Create MultiIndex DataFrame
import pandas as pd
df = pd.DataFrame(
[
[5777, 100, 5385, 200, 5419, 4887, 100, 200],
[4849, 0, 4539, 0, 3381, 0, 0, ],
[4971, 0, 3824, 0, 4645, 3424, 0, 0, ],
[4827, 200, 3459, 300, 4552, 3153, 100, 200, ],
[5207, 0, 3670, 0, 4876, 3358, 0, 0, ],
],
index=pd.to_datetime(['2010-01-01',
'2010-01-02',
'2010-01-03',
'2010-01-04',
'2010-01-05']),
columns=pd.MultiIndex.from_tuples(
[('Portfolio A', 'GBP', 'amount'), ('Portfolio A', 'GBP', 'injection'),
('Portfolio B', 'EUR', 'amount'), ('Portfolio B', 'EUR', 'injection'),
('Portfolio A', 'USD', 'amount'), ('Portfolio A', 'USD', 'injection'),
('Portfolio B', 'JPY', 'amount'), ('Portfolio B', 'JPY', 'injection')])
).sortlevel(axis=1)
Add a column at Level 2
amount = df.loc[:, pd.IndexSlice[:, :, 'amount']]
inject = df.loc[:, pd.IndexSlice[:, :, 'injection']]
dav = amount - amount.shift() - inject.shift().values
dav.columns.set_levels(['daily_added_value'], level=2, inplace=True)
df = pd.concat([df, dav], axis=1).sortlevel(axis=1)
print(df.T) #transposed to fit only
I can repeat the add a column at Level 2 code above multiple times, however if I try the following I get an error (possibly related to NAN's):
dav1 = df.loc[:, pd.IndexSlice[:, :, 'daily_added_value']]
amount = df.loc[:, pd.IndexSlice[:, :, 'amount']]
dr = dav1 * amount
dr.columns.set_levels(['daily_return'], level=2, inplace=True)
df = pd.concat([df, dr], axis=1).sortlevel(axis=1)
Expected Output - ( daily_returns is added to level 2 ( daily_added_value * amount )
Note I have put zeros as expected values but the desired output is daily_added_value * amount) I am also adding other measures at level 2 with division and shift() in the formulae. These fail with same error.
2010-01-01 2010-01-02 2010-01-03 \
Portfolio A GBP amount 5777.0 4849.0 4971.0
daily_added_value NaN -1028.0 122.0
injection 100.0 0.0 0.0
USD amount 5419.0 3381.0 4645.0
daily_added_value NaN -6925.0 1264.0
daily_returns 0 0 0
injection 4887.0 0.0 3424.0
Portfolio B EUR amount 5385.0 4539.0 3824.0
daily_added_value NaN -1046.0 -715.0
injection 200.0 0.0 0.0
JPY amount 100.0 0.0 0.0
daily_added_value NaN -300.0 NaN
daily_returns 0 0 0
injection 200.0 NaN 0.0
2010-01-04 2010-01-05
Portfolio A GBP amount 4827.0 5207.0
daily_added_value -144.0 180.0
injection 200.0 0.0
USD amount 4552.0 4876.0
daily_added_value -3517.0 -2829.0
daily_returns 0 0 0
injection 3153.0 3358.0
Portfolio B EUR amount 3459.0 3670.0
daily_added_value -365.0 -89.0
injection 300.0 0.0
JPY amount 100.0 0.0
daily_added_value 100.0 -300.0
daily_returns 0 0 0
injection 200.0 0.0
Error
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-56-7a5afb5f45f1> in <module>()
2 amount = df.loc[:, pd.IndexSlice[:, :, 'amount']]
3 dr = dav1 * amount
----> 4 dr.columns.set_levels(['daily_return'], level=2, inplace=True)
5 df = pd.concat([df, dr], axis=1).sortlevel(axis=1)
C:\Users\xxxxxxxx\AppData\Local\Continuum\Anaconda3\lib\site-packages\pandas\indexes\multi.py in set_levels(self, levels, level, inplace, verify_integrity)
227 idx._reset_identity()
228 idx._set_levels(levels, level=level, validate=True,
--> 229 verify_integrity=verify_integrity)
230 if not inplace:
231 return idx
C:\Users\xxxxxxxx\AppData\Local\Continuum\Anaconda3\lib\site-packages\pandas\indexes\multi.py in _set_levels(self, levels, level, copy, validate, verify_integrity)
164
165 if verify_integrity:
--> 166 self._verify_integrity()
167
168 def set_levels(self, levels, level=None, inplace=False,
C:\Users\xxxxxxxx\AppData\Local\Continuum\Anaconda3\lib\site-packages\pandas\indexes\multi.py in _verify_integrity(self)
127 " level (%d). NOTE: this index is in an"
128 " inconsistent state" % (i, label.max(),
--> 129 len(level)))
130
131 def _get_levels(self):
ValueError: On level 2, label max (1) >= length of level (1). NOTE: this index is in an inconsistent state
How do you make the index consistent?
output of pd.show_versions()
INSTALLED VERSIONS
------------------
commit: None
python: 3.5.2.final.0
python-bits: 64
OS: Windows
OS-release: 7
machine: AMD64
processor: Intel64 Family 6 Model 62 Stepping 4, GenuineIntel
byteorder: little
LC_ALL: None
LANG: None
pandas: 0.18.1
nose: 1.3.7
pip: 8.1.2
setuptools: 23.0.0
Cython: 0.24
numpy: 1.11.1
scipy: 0.17.1
statsmodels: 0.6.1
xarray: None
IPython: 4.2.0
sphinx: 1.3.1
patsy: 0.4.1
dateutil: 2.5.3
pytz: 2016.4
blosc: None
bottleneck: 1.1.0
tables: 3.2.2
numexpr: 2.6.0
matplotlib: 1.5.1
openpyxl: 2.3.2
xlrd: 1.0.0
xlwt: 1.1.2
xlsxwriter: 0.9.2
lxml: 3.6.0
bs4: 4.4.1
html5lib: None
httplib2: None
apiclient: None
sqlalchemy: 1.0.13
pymysql: None
psycopg2: None
jinja2: 2.8
boto: 2.40.0
pandas_datareader: 0.2.1
This post is also raised as a question and also related to this question
Comment From: jorisvandenbossche
See also the discussion on gitter
Comment From: toasteez
This works (needed values to align.
dav = df.loc[:, pd.IndexSlice[:, :, 'daily_added_value']]
amount = df.loc[:, pd.IndexSlice[:, :, 'amount']]
dr = (dav.shift(-1).values / amount) * 100
Comment From: toasteez
Is there a better way to align?
Comment From: toasteez
I am reopening as there does not seem to be consistent behavior for a cumprod formula? 100*((1+dr / 100).cumprod()-1)
Comment From: toasteez
I tried the set_levels with verify_integrity = False but this yieds:
The failing command can be changed to drc.columns.set_levels(['daily_return_cumulative'], level=2, inplace=True, verify_integrity = False) however this yields an algos.cp35-win_amd64.pyd unhandled exception
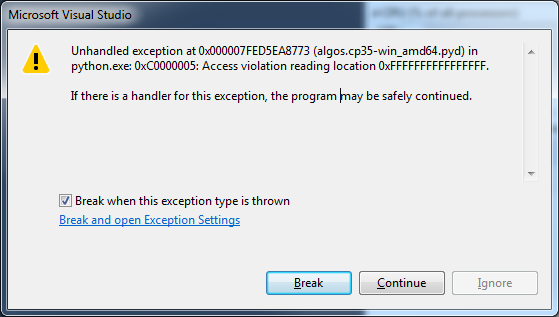
Comment From: toasteez
Code for checking:
import pandas as pd
import numpy as np
df = pd.DataFrame(
[
[5777, 100, 5385, 200, 5419, 4887, 100, 200],
[4849, 0, 4539, 0, 3381, 0, 0, ],
[4971, 0, 3824, 0, 4645, 3424, 0, 0, ],
[4827, 200, 3459, 300, 4552, 3153, 100, 200, ],
[5207, 0, 3670, 0, 4876, 3358, 0, 0, ],
],
index=pd.to_datetime(['2010-01-01',
'2010-01-02',
'2010-01-03',
'2010-01-04',
'2010-01-05']),
columns=pd.MultiIndex.from_tuples(
[('Portfolio A', 'GBP', 'amount'), ('Portfolio A', 'GBP', 'injection'),
('Portfolio B', 'EUR', 'amount'), ('Portfolio B', 'EUR', 'injection'),
('Portfolio A', 'USD', 'amount'), ('Portfolio A', 'USD', 'injection'),
('Portfolio B', 'JPY', 'amount'), ('Portfolio B', 'JPY', 'injection')])
).sortlevel(axis=1)
amount = df.loc[:, pd.IndexSlice[:, :, 'amount']]
inject = df.loc[:, pd.IndexSlice[:, :, 'injection']]
dav = amount - amount.shift() - inject.shift().values
dav.columns.set_levels(['daily_added_value'], level=2, inplace=True)
df = pd.concat([df, dav], axis=1).sortlevel(axis=1)
dav = df.loc[:, pd.IndexSlice[:, :, 'daily_added_value']]
amount = df.loc[:, pd.IndexSlice[:, :, 'amount']]
dr = (dav.values / amount.shift()) * 100
dr.columns.set_levels(['daily_return'], level=2, inplace=True)
df = pd.concat([df, dr], axis=1).sortlevel(axis=1)
## TODO Fail
dr = df.loc[:, pd.IndexSlice[:, :, 'daily_return']]
drc = (100 * (1 + dr / 100).cumprod()-1)
drc = drc.replace([np.inf, -np.inf], np.nan)
print(drc.head()) # DataFrame looks OK???
# Fails here when verify_integrity is True (levels.max() recursion error and when False algo exception
drc.columns.set_levels(['dr_cumulative'], level=2, inplace=True, verify_integrity = False)
df = pd.concat([df, drc], axis=1).sort_index(axis=1)`
Comment From: jorisvandenbossche
@toasteez I opened a separate issue for the inplace=True case: https://github.com/pydata/pandas/issues/13754
Comment From: toasteez
Great :+1: The work around I am using is:
def map_level(df, dct, level=2):
index = df.index
index.set_levels([[dct.get(item, item) for item in names] if i==level else names
for i, names in enumerate(index.levels)], inplace=True)
dct = {'daily_return':'daily_cumulative_return'}
map_level(drc.T, dct, level=2)
Comment From: bkandel
@toasteez If I understand your question correctly, the issue here is that set_levels is not doing what you think it's doing. A MultiIndex has a levels component and a labels component. The levels are the various names for the different values that the MultiIndex can take on, and the labels associates each column with a given level. When you say set_levels, what you're doing is changing the possible names that a column can have, but importantly, you're not changing the labels. So concretely, if you have the following MultiIndex:
In [1]: multi = MultiIndex.from_product([['A', 'B'], ['a', 'b']])
In [2]: multi
Out[2]:
MultiIndex(levels=[[u'A', u'B'], [u'a', u'b']],
labels=[[0, 0, 1, 1], [0, 1, 0, 1]])
and then change the levels at the second layer to 'a', you will get an error because the labels say that you should look at the second entry in the list to find the correct column header, but there is only one entry in the list.
That's what's happening in your example. The columns for dr look like:
In [3]: dr.columns
Out[3]:
MultiIndex(levels=[[u'Portfolio A', u'Portfolio B'], [u'EUR', u'GBP', u'JPY', u'USD'], [u'amount', u'daily_added_value']],
labels=[[0, 0, 0, 0, 1, 1, 1, 1], [1, 1, 3, 3, 0, 0, 2, 2], [0, 1, 0, 1, 0, 1, 0, 1]])
and if you set the last level to be a list of length 1, your labels value will still be saying that you should look at the second entry in the list, which doesn't exist. That's why you get the error, which states that On level 2, label max (1) >= length of level (1), because that's exactly what's happening here.
If you want to reset the level from scratch, you would need to do droplevel and reconstruct it or something similar (something like this: http://stackoverflow.com/questions/14744068/prepend-a-level-to-a-pandas-multiindex).
Comment From: bkandel
@jorisvandenbossche I think this can be closed unless @toasteez objects -- I don't see any further action here.
Comment From: xoelop
I think this is still not working.
In this case, selecting top-level columns from a multiindex of a df:
data = sales.set_index(keys=[sales.index, 'descr', 'PERIODO'])
data = data.unstack(['descr', 'PERIODO'])[cols]
and then making
res.columns.levels[0]
the result is bigger than cols. It's the same columns that the original DataFrame (sales) had
Comment From: sorenwacker
I still get this error when trying to set level values of a multiindex.