Code Sample, a copy-pastable example if possible
The code above works in py2 but not works in py3.
Expected Output
should get sorted dataframe.
output of pd.show_versions()
0.18.0
Comment From: jorisvandenbossche
Can you please provide a reproducible example? (some code that constructs an example dataframe and shows the problem)
Comment From: seanDot7
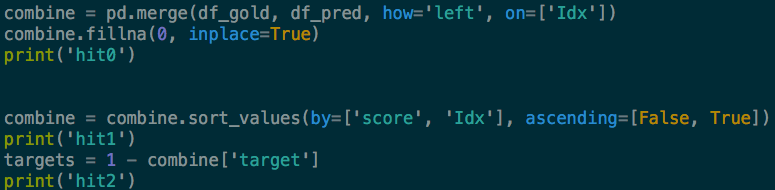
Source code scorer.py:
# -*- coding:utf-8 -*-
import argparse
import json
import pandas as pd
import numpy as np
# from sklearn.metrics import precision_recall_curve
def main():
parser = argparse.ArgumentParser(description='score generator.' )
parser.add_argument('-s', '--submit_file', type=str, required=True, help='the submit file' )
parser.add_argument('-t','--test_file', type=str, required=True, help='the test file' )
args= parser.parse_args( )
pre_cutoff = 0.97
# sample_cutoff = 1662587
df_gold = pd.read_csv(args.test_file, sep=',', names=['Idx', 'target'], header=0)
# y_true = df_gold[df_gold['sampleid'] <= sample_cutoff]['label']
df_pred = pd.read_csv(args.submit_file, sep=',', names=['Idx', 'score'], header=0)
# y_pred = df_pred[df_pred['sampleid'] <= sample_cutoff]['prob']
# print(df_pred.dtypes)
combine = pd.merge(df_gold, df_pred, how='left', on=['Idx'])
combine.fillna(0, inplace=True)
result = sorted(combine.itertuples(index=False), key=lambda x:(-x[2], x[0]))
combine = pd.DataFrame(result)
# combine = combine.sort_values(by=['score', 'Idx'], ascending=[False, True])
targets = 1 - combine['target']
# scores = combine['score']
targets_cumsum = targets.cumsum().astype(float)
precision = targets_cumsum / np.arange(1, len(targets) + 1)
recall = targets_cumsum / targets.sum().astype(float)
filtered_recall = recall[(precision >= pre_cutoff) == True]
# precision2, recall2, threshold2 = precision_recall_curve(targets, scores)
# filtered_recall2 = recall2[(precision2 >= pre_cutoff) == True]
if len(filtered_recall) > 0:
score = max(filtered_recall)
# score2 = max(filtered_recall2)
result = {
'code': 0,
'score': score,
# 'score2': score2,
'message': 'success'
}
else:
message = u'error %s' % pre_cutoff
result = {
'code': 1,
'score': 0,
'message': message
}
print (json.dumps(result))
if __name__ == "__main__":
main()
Command to run it:
answer.csv and prediction.csv are both in the .zip file.
$ python scorer.py -t answer.csv -s prediction.csv
Comment From: jreback
pls narrow this down and make it copy pastable
Comment From: TomAugspurger
@seanDot7 let us know if you can make a small reproducible example.