Just to raise eyebrows, not sure if it's related to pandas-0.19 or to a bug of myself. It is ok under Pandas-0.18.1 (and seems not related to Python-3.6)
A small, complete example of the issue
# in Ipython
#Pandas
import pandas as pd
import numpy as np
idx = pd.date_range('2000', '2005', freq='d', closed='left')
datas = pd.DataFrame({'Color': [ 'green' if x> 1 else 'red' for x in np.random.randn(len(idx))],
'Measure': np.random.randn(len(idx)), 'Year': idx.year},
index=idx)
#datas.head()
# checking baresql
from __future__ import print_function, unicode_literals, division # line needed only if Python2.7
from baresql import baresql
bsql = baresql.baresql(connection="sqlite:///.baresql.db")
bsqldf = lambda q: bsql.df(q, dict(globals(),**locals()))
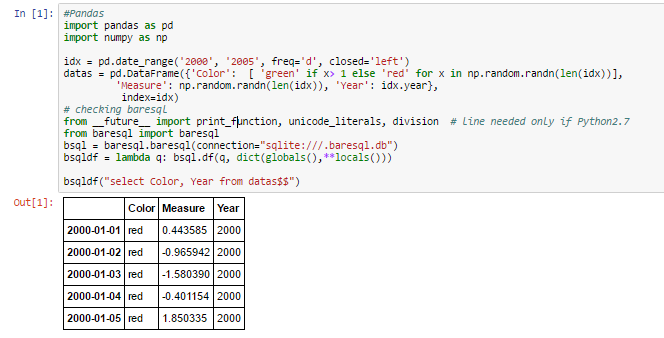
bsqldf("select Color, Year from datas$$")
Expected Output
this:
Output of pd.show_versions()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
pandas/index.pyx in pandas.index.DatetimeEngine.get_loc (pandas\index.c:11091)()
pandas/src/hashtable_class_helper.pxi in pandas.hashtable.Int64HashTable.get_item (pandas\hashtable.c:8120)()
TypeError: an integer is required
During handling of the above exception, another exception occurred:
KeyError Traceback (most recent call last)
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\indexes\base.py in get_loc(self, key, method, tolerance)
2103 try:
-> 2104 return self._engine.get_loc(key)
2105 except KeyError:
pandas/index.pyx in pandas.index.DatetimeEngine.get_loc (pandas\index.c:11241)()
pandas/index.pyx in pandas.index.DatetimeEngine.get_loc (pandas\index.c:11147)()
pandas/index.pyx in pandas.index.DatetimeEngine._date_check_type (pandas\index.c:11311)()
KeyError: 'next'
During handling of the above exception, another exception occurred:
TypeError Traceback (most recent call last)
pandas/index.pyx in pandas.index.DatetimeEngine.get_loc (pandas\index.c:11091)()
pandas/src/hashtable_class_helper.pxi in pandas.hashtable.Int64HashTable.get_item (pandas\hashtable.c:8120)()
TypeError: an integer is required
During handling of the above exception, another exception occurred:
KeyError Traceback (most recent call last)
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\tseries\index.py in get_loc(self, key, method, tolerance)
1410 try:
-> 1411 return Index.get_loc(self, key, method, tolerance)
1412 except (KeyError, ValueError, TypeError):
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\indexes\base.py in get_loc(self, key, method, tolerance)
2105 except KeyError:
-> 2106 return self._engine.get_loc(self._maybe_cast_indexer(key))
2107
pandas/index.pyx in pandas.index.DatetimeEngine.get_loc (pandas\index.c:11241)()
pandas/index.pyx in pandas.index.DatetimeEngine.get_loc (pandas\index.c:11147)()
pandas/index.pyx in pandas.index.DatetimeEngine._date_check_type (pandas\index.c:11311)()
KeyError: 'next'
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
ValueError: Error parsing datetime string "next" at position 0
The above exception was the direct cause of the following exception:
SystemError Traceback (most recent call last)
<ipython-input-7-526f069d545f> in <module>()
----> 1 bsqldf('''select Color, Year from datas$$ ''')
<ipython-input-2-7f10bad21e85> in <lambda>(q)
3 from baresql import baresql
4 bsql = baresql.baresql(connection="sqlite:///.baresql.db")
----> 5 bsqldf = lambda q: bsql.df(q, dict(globals(),**locals()))
6
7 users = ['Alexander', 'Billy', 'Charles', 'Danielle', 'Esmeralda', 'Franz', 'Greg']
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\baresql\baresql.py in df(self, q, env)
506 def df(self, q, env):
507 "same as .cursor , but returns a pandas dataframe"
--> 508 cur = self.cursor( q, env)
509 result = None
510 rows = cur.fetchall()
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\baresql\baresql.py in cursor(self, q, env)
483 pre_q = "DROP TABLE IF EXISTS %s" % table_sql.join(self.delimiters)
484 cur = self._execute_sql (pre_q)
--> 485 self._write_table( table_sql, df, self.conn)
486 #multiple sql must be executed one by one
487 for q_single in self.get_sqlsplit(sql, True) :
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\baresql\baresql.py in _write_table(self, tablename, df, conn)
450 to_sql(df, name = tablename, con = self.conn, flavor = self.engine)
451 else:
--> 452 to_sql(df, name = tablename, con = self.conn)
453
454
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\io\sql.py in to_sql(frame, name, con, flavor, schema, if_exists, index, index_label, chunksize, dtype)
468 pandas_sql.to_sql(frame, name, if_exists=if_exists, index=index,
469 index_label=index_label, schema=schema,
--> 470 chunksize=chunksize, dtype=dtype)
471
472
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\io\sql.py in to_sql(self, frame, name, if_exists, index, index_label, schema, chunksize, dtype)
1498 table = SQLiteTable(name, self, frame=frame, index=index,
1499 if_exists=if_exists, index_label=index_label,
-> 1500 dtype=dtype)
1501 table.create()
1502 table.insert(chunksize)
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\io\sql.py in __init__(self, *args, **kwargs)
1261 # (this is what sqlalchemy does)
1262 sqlite3.register_adapter(time, lambda _: _.strftime("%H:%M:%S.%f"))
-> 1263 super(SQLiteTable, self).__init__(*args, **kwargs)
1264
1265 def sql_schema(self):
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\io\sql.py in __init__(self, name, pandas_sql_engine, frame, index, if_exists, prefix, index_label, schema, keys, dtype)
560 if frame is not None:
561 # We want to initialize based on a dataframe
--> 562 self.table = self._create_table_setup()
563 else:
564 # no data provided, read-only mode
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\io\sql.py in _create_table_setup(self)
1297 """
1298 column_names_and_types = \
-> 1299 self._get_column_names_and_types(self._sql_type_name)
1300
1301 pat = re.compile('\s+')
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\io\sql.py in _get_column_names_and_types(self, dtype_mapper)
755 dtype_mapper(self.frame.iloc[:, i]),
756 False)
--> 757 for i in range(len(self.frame.columns))
758 ]
759
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\io\sql.py in <listcomp>(.0)
755 dtype_mapper(self.frame.iloc[:, i]),
756 False)
--> 757 for i in range(len(self.frame.columns))
758 ]
759
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\io\sql.py in _sql_type_name(self, col)
1338 return dtype[col.name]
1339
-> 1340 col_type = self._get_notnull_col_dtype(col)
1341 if col_type == 'timedelta64':
1342 warnings.warn("the 'timedelta' type is not supported, and will be "
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\io\sql.py in _get_notnull_col_dtype(self, col)
846 col_for_inference = col
847 if col.dtype == 'object':
--> 848 notnulldata = col[~isnull(col)]
849 if len(notnulldata):
850 col_for_inference = notnulldata
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\core\series.py in __getitem__(self, key)
634 raise
635
--> 636 if is_iterator(key):
637 key = list(key)
638
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\types\inference.py in is_iterator(obj)
35 def is_iterator(obj):
36 # python 3 generators have __next__ instead of next
---> 37 return hasattr(obj, 'next') or hasattr(obj, '__next__')
38
39
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\core\generic.py in __getattr__(self, name)
2740 return object.__getattribute__(self, name)
2741 else:
-> 2742 if name in self._info_axis:
2743 return self[name]
2744 return object.__getattribute__(self, name)
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\tseries\base.py in __contains__(self, key)
232 def __contains__(self, key):
233 try:
--> 234 res = self.get_loc(key)
235 return is_scalar(res) or type(res) == slice or np.any(res)
236 except (KeyError, TypeError, ValueError):
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\tseries\index.py in get_loc(self, key, method, tolerance)
1417
1418 try:
-> 1419 stamp = Timestamp(key, tz=self.tz)
1420 return Index.get_loc(self, stamp, method, tolerance)
1421 except (KeyError, ValueError):
pandas/tslib.pyx in pandas.tslib.Timestamp.__new__ (pandas\tslib.c:9932)()
pandas/tslib.pyx in pandas.tslib.convert_to_tsobject (pandas\tslib.c:25231)()
pandas/tslib.pyx in pandas.tslib.convert_str_to_tsobject (pandas\tslib.c:26851)()
pandas/src/datetime.pxd in datetime._string_to_dts (pandas\tslib.c:87106)()
SystemError: <class 'str'> returned a result with an error set
Comment From: jreback
can you show an example not using an external library
Comment From: stonebig
Well, I could jut import the cell before from github
%load https://raw.githubusercontent.com/stonebig/baresql/master/baresql/baresql.py
run the cell, then
#Pandas
import pandas as pd
import numpy as np
idx = pd.date_range('2000', '2005', freq='d', closed='left')
datas = pd.DataFrame({'Color': [ 'green' if x> 1 else 'red' for x in np.random.randn(len(idx))],
'Measure': np.random.randn(len(idx)), 'Year': idx.year},
index=idx)
# checking baresql
#from __future__ import print_function, unicode_literals, division # line needed only if Python2.7
#from baresql import baresql
#bsql = baresql.baresql(connection="sqlite:///.baresql.db")
#bsqldf = lambda q: bsql.df(q, dict(globals(),**locals()))
bsqldf("select Color, Year from datas$$")
Sorry I don't know how to make it smaller. .. maybe some logs of sql orders.. 1 minute
Comment From: jreback
my point is pls show an example that does include an external library that is not a dependency of pandas. otherwise this is not a pandas issue.
Comment From: stonebig
ok, I close and will re-open if I find a smaller pure pandas example.
Comment From: jorisvandenbossche
@stonebig for me this is working with pandas 0.19.0 and python 3.5
Comment From: stonebig
Yes, the error came on my face on Python-3.6.0b2, then b3, then I thought it was also on Python-3.5... no more sure . With Python3.6 comes sqlite 3.14.2, and python beta3 bugs . I'm on windows also ... not sure it can have an effect for this.
Comment From: stonebig
my problem goes away (under Pandas-0.19.0 / Python-3.6.0b3) if I remove the index from the original dataframe
idx = pd.date_range('2000', '2005', freq='d', closed='left')
datas = pd.DataFrame({'Color': [ 'green' if x> 1 else 'red' for x in np.random.randn(len(idx))],
'Measure': np.random.randn(len(idx)), 'Year': idx.year}
# ,index=idx
)
Comment From: stonebig
even better, the error goes away under Python-3.6.0b3 if I use "idx.date":
datas = pd.DataFrame({'Color': [ 'green' if x> 1 else 'red' for x in np.random.randn(len(idx))],
'Measure': np.random.randn(len(idx)), 'Year': idx.year}
,index=idx.date
)
any explanation ? I suppose it should work on Python 3.4/3.5 also .. Is it to report as a bug to python-3.6 team ?
Comment From: jorisvandenbossche
@stonebig it would be interesting if you could check that it is for sure related to the use of 3.6
Also, if it is a bug in python 3.6 (or in pandas due to changes in python 3.6), it would still be useful if you could try to trim down the example to a small reproducible code snippet. For example, you can start with localizing which line in your code triggers the error, and then see if you can reproduce what that single line does in itself.
Comment From: stonebig
@jorisvandenbossche I'm not equipped to nail down this. I didn't do anything fancy, so it should show up when CI systems will have a nice python-3.6 toolchain.
Comment From: jorisvandenbossche
@stonebig You can do more than you think!
As an example: if you look at the traceback you posted above, you see:
C:\WinPython\basedir36\build\winpython-64bit-3.6.x.0\python-3.6.0b3.amd64\lib\site-packages\pandas\io\sql.py in _get_notnull_col_dtype(self, col)
846 col_for_inference = col
847 if col.dtype == 'object':
--> 848 notnulldata = col[~isnull(col)]
849 if len(notnulldata):
850 col_for_inference = notnulldata
(this is the latest traceback from the io.sql code). col is one of the columns of your dataframe. So trying that code line with your example dataframe:
In [1]: idx = pd.date_range('2000', '2005', freq='d', closed='left')
...: datas = pd.DataFrame({'Color': [ 'green' if x> 1 else 'red' for x in np.random.randn(len(idx))],
...: 'Measure': np.random.randn(len(idx)), 'Year': idx.year},
...: index=idx)
In [2]: col = datas['Color']
In [3]: col[~pd.isnull(col)]
....
SystemError: <class 'str'> returned a result with an error set
also triggers the error!
So further simplifying the reproducible example:
In [4]: col = pd.Series(['a', 'b', 'c', 'd'], index=pd.date_range('2012-01-01', periods=4))
In [5]: col[~pd.isnull(col)]
....
SystemError: <class 'str'> returned a result with an error set
In [6]: col = pd.Series(['a', 'b', 'c', 'd'])
In [7]: col[~pd.isnull(col)]
Out[7]:
0 a
1 b
2 c
3 d
dtype: object
So when there is a non-integer index, the line raises an error, with default index it passes fine. This does not yet explain the error, but it's already much easier to start debugging with this.
So the above example works fine with python 3.5 / pandas 0.19.0, but fails in python 3.6. Reopening.
Comment From: jorisvandenbossche
Further trimming dow gives me hasattr(col, 'next') (from _is_iterator) raising the error, which calls somewhere pd.Timestamp('next'). Currently this raises a ValueError (not being able to convert it), while with 3.6 it raises a SystemError, which is not captured in the conversion code.
Comment From: stonebig
I should beat myself, slowing Pandas-0.19.1 release by disturbing you on Python-3.6.0b3
Comment From: jorisvandenbossche
:-) Don't worry, you can expect it tomorrow in any case
Comment From: jorisvandenbossche
@stonebig Opened a new issue for this datetime parsing bug, so it is more focused: https://github.com/pandas-dev/pandas/issues/14561