pd.__version__
'0.12.0.dev-6a0b9ec'
exdf = pd.DataFrame([["aoe",12,3.14],["qjk",34,5.67]])
exdf.columns = list('abc')
#exdf = exdf.reindex(columns=reversed(list('abc')))
def a(inp):
return '{:>3s},'.format(inp)
def b(inp):
return '{:2d},'.format(inp)
def c(inp):
return '{:3.2f},'.format(inp)
print repr(exdf.to_string(formatters={'a':a,'b':b,'c':c},
index=False,header=False))
' aoe, 12, 3.14,\n qjk, 34, 5.67,' ^^extra space!
Note, when you reindex the columns to be the other way around by removing the # in front of the line exdf = exdf.reindex ... then you get:
'3.14, 12, aoe,\n5.67, 34, qjk,' ^^no extra space!
where one can easily see, that usually, as it is correct, the first element in the line does NOT get a space. Therefore I consider this a formatting bug for (string) objects.
Comment From: michaelaye
FYI, I am using to_string() and not to_csv(), because I need spaces behind the comma that is currently not possible with to_csv(). Also, to_csv() does not accept a formatting dictionary.
Comment From: michaelaye
Expected outcome:
for line in exdf.values:
print repr("{:>3s}, {:2d}, {:3.2f}".format(*line))
'aoe, 12, 3.14' 'qjk, 34, 5.67'
Comment From: jreback
closing in favor of master issue #4668
Comment From: samuelchodur
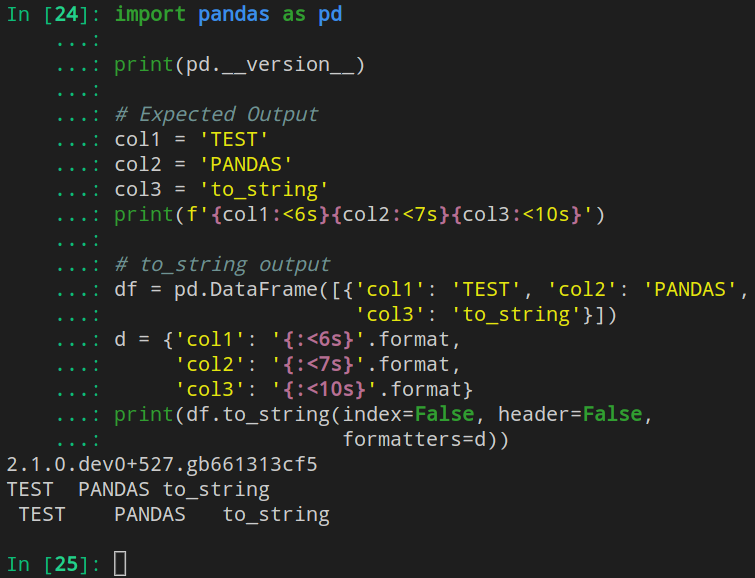
This bug is not present in 1.5.3 but I am seeing it now in 2.0.0 and the current main branch (output shown below).
import pandas as pd
print(pd.__version__)
# Expected Output
col1 = 'TEST'
col2 = 'PANDAS'
col3 = 'to_string'
print(f'{col1:<6s}{col2:<7s}{col3:<10s}')
# to_string output
df = pd.DataFrame([{'col1': 'TEST', 'col2': 'PANDAS',
'col3': 'to_string'}])
d = {'col1': '{:<6s}'.format,
'col2': '{:<7s}'.format,
'col3': '{:<10s}'.format}
print(df.to_string(index=False, header=False,
formatters=d))
results in