Pandas version checks
-
[X] I have checked that this issue has not already been reported.
-
[X] I have confirmed this bug exists on the latest version of pandas.
-
[ ] I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
import pandas as pd
pd.read_excel("path to file")
Issue Description
Hi! Since the update of openpyxl (31 january 2022) read_excel is no longer working properly to read excel files that have an active filter on them. With active filter i mean the filter function of excel where there is a selection active (for example one value in a column is excluded). Is there a method or way we can/argument to add in order to remove the auto filter from the file so that the file can be read again?
file from the pandas module where the error is found: site-packages/pandas/io/excel/_openpyxl.py error: Value must be either numerical or a string containing a wildcard
current version of pandas: 1.5.3 Version in which it worked from openpyxl 3.0.10 No longer working in latest two versions of openpyxl
Thank you in advance!
Expected Behavior
Read the file without the active filters so that all data is included
Installed Versions
Comment From: phofl
Hi, thanks for your report. Is this an intended feature from openpyxl? If no, you should probably open an issue there
Comment From: KiaraShannen
Hi, thanks for your report. Is this an intended feature from openpyxl? If no, you should probably open an issue there
Hi! Thank you for your quick response. Yes this was a conscious choice of openpyxl. Beneath you'll find the edit logs in which they keep the autofilter on the file as default table filter. In addition they do mention in their update that table filters are no longer overwritten.
https://foss.heptapod.net/openpyxl/openpyxl/-/commit/3af0b77f8a56820961e08e2e751026c984907a1d
Comment From: rhshadrach
I am not able to reproduce this, maybe I'm misunderstanding the issue. Here is my Excel file with row 3 filtered:
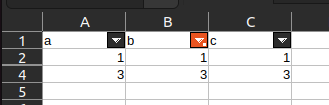
Then reading the file with openpyxl gives me all the data even though the filter is activated.
import openpyxl
print(openpyxl.__version__)
# 3.1.1
print(pd.read_excel('test.xlsx', engine='openpyxl'))
# a b c
# 0 1 1 1
# 1 2 2 2
# 2 3 3 3
Comment From: KiaraShannen
Okay as you were not able to reproduce i checked and it only occurs with files that have an active filter and some values of rows are empty
test file i created on which i get the error: test_file_error.xlsx
Comment From: rhshadrach
Thanks for the example workbook. Running this, the ValueError I get is raised from site-packages/openpyxl/worksheet/filters.py. It appears to me this is an issue for openpyxl.
Comment From: phofl
Closing