At the sprint there was some discussion of optimization and python call stacks. One place where we do many tiny calls is in is_foo_dtype checks
In [3]: arr = np.arange(10**5)
In [4]: %timeit is_float_dtype(arr)
1.23 µs ± 28.3 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [5]: %timeit is_float_dtype(arr.dtype)
678 ns ± 11 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [6]: %timeit arr.dtype.kind == 'f'
71.6 ns ± 1.87 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
~17x difference. Part of this is because is_foo_dtype will take either arr or arr.dtype. The potential savings stack up in places where we do many of these dtype checks on the same arguments.
Comment From: TomAugspurger
tangentially related, I was looking at the overhead of Series.sum() vs. np.nansum(series.values).
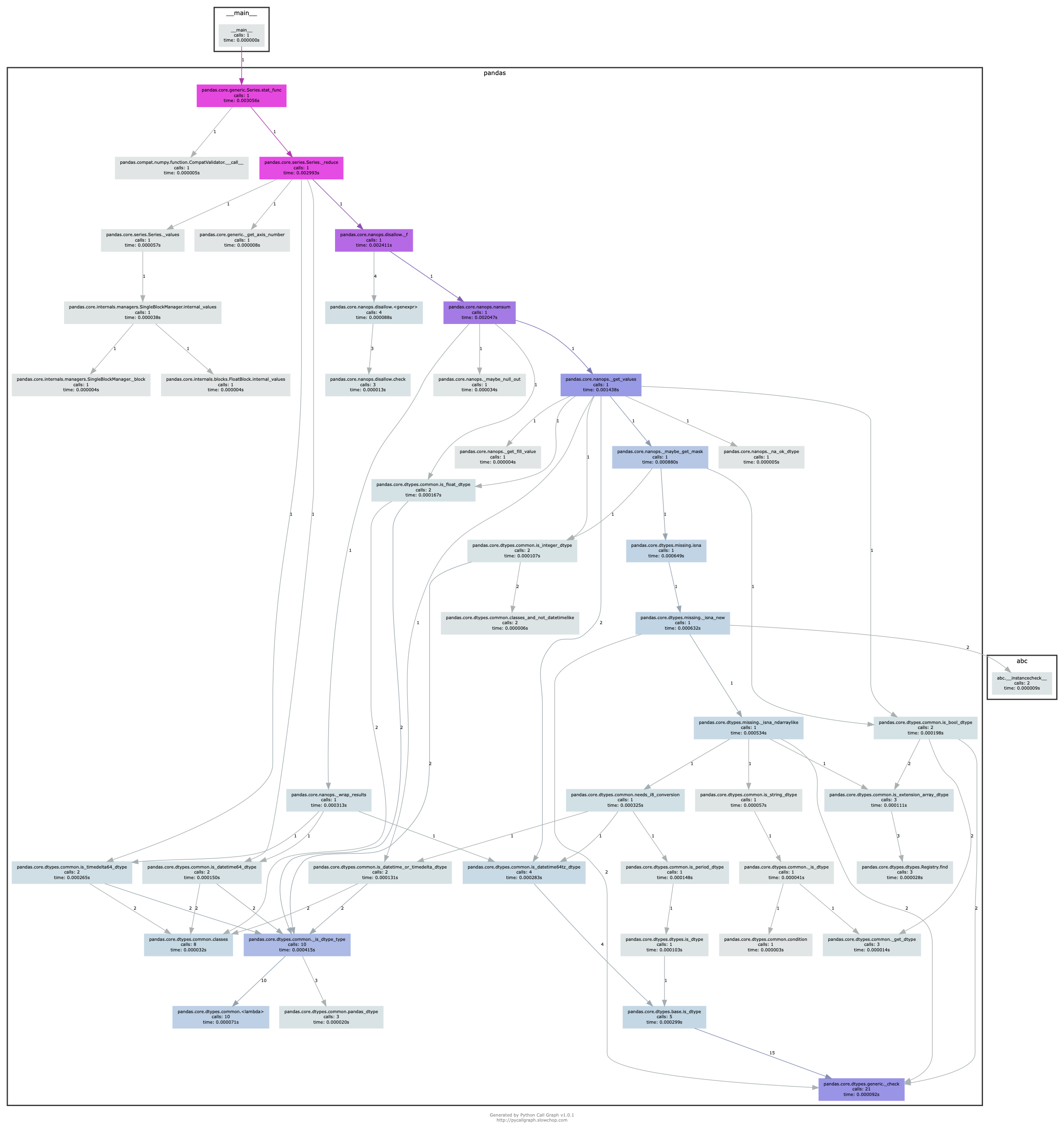
10 calls to is_dtype_type, and 21 isinstance(thing, ABCPandas*)!
Comment From: jbrockmendel
We could implement versions of these that are dtype-only. I don't think changing the existing ones is a option (at least not short-term) since they are exposed in the API
Comment From: jbrockmendel
We've eliminated many internal usages recently of these recently (#52682, #52649, #52607, #52582, #52564, #52527, #52506, #52387, #52288, #52279, #52213). Could deprecate e.g. is_datetime64_dtype.
Comment From: jbrockmendel
Closing as complete.