Hello,
I recently upgraded from pandas 0.17.1 to 0.18.1 and ran into a performance regression with DataFrame.to_csv:
Code Sample, a copy-pastable example if possible
import pandas import numpy import tempfile fd, filename = tempfile.mkstemp(prefix='to_csv_', suffix='.csv') test = pandas.DataFrame(numpy.random.rand(2000, 5000)) %timeit test.to_csv(filename, sep=';', index=False, header=False)
In pandas 0.17.1: 1 loop, best of 3: 6.86 s per loop
In pandas 0.18.1: 1 loop, best of 3: 21.9 s per loop
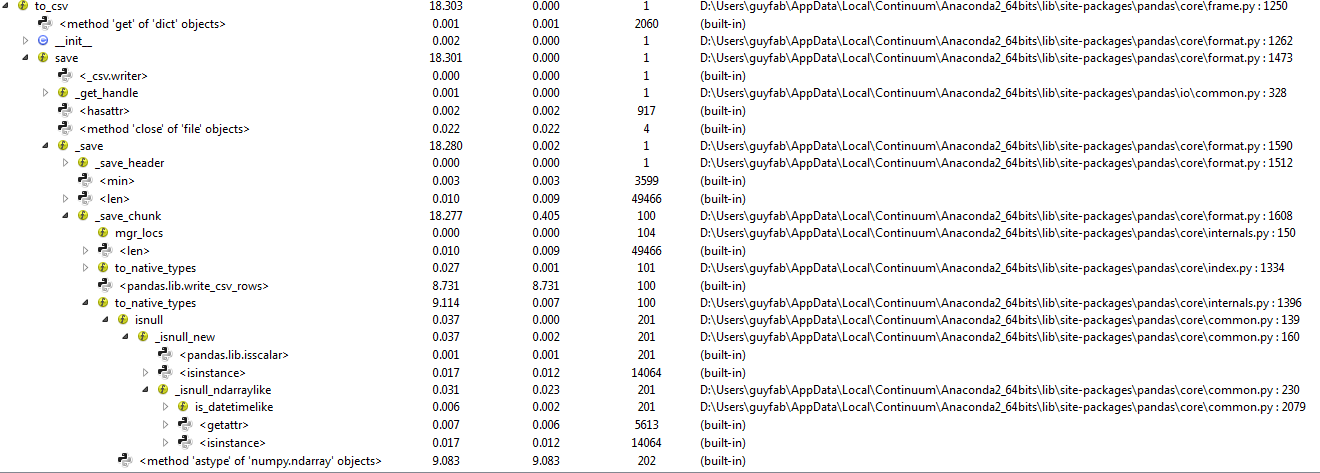
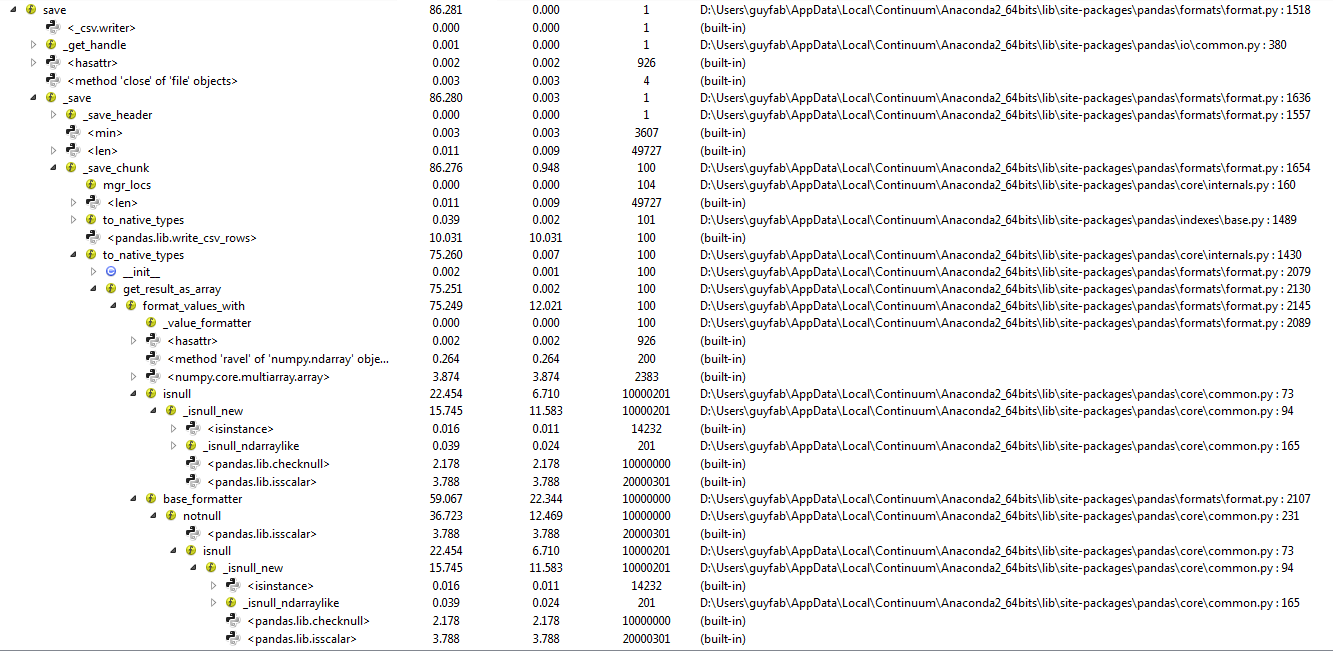
You will find attached the results given by the Spyder profiler running this code in both version.
Most of the time (in pandas 0.18.1) is spent in the pandas.isnull method.
output of pd.show_versions()
INSTALLED VERSIONS
commit: None python: 2.7.11.final.0 python-bits: 64 OS: Windows OS-release: 7 machine: AMD64 processor: Intel64 Family 6 Model 60 Stepping 3, GenuineIntel byteorder: little LC_ALL: None LANG: fr_FR
pandas: 0.18.1
nose: 1.3.7
pip: 8.1.1
setuptools: 20.3
Cython: 0.23.4
numpy: 1.10.4
scipy: 0.17.0
statsmodels: None
xarray: None
IPython: 4.1.2
sphinx: 1.3.5
patsy: 0.4.0
dateutil: 2.5.1
pytz: 2016.2
blosc: None
bottleneck: 1.0.0
tables: 3.2.2
numexpr: 2.5
matplotlib: 1.5.1
openpyxl: 2.3.2
xlrd: 0.9.4
xlwt: 1.0.0
xlsxwriter: 0.8.4
lxml: 3.6.0
bs4: 4.4.1
html5lib: None
httplib2: None
apiclient: None
sqlalchemy: 1.0.12
pymysql: None
psycopg2: None
jinja2: 2.8
boto: 2.39.0
pandas_datareader: None
None
Comment From: jreback
In [1]: pd.__version__
Out[1]: u'0.17.1'
In [7]: %timeit test.to_csv(filename, sep=';', index=False, header=False)
1 loop, best of 3: 6 s per loop
%timeit test.to_csv(filename, sep=';', index=False, header=False)
In [1]: pd.__version__
Out[1]: u'0.18.1'
1 loop, best of 3: 16 s per loop
In [28]: pd.__version__
Out[28]: '0.18.1+403.ga0151a7'
1 loop, best of 3: 5.91 s per loop
In [28]: pd.__version__
Out[28]: '0.18.1+403.ga0151a7'
I think this was caused by this: https://github.com/pydata/pandas/issues/12922
though looks ok in master/0.19.0 (soon)