Code Sample, a copy-pastable example if possible
# Your code here
#%%
import pandas as pd
import numpy as np
#%%
_M = 10
_N = 1000
tuples = [(i,j) for i in range(_M) for j in range(_N)]
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
df = pd.DataFrame(np.random.rand(_N*_M,4),columns=['A','B','C','D'],index=index)
#%%
import itertools
for u,v in itertools.combinations(range(_M),2):
for w in range(_N):
someval1 = df.A.loc[u,w] - df.A.loc[v,w]
someval2 = df.B.loc[u,w] - df.B.loc[v,w]
Problem description
This is my first ever git post, and so please let me know if I can do anything else to make the issue more clear.
This is the gist of a script that I execute in Spyder. It is ugly and could be written to be made faster, but since the "for" loop (which is calling get_item) only took around 10 seconds to run, I didn't worry about cleaning it up. The 3x performance degradation between 0.19.2 to 0.20.2 (and a 30x degradation in 0.20.1) is very disconcerting since get_item is such a low level operation.
[this should explain why the current behaviour is a problem and why the expected output is a better solution.]
Expected Output
The code sample above took around 10 seconds to execute on pandas version 0.19.2. It took over 5 minutes to run in version 0.20.1 and around 30 seconds to run in version 0.20.2. The runtime difference between 0.19.2 and 0.20.2 is still a 3x degradation.
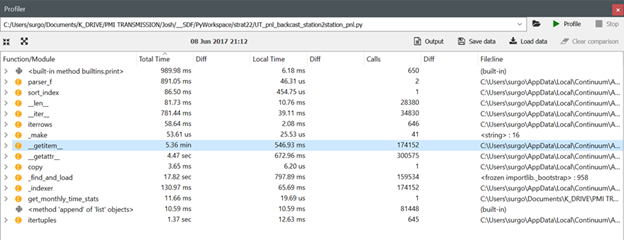
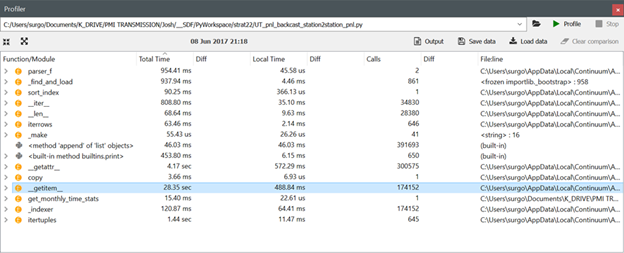
Note the profiler output for get_item using pandas versions 0.19.2, 0.20.1 and 0.20.2 respectively:
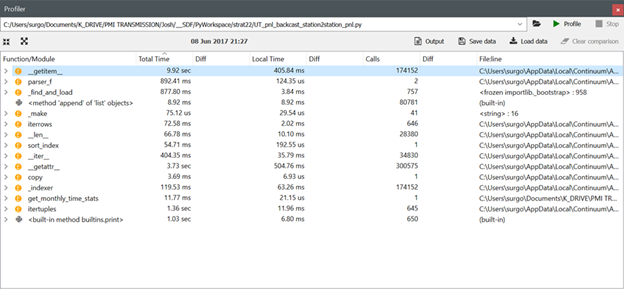
1 of 4 -- Output of pd.show_versions() -- VERSION 0.19.2
2 of 3 -- Output of pd.show_versions() -- VERSION 0.20.1
3 of 3-- Output of pd.show_versions() -- VERSION 0.20.2
Comment From: shoyer
Unfortunately it is very hard to debug such a large example -- a lot of different things could be doing wrong. Could please make a Minimal, Complete, and Verifiable example? Thanks
Comment From: jupiterjosh
Thanks for the link! I will post something shortly.
Comment From: jupiterjosh
Okay, I can replicate the 0.19.2 to 0.20.1 performance degradation with the following code, but the 0.20.2 performance is roughly the same as the 0.19.2 performance (i.e., the get_item issues appears to have been corrected in version 0.20.2 for my verifiable code example). I will look at what else is in my original code and revise the verifiable example tomorrow to try to replicate the 3x performance degradation I saw in my original script. I have also included images for the new code from the Spyder profiler after running Pandas versions 0.19.2, 0.20.1 and 0.20.2 respectively.
#%%
import pandas as pd
import numpy as np
#%%
_M = 10
_N = 1000
tuples = [(i,j) for i in range(_M) for j in range(_N)]
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
df = pd.DataFrame(np.random.rand(_N*_M,4),columns=['A','B','C','D'],index=index)
#%%
import itertools
for u,v in itertools.combinations(range(_M),2):
for w in range(_N):
someval1 = df.A.loc[u,w] - df.A.loc[v,w]
someval2 = df.B.loc[u,w] - df.B.loc[v,w]
``
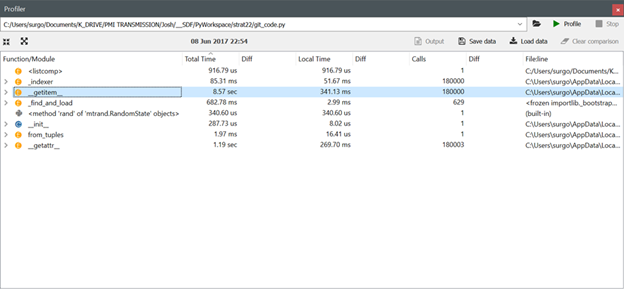
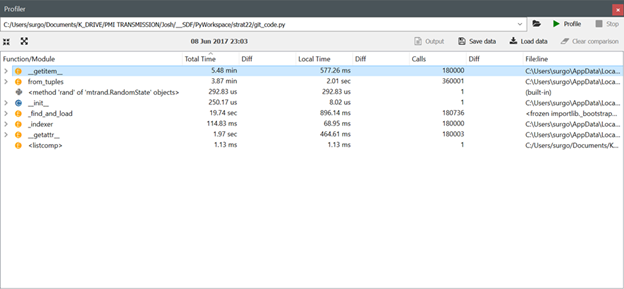
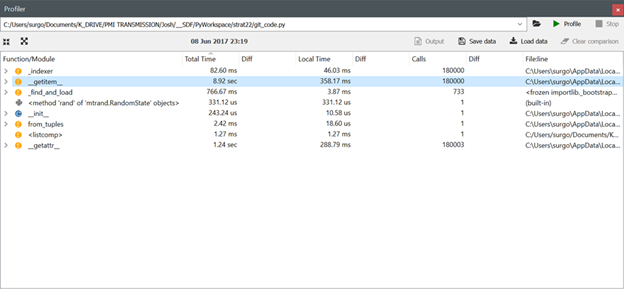
Comment From: jorisvandenbossche
@jupiterjosh The related issue with the MultiIndex indexing performance regression: https://github.com/pandas-dev/pandas/issues/16319 (and PRs https://github.com/pandas-dev/pandas/pull/16324 and https://github.com/pandas-dev/pandas/pull/16346)
Comment From: jorisvandenbossche
If you can get the remaining slowdown between 0.19.2 and 0.20.2 in a smaller reproducible example, that would be nice!
Comment From: jupiterjosh
@jorisvandenbossche Thanks. I will track down the remaining slowdown.
@jreback I would have preferred if this was closed with some sort of comment since I did observe a slowdown between 0.19.2 and 0.20.2. I will repost when I have figured out where the remaining slowdown is occurring and I can create a better verifiable example. It is somewhere buried in get_loc, but I can't tease out where as of yet. Btw, I don't know if this helps for your performance benchmarking, but as a performance use-case I routinely pull in dataframes with north of 1 million records.
Comment From: jupiterjosh
@jorisvandenbossche
The remaining slowdown is due to whether get_loc from pandas_libs.index.MultiIndexObjectEngine is preferred by the dataframe (this method returns quickly) or whether get_loc from pandas_libs.index.MultiIndexHashEngine is used (much much slower). The MultIndexHashEngine uses a function called "_combine_hash_arrays" which appears to be the code causing the slowdown.
I am not familiar with the pandas codebase enough to alter the code below to trigger MultiIndexHashEngine to be preferred over MultiIndexObjectEngine. Any ideas? I tried mixing the types on my index, but that didn't trigger MultIndexHashEngine, and yet the script that I run in my original code causes this to be used. I also tried loading from a file (my original script calls read_csv) thinking that might change the type of index engine, but that also did not work.
`
%%
import pandas as pd import numpy as np
%%
_M = 10 _N = 1000 tuples = [(i,j) for i in range(_M) for j in range(_N)] index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second']) df = pd.DataFrame(np.random.rand(_N*_M,4),columns=['A','B','C','D'],index=index)
%%
import itertools for u,v in itertools.combinations(range(_M),2): for w in range(_N): someval1 = df.A.loc[u,w] - df.A.loc[v,w] someval2 = df.B.loc[u,w] - df.B.loc[v,w]`
Comment From: jreback
@jupiterjosh I am happy to keep around an issue that demonstrates a clear example of a performance regression, meaning it is a minimal reproducible example. pls format the code and show timing differences with a version on each.
further you in fact stated this
Okay, I can replicate the 0.19.2 to 0.20.1 performance degradation with the following code, but the 0.20.2 performance is roughly the same as the 0.19.2 performance (i.e., the get_item issues appears to have been corrected in version 0.20.2 for my verifiable code example). I will look at what else is in
Comment From: jupiterjosh
@jreback -- perhaps you could comment on this:
I am not familiar with the pandas codebase enough to alter the code below to trigger MultiIndexHashEngine to be preferred over MultiIndexObjectEngine. Any ideas? I tried mixing the types on my index, but that didn't trigger MultIndexHashEngine, and yet the script that I run in my original code causes this to be used. I also tried loading from a file (my original script calls read_csv) thinking that might change the type of index engine, but that also did not work. `
Pandas is doing some sort of type inferencing to determine when the MultiIndexHashEngine is used over the MultiIndexObjectEngine. If you could give me a pointer on how to set up a multiindex that triggers the use of the MultiIndexHashEngine then I will post code and profiler results.
Comment From: jorisvandenbossche
Yes, there are indeed two mechanisms to index MultiIndexes, and which is used depends on the size of the index: https://github.com/pandas-dev/pandas/blob/1564a6e0e9fa3a640f5c1999c4fb118b8e5a4411/pandas/core/indexes/multi.py#L635-L646
So the current cut-off is a size of 10000. Each of both has advantages and disadvantages (speeds of creation and less memory usage vs speed of indexing). You can see in https://github.com/pandas-dev/pandas/pull/16324 some discussion about this and some plots showing the tradeoff in speed.
Note that a "minimal reproducible example" does not need to use a small dataframe. I mean you can create with minimal code a large frame, and so trigger the use the hash-based engine.
Comment From: jupiterjosh
@jorisvandenbossche
If you can get the remaining slowdown between 0.19.2 and 0.20.2 in a smaller reproducible example, that would be nice!
@jreback
@jupiterjosh I am happy to keep around an issue that demonstrates a clear example of a performance regression...
I can demonstrate the 3x slowdown in the code below. There are two files attached to this comment with my timeit results (I used IPython's "timeit" magic command). I don't know if one needs to reopen the issue or start a new one. After playing with the indexing for awhile, I could see that the memory management in the new version is really good, I just think the cutoff for triggering it may be too low given the 3x performance penalty (assuming that can't be fixed).
The attached timeit results show a roughly 40us execution time on my machine for up to 100,000,000 indices using version 0.19.2 and roughly 120us on my machine for indices greater than 10k and up to 10MM indices using 0.20.2.
As I said before, the memory management in the new version is very good, but the 10k cutoff feels low. Multiindices by their very nature get large (i.e, curse of dimensionality), and 10,000 indices corresponds to a really small 100 by 100 multiindex. The difference in memory footprint for 10,000,000 indices was roughly 500Mb between the two versions. I personally would consider anything under 1GB a small price to pay for some additional breathing room and a 66% reduction in execution time.
Also, this is just fyi, but I don't know if the memory performance is working exactly how you want it to. I have a decent amount of RAM on my box and I was able to see both engines in action on a large dataset. In version 0.19.2, the dataframe with 100MM indices ate up around 24GB of ram and didn't let it go. The new version peaked at 18GB before settling down to 11GB. At first I thought it was a garbage collection issue because the code is building dataframes in a loop and so I cleaned out everything, ran just the 10BB scenario and got the same result. So I'm wondering if the idea is to make the memory footprint smaller, is the initial ballooning in the engine a problem? It certainly would be for the 1BB case if you had 16GB of ram, since you'd be paging the hdd (and hanging the box) as the footprint approaches 18GB before settling down to 11GB.
#%%
import pandas as pd
import numpy as np
#%%
# Construct a dummy dataframe with a 2d multindex of size m-by-n
def dummy_df(m,n):
_M = m
_N = n
tuples = [(i,j) for i in range(_M) for j in range(_N)]
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
df = pd.DataFrame(np.random.rand(_N*_M,4),columns=['A','B','C','D'],index=index)
return df
#%%
# Test data accessing
n = 1000
for m in [5,9,20,100,500,1000,10000,100000]:
df = dummy_df(m,n)
print(str(m*n) + ' indices =>')
# Time a random value with IPython's timeit magic command
%timeit df.A.loc[3,25]
See attached files for timeit results (I decided to inline them after the initial post):
Using Pandas version 0.19.2
5000 indices => The slowest run took 76.93 times longer than the fastest. This could mean that an intermediate result is being cached. 10000 loops, best of 3: 32.9 µs per loop 9000 indices => The slowest run took 61.72 times longer than the fastest. This could mean that an intermediate result is being cached. 10000 loops, best of 3: 33.5 µs per loop 20000 indices => The slowest run took 95.47 times longer than the fastest. This could mean that an intermediate result is being cached. 10000 loops, best of 3: 34.3 µs per loop 100000 indices => The slowest run took 681.66 times longer than the fastest. This could mean that an intermediate result is being cached. 10000 loops, best of 3: 34 µs per loop 500000 indices => The slowest run took 5370.16 times longer than the fastest. This could mean that an intermediate result is being cached. 1 loop, best of 3: 39.4 µs per loop 1000000 indices => The slowest run took 6176.82 times longer than the fastest. This could mean that an intermediate result is being cached. 1 loop, best of 3: 41.2 µs per loop 10000000 indices => The slowest run took 69808.91 times longer than the fastest. This could mean that an intermediate result is being cached. 1 loop, best of 3: 41.2 µs per loop 100000000 indices => The slowest run took 656410.45 times longer than the fastest. This could mean that an intermediate result is being cached. 1 loop, best of 3: 43.4 µs per loop
Using Pandas 0.20.2:
5000 indices => The slowest run took 68.16 times longer than the fastest. This could mean that an intermediate result is being cached. 10000 loops, best of 3: 35.5 µs per loop 9000 indices => The slowest run took 67.65 times longer than the fastest. This could mean that an intermediate result is being cached. 10000 loops, best of 3: 37.3 µs per loop 20000 indices => The slowest run took 17.95 times longer than the fastest. This could mean that an intermediate result is being cached. 10000 loops, best of 3: 132 µs per loop 100000 indices => The slowest run took 68.23 times longer than the fastest. This could mean that an intermediate result is being cached. 10000 loops, best of 3: 130 µs per loop 500000 indices => The slowest run took 520.37 times longer than the fastest. This could mean that an intermediate result is being cached. 10000 loops, best of 3: 126 µs per loop 1000000 indices => The slowest run took 1032.61 times longer than the fastest. This could mean that an intermediate result is being cached. 10000 loops, best of 3: 129 µs per loop 10000000 indices => The slowest run took 8144.94 times longer than the fastest. This could mean that an intermediate result is being cached. 1 loop, best of 3: 145 µs per loop 100000000 indices => The slowest run took 121455.49 times longer than the fastest. This could mean that an intermediate result is being cached. 1 loop, best of 3: 164 µs per loop
Comment From: jreback
@jupiterjosh the cutoff is 100k elements ATM. I suppose going to 1M wouldn't hurt. But you would have to show conclusive gains like this: https://github.com/pandas-dev/pandas/pull/16346#issuecomment-301929604. You can add an asv for 1M I suppose. @jorisvandenbossche also had a nice graph of this. Which if we can add memory usage would be nice.
If you are actually querying 1M times itself then you are doing things in an inefficient manner as well. You can easily use list / boolean indexing.
Comment From: jupiterjosh
Thanks @jreback. I will look at adding an asv.
Is the 100k cutoff in the 0.20.2 release or a dev build? I hit it at 10k elements in 0.20.2.
You're right btw, I will change my indexing strategy. I don't know the pandas code-base, but I was more concerned with the indexing slowdown potentially impacting other pandas functions (joins or groupbys maybe?) since indexing seems to be something that you'd want to be as fast (and atomic) as possible.
Comment From: jreback
more concerned with the indexing slowdown potentially impacting other pandas functions (joins or groupbys maybe?) since indexing seems to be something that you'd want to be as fast (and atomic)
groupbys and joins are running vectorized code. indexing is by definition initiated by the user. you should not be doing repeated single indexing.
Comment From: jorisvandenbossche
Cutoff is currently indeed only 10k as @jupiterjosh finds (code)
Figure for timings is here: https://github.com/pandas-dev/pandas/blob/1564a6e0e9fa3a640f5c1999c4fb118b8e5a4411/pandas/core/indexes/multi.py#L635-L646
I am certainly in favor of increasing the cutoff to at least 100k.
At the time, I tried to make similar plots for memory, but this was a bit more complicated and didn't get consistent results.