INSTALLED VERSIONS
commit: None python: 2.7.12.final.0 python-bits: 32 OS: Windows OS-release: 7 machine: AMD64 processor: Intel64 Family 6 Model 60 Stepping 3, GenuineIntel byteorder: little LC_ALL: None LANG: None LOCALE: None.None
pandas: 0.19.0 nose: 1.3.7 pip: 8.1.1 setuptools: 28.7.1 Cython: 0.25.1 numpy: 1.11.2 scipy: 0.18.1 statsmodels: 0.6.1 xarray: None IPython: 5.1.0 sphinx: 1.4.8 patsy: 0.4.1 dateutil: 2.5.3 pytz: 2016.7 blosc: None bottleneck: None tables: 3.2.2 numexpr: 2.6.1 matplotlib: 1.5.3 openpyxl: 2.4.0 xlrd: 1.0.0 xlwt: 1.1.2 xlsxwriter: 0.9.3 lxml: 3.6.0 bs4: 4.5.1 html5lib: None httplib2: None apiclient: None sqlalchemy: 1.1.3 pymysql: None psycopg2: None jinja2: 2.8 boto: 2.43.0 pandas_datareader: None
Comment From: jreback
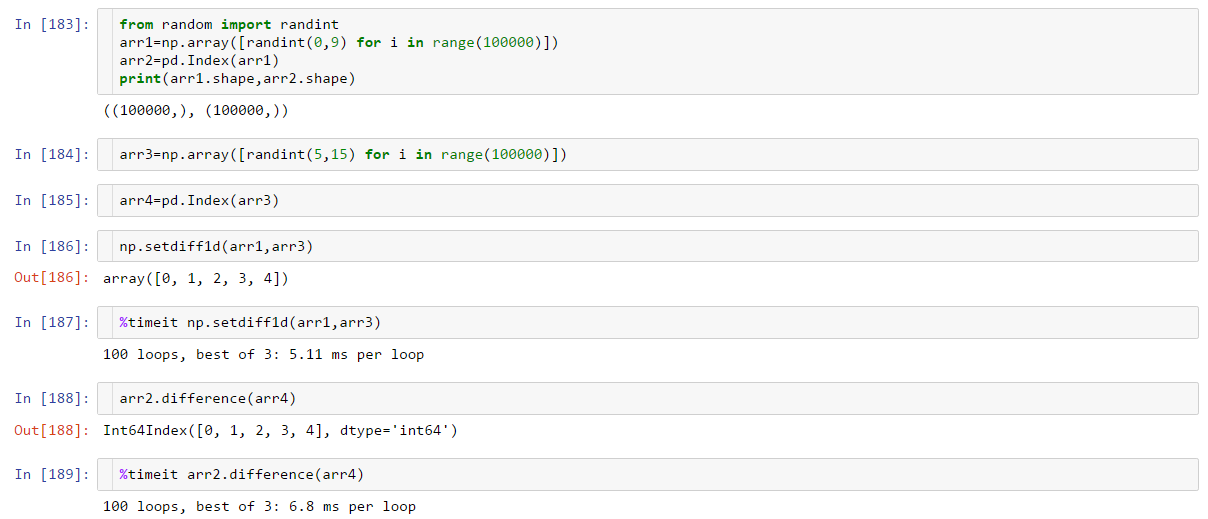
this uses uses setdiff1d when possible for smaller data sets and hashtables otherwise cutoff is 1mm iirc
Comment From: den-run-ai
@jreback I think something is wrong in pandas - it is 2-3 times slower than numpy at 1e7 elements. Also pandas is upcasting from int32 to int64, which may partially explain this slowdown.
Here is the full notebook with comparison and my SO answer:
https://gist.github.com/denfromufa/2821ff59b02e9482be15d27f2bbd4451
http://stackoverflow.com/a/31881491/2230844