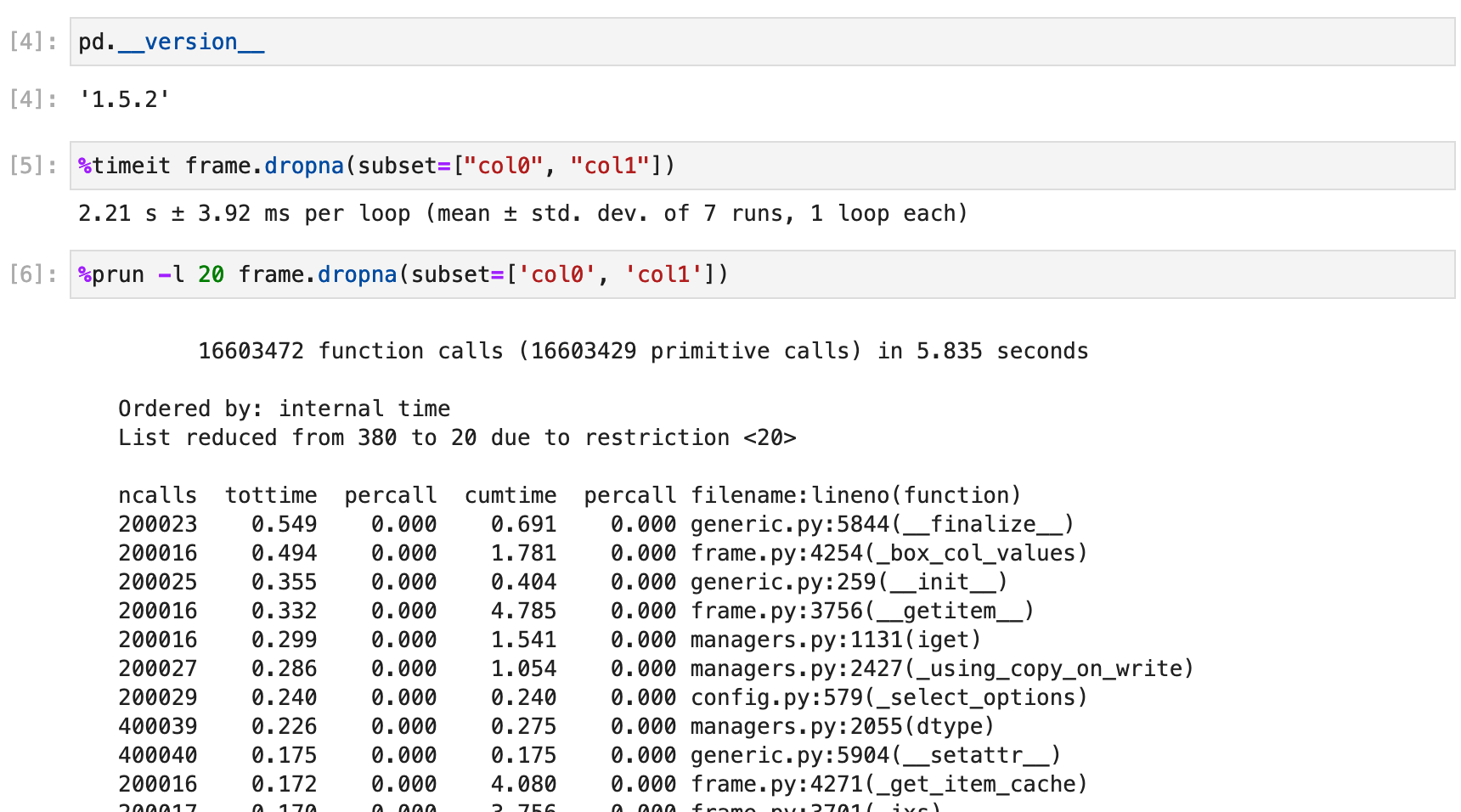
2.0.0 (nightly build) - 1.6ms
Expected Behavior
dropna runs at the same or faster than 1.3.5/2.0.0.dev speeds
Installed Versions
Comment From: ryandvmartin
Looks like triage here: https://github.com/pandas-dev/pandas/issues/50708#issuecomment-1491748956 is the cause of this behavior, this looks like a duplicate