(1)
def groupby_func(x):
#computing speedup, relative to first line
return x.iloc[0, :] / x.iloc[0: , :] # (with '0')
sdf_size = odf.loc[:, cols].groupby(by="size").apply(groupby_func)
(2)
def groupby_func(x):
#computing speedup, relative to first line
return x.iloc[0, :] / x.iloc[: , :] # (without '0')
sdf_size = odf.loc[:, cols].groupby(by="size").apply(groupby_func)
Problem description
For the version (1) and (2) I get two different outputs. When I print 'sdf_size' on the console:
(1)
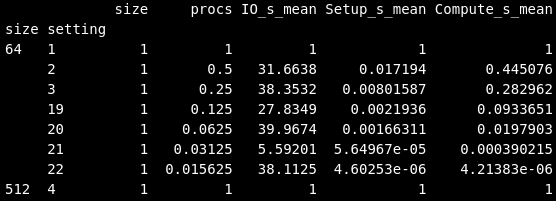
(2)
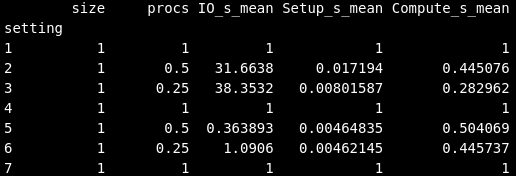
Somehow, with '0:' the (printed) result is how I wanted it to be (see screenshots, grouping of size in index). But after deleting the 0, which I expected to be unnecessary, I got a different result, which I didn't expect to be different (I think '0:' and ':' to be same -- correct me if I am wrong on this). An explicit setting of "group_keys=True" didn't change anything.
Just ask if something is unclear.
Thank you.
Output of pd.show_versions()
Comment From: TomAugspurger
Reproducible example:
In [3]: df = pd.DataFrame(np.random.randn(10, 2), columns=['a', 'b'])
In [4]: df['c'] = np.random.choice([0, 1], size=len(df))
In [5]: df
Out[5]:
a b c
0 1.993989 -0.443380 0
1 0.451656 -1.374338 1
2 -0.341937 0.095889 1
3 0.831831 -0.119458 0
4 0.506889 -0.405047 0
5 -1.802596 -0.409155 0
6 -0.085620 -2.005494 1
7 -0.230276 -0.709994 1
8 -0.337890 1.010063 1
9 -0.900651 0.611446 0
In [6]: df.groupby('c').apply(lambda x: x.iloc[0, :] / x.iloc[:, :])
Out[6]:
a b c
0 1.000000 1.000000 NaN
1 1.000000 1.000000 1.0
2 -1.320873 -14.332663 1.0
3 2.397109 3.711587 NaN
4 3.933775 1.094639 NaN
5 -1.106177 1.083648 NaN
6 -5.275115 0.685287 1.0
7 -1.961371 1.935705 1.0
8 -1.336693 -1.360647 1.0
9 -2.213942 -0.725134 NaN
In [7]: df.groupby('c').apply(lambda x: x.iloc[0, :] / x.iloc[0:, :])
Out[7]:
a b c
c
0 0 1.000000 1.000000 NaN
3 2.397109 3.711587 NaN
4 3.933775 1.094639 NaN
5 -1.106177 1.083648 NaN
9 -2.213942 -0.725134 NaN
1 1 1.000000 1.000000 1.0
2 -1.320873 -14.332663 1.0
6 -5.275115 0.685287 1.0
7 -1.961371 1.935705 1.0
8 -1.336693 -1.360647 1.0
@elDan101 does changing your code to sdf_size = odf.loc[:, cols].groupby(by="size").transform(groupby_func) solve your issue (using transform instead of apply)? .apply does quite a bit of inference to make things come out "right", but this is a clear case of a transform. I don't know for sure, but I'm guessing there's some kind of identity check in .apply, and df.iloc[0:, :] is not df.
Comment From: elDan101
I c&p your suggestion, but an exception was thrown which I wasn't able to quickly solve
Comment From: TomAugspurger
.transform works column by column, so change your indexers from x.iloc[0, :] to just x.iloc[0].
Comment From: jreback
This is the idiomatic way to transform by groups
In [18]: df.groupby('c').transform('first')/df[['a', 'b']]
Out[18]:
a b
0 1.000000 1.000000
1 -0.680665 -0.774614
2 1.000000 1.000000
3 -0.398770 0.821029
4 1.708528 14.396555
5 0.857692 -2.335223
6 20.181797 1.131629
7 -0.794080 -0.447658
8 3.881273 -1.540272
9 7.046538 -18.276593
````
**Comment From: elDan101**
@TomAugspurger
When I use transform the output is for both cases the same and corresponds to the (2) output (screenshot in issue opener). Actually, I am expecting an output like screenshot (1), because this is what is returned when I use inbuilt groupby-functions (like 'mean').
I was not aware of the transform function, there is also no documentation:
[http://pandas.pydata.org/pandas-docs/stable/generated/pandas.core.groupby.GroupBy.transform.html?highlight=transform#pandas.core.groupby.GroupBy.transform](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.core.groupby.GroupBy.transform.html?highlight=transform#pandas.core.groupby.GroupBy.transform)
**Comment From: TomAugspurger**
tranform is documented in the prose section: http://pandas.pydata.org/pandas-docs/stable/groupby.html#transformation, though we could add it to the API docs if desired.
Aggregations like `'mean'` set the index to the keys. If you're actual function is an aggregation, then use `.agg`, if you're doing a 1:1 transformation use `.transform`.
Closing for now, but ask if you have questions. Please include an actual copy-pastable example though (no screenshots). Hard to help out with your actual problem when I can't run the code.
**Comment From: elDan101**
Thank you. Actually, one question, I am still wondering why "0:" and ":" makes a difference.
Is there an intuition that helps me to see why this is different?
> transform is documented in the prose section: http://pandas.pydata.org/pandas-docs/stable/groupby.html#transformation, though we could add it to the API docs if desired.
Maybe a "see also: link" to the link you provided is enough. Thanks for this, I was new to grouping with pandas, will become handy again in future I suppose.
**Comment From: TomAugspurger**
> I am still wondering why "0:" and ":" makes a difference.
Is there an intuition that helps me to see why this is different?
I don't know off the top of my head. My guess is that it has to do with the inference `df.apply` does to try to guess the output shape, and the fact that `df.iloc[0:]` returns a different object that `df`:
```python
In [5]: df = pd.DataFrame(np.random.randn(10, 2), columns=['a', 'b'])
In [6]: df.iloc[:] is df
Out[6]: True
In [7]: df.iloc[0:] is df
Out[7]: False
Feel free to dig through the source code in pandas.core.groupby if you're interested :)
Comment From: jorisvandenbossche
It is true that the identity is not the same, but both are equal
In [53]: df.iloc[0:].equals(df.iloc[:])
Out[53]: True
so I think this can be considered a bug that it does not behave the same in groupby.apply
Comment From: jreback
equality is not enough
it has to be identical this is a view
the reason is we r testing for mutation and there is no good way
Comment From: jorisvandenbossche
equality is not enough, it has to be identical
But in the original issue, it was not about identity I think, as the identical/equal dataframe was only in the denominator: x.iloc[0, :] / x.iloc[:, :] vs x.iloc[0, :] / x.iloc[0:, :]