Pandas version checks
-
[X] I have checked that this issue has not already been reported.
-
[X] I have confirmed this bug exists on the latest version of pandas.
-
[X] I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
*file.csv*
design_parameters;design_parameters;design_parameters;functions;functions;functions
x_local;x_shared;x_shared;c_1;c_2;obj
0;0;1;0;0;0
1.0;4.000000000000002;3.0000000000000004;-14.597213815595694;-12.786069077975327;21.75722730061834
2.6642724137992957e-09;2.5200529286981936;1.5215140258817428e-09;-2.22264559568493;-19.15989414027956;5.39055181426381
--------------------------------------------------------------
import pandas as pd
df = pd.read_csv("file.csv", delimiter=";", header=[0, 1, 2])
# This .loc does not swap the columns as expected
# Expecting obj before x_shared
# Happens: x_shared before obj
df.loc[:, (slice(None), ["obj", "x_shared"], slice(None))]
# This .loc does swap the columns as expected
# Expected and happened: obj before x_shared before c_1
df.loc[:, (slice(None), ["obj", "x_shared", "c_1"], slice(None))]
Issue Description
Hey,
With some multi-index DataFrames, the .loc method does not seem to swap the columns as expected. Sometimes it does. Sometimes it does not.
A small exemple that shows the issue can be found above. The .csv I wrote down is a 3 level column indexed dataframe, with only 2 rows. There are only 6 columns. When using .loc, and according to the names I put in the second level (level=1) of multi-indexing, I have different behaviours. It can be tricky, especially when you use the .loc method just before converting to numpy, as I do.
I've tested with pandas v1.5.1, v1.4 and v2.0.0. Same behaviour.
Here is a behaviour capture:
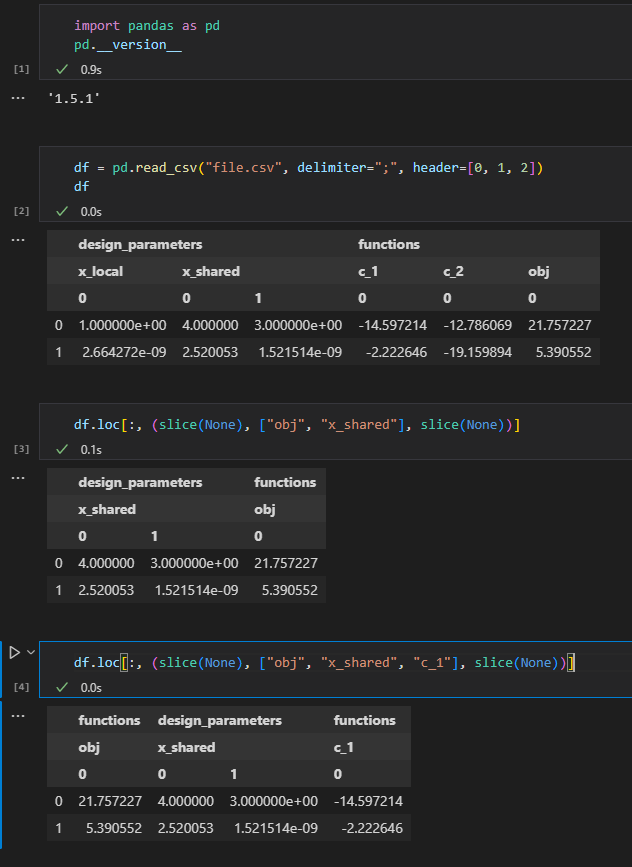
I probably miss something here. Might not be a bug, but I did not find any information on that matter, except an old Issue https://github.com/pandas-dev/pandas/issues/22797#issuecomment-423552244.
Thanks for your help,
Loïc
Expected Behavior
import pandas as pd df = pd.read_csv("file.csv", delimiter=";", header=[0, 1, 2]) df.loc[:, (slice(None), ["obj", "x_shared"], slice(None))]
obj column before x_shared
Installed Versions
Comment From: topper-123
Hi @LoicCousin, thanks for the bug report.
You are right, in that case the columns should have been swapped, we swap generally, when indexing using lists. Interesting that it works correctly, when adding the last level.
PRs welcome.