No code, just a question for proper behavior for rowspan/colspan with read_html of an HTML table into a DataFrame. (I'm not asking what currently happens with read_html now. I'm asking what should happen.)
Below is a simple HTML table that uses both colspan (a,e,i,o,u) and rowspan (Fruit, schwa, honk, and the rightmost 0 in the table). It renders identically on each of {Chrome, Firefox, Safari}. With these renderers, both rowspans and colspans are basically rendered midway through the span, either vertically (rowspan) or horizontally (colspan).
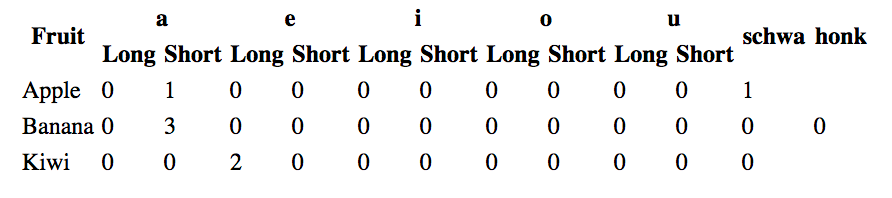
Now, let's say we wanted to import this into pandas with read_html. It seems to me the behavior should be different for a pandas DataFrame than for a renderer:
- The header should have a MultiIndex, where the first column is Fruit and the second column is a combination of a and Long, etc. We don't "fill" a rowspan (the first column shouldn't be two Fruits), but we do "fill" a colspan (a would appear in the 2nd and 3rd columns).
- The body should "fill" a rowspan or colspan with the provided values. So the rightmost column, instead of having one zero and two blanks on the three rows, should have a zero for each of the three rows. One would think a span in a DataFrame context within a body would mean "fill in the value for each cell in the span".
If this was the case, it would imply that we treat rowspans differently in header and body.
- If we "fill" a rowspan in a header, then we just repeat the header value in the MultiIndex output, which doesn't seem like what we want.
- If we don't "fill" a rowspan in the body, we leave some cells in the DataFrame blank, which also seems misguided.
I put the DataFrame that I think we want below. It incorporates different behavior for rowspan for header and body. One thing I don't know, though: If I don't "fill" the rowspan name for rowspan > 1, what do I put instead? None? empty string? False? What does the input to TextParser look like when some column names are "taller" than others?
Thoughts? @chris-b1? (relevant to https://github.com/pandas-dev/pandas/issues/17054)
a e i o u
Fruit Long Short Long Short Long Short Long Short Long Short schwa honk
0 Apple 0 1 0 0 0 0 0 0 0 0 1 0
1 Banana 0 3 0 0 0 0 0 0 0 0 0 0
2 Kiwi 0 0 2 0 0 0 0 0 0 0 0 0
<table>
<thead>
<tr>
<th rowspan=2>Fruit</th>
<th colspan=2>a</th>
<th colspan=2>e</th>
<th colspan=2>i</th>
<th colspan=2>o</th>
<th colspan=2>u</th>
<th rowspan=2>schwa</th>
<th rowspan=2>honk</th>
</tr>
<tr>
<th>Long</th>
<th>Short</th>
<th>Long</th>
<th>Short</th>
<th>Long</th>
<th>Short</th>
<th>Long</th>
<th>Short</th>
<th>Long</th>
<th>Short</th>
</tr>
</thead>
<tbody>
<tr>
<td>Apple</td>
<td>0</td>
<td>1</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>1</td>
<td rowspan=3>0</td>
</tr>
<tr>
<td>Banana</td>
<td>0</td>
<td>3</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
</tr>
<tr>
<td>Kiwi</td>
<td>0</td>
<td>0</td>
<td>2</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
</tr>
</tbody>
</table>
Comment From: chris-b1
I think the philosophy with read_html is that it is a "good enough for a first pass" parser, not necessarily that it will handle every messy real life table.
That said the behavior you proposed seems reasonable - in other parsers "Fruit" would be placed at the top level, with an unnamed second level TextParser logic should already handle this for you.
In [18]: pd.read_csv(StringIO("""
...: Fruit,a,a,e,e
...: ,Long,Short,Long,Short
...: Apple,0,1,0
...: Banana,0,3,0"""), header=[0,1])
Out[18]:
Fruit a e
Unnamed: 0_level_1 Long Short Long Short
0 Apple 0 1 0 NaN
1 Banana 0 3 0 NaN
Comment From: jowens
OK. I can match the behavior of the other parsers. "Unnamed second level" evidently means "empty string".
Comment From: gfyoung
Judging from the previous conversation, I am changing the labeling. PR is welcome!
Comment From: jowens
If you'd like, @gfyoung, just close this in favor of https://github.com/pandas-dev/pandas/issues/17054.
Comment From: gfyoung
If you'd like, @gfyoung, just close this in favor of #17054.
@jowens : Are you planning to address this discussion in that issue then?
Comment From: jowens
It'll be implemented as discussed in this issue when I submit a pull request for https://github.com/pandas-dev/pandas/issues/17054.
Comment From: gfyoung
Okay, sounds good. Closing in favor of that issue then.