Code Sample, a copy-pastable example if possible
import gc
import numpy as np
import pandas as pd
from memory_profiler import profile
@profile
def leaky_af():
channels = ['Sonya Blade', 'Johnny Cage', 'Raiden', 'Scorpion', 'Kano']
data_df = pd.DataFrame() # w/ default index
for channel in channels:
data = pd.Series(data=np.random.random(50000),
index=pd.DatetimeIndex(np.arange(0, 50000)))
data_df[channel] = data
return
@profile
def tight():
channels = ['Sonya Blade', 'Johny Cage', 'Raiden', 'Scorpion', 'Kano']
data_df = pd.DataFrame(index=pd.DatetimeIndex([])) # w/ DatetimeIndex
for channel in channels:
data = pd.Series(data=np.random.random(50000),
index=pd.DatetimeIndex(np.arange(0, 50000)))
data_df[channel] = data
return
def main():
"""
leaky_af or tight is ran in a loop. The functions are self-contained, accepts nothing,
returns nothing. Yet, memory usage increases (if leaky_af is used) proportional to the
length of the loop.
"""
for i in range(50):
leaky_af() # replace with tight(), and memory usage stabilizes
gc.collect()
if __name__ == '__main__':
main()
Problem description
Memory seems to leak when adding new Series with DatetimeIndex columns to an empty DataFrame (which was initialized with default index). The DataFrame is created in a self-contained functions which accepts nothing and returns nothing. So all objects inside that function have no references outside its scope and should be released from memory. Still, memory usage increases steadily when the functions is called repeatedly in a loop.
However, if the DataFrame is initialized with an empty DatetimeIndex index, the leakage stops.
Note, I'm aware that leaky_af may trigger some copying when appending series with different index type, and that's fine. However, that copy should also be destroyed when leaky_af() ends (and returns nothing).
main() called with tight()
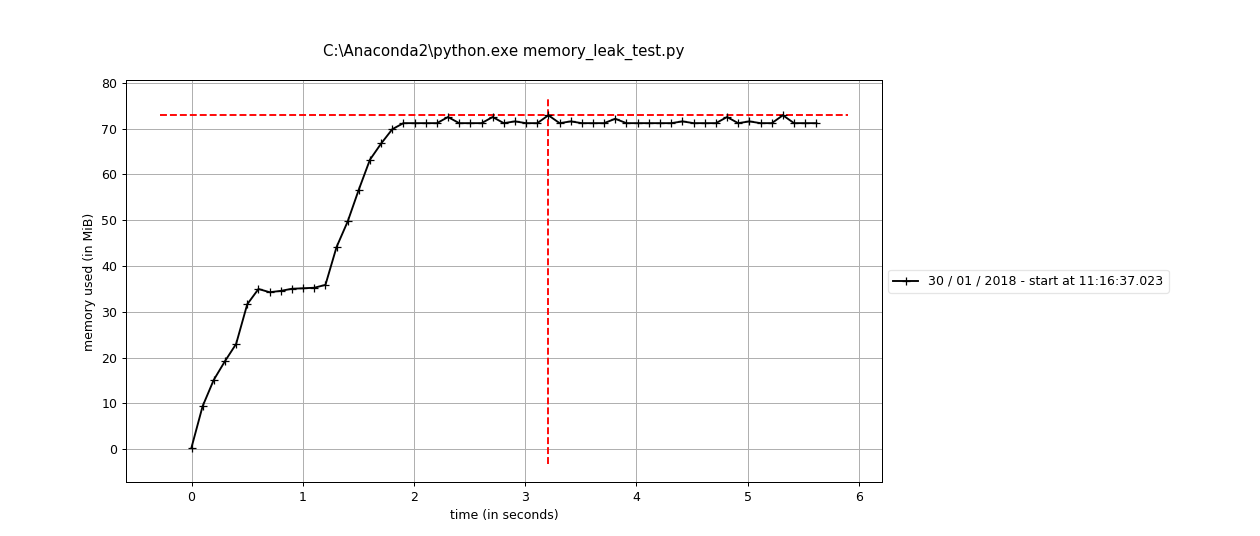
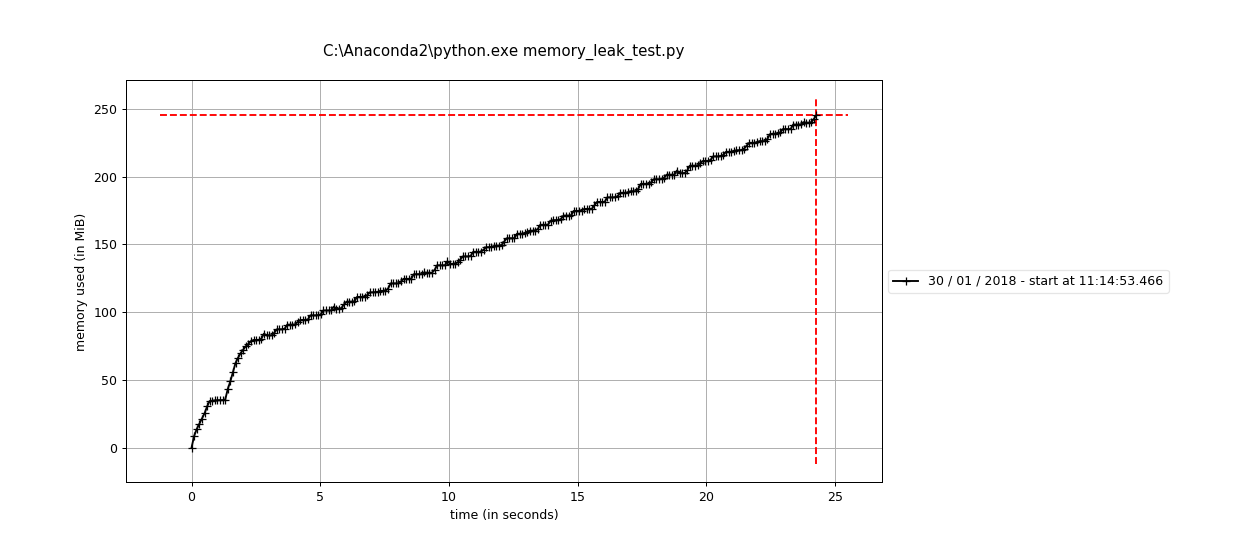
main() called with leaky_af()
Expected Output
Output of pd.show_versions()
pandas 0.22.0 python 2.7.14 (not tested in python 3)
Comment From: jreback
these don't leak. the 'leaky_af' continually creates and destroys objects. When a new column is added to the frame, the original index is reindexed, which causes a copy, while in the first one it is simply set with the added index. Since python doesn't release the actual memory, your usage grows.
subsequent indices are equal to the first so no reindexing happens.
xref https://github.com/pandas-dev/pandas/issues/6046
Comment From: ali-cetin-4ss
@jreback maybe I'm missing something here but, note that the leaky_af function is ran in a loop inside the main function; for every increment in the loop, leaky_af is ran only once (which may trigger copying, and that's fine). However, when data_df is re-created in the next increment, all references to the old one are gone, so Python should release them from the memory. Instead, you see a steady increase in memory usage.
The two plots show main ran with tight() and leaky_af(). The only difference between them is the initial empty dataframe.
Comment From: ali-cetin-4ss
@jreback I don't want to be a nuisance, but I urge you to take a second look at this case. I have altered the sample code and description to clarify the issue. Furthermore, the i did exactly what you suggest in xref #6046, and ran the code inside a loop. The memory used increases steadily for every increment.
Again, thank you for your time and effort! Love Pandas, and just want to contribute. Cheers :)
Comment From: TomAugspurger
@ace-e4s can you try on Py3? Here's my plot w/ your leaky version.
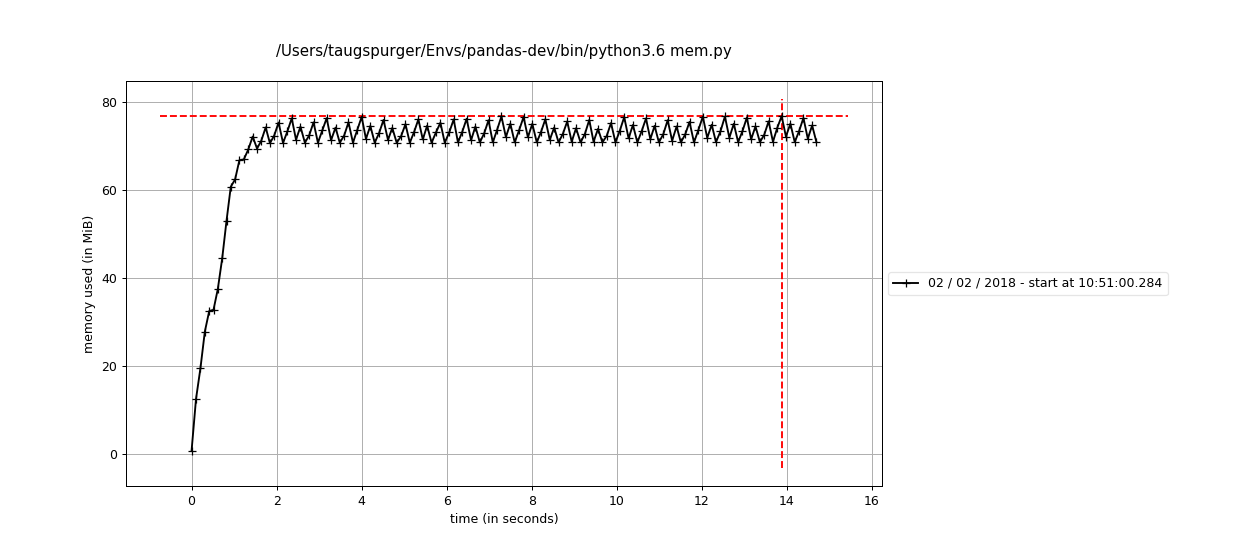
Comment From: jorisvandenbossche
I did that as well a few days ago and got a similar plot as @TomAugspurger (forgot to comment about it).
But that said, there is something strange in those plots about the timings. I don't see why the 'leaky_af' version would be so much slower.
Comment From: jorisvandenbossche
OK, apparently adding a column to empty frame with already the correct type of index is much faster:
In [54]: %%timeit
...: data_df = pd.DataFrame(index=pd.DatetimeIndex([]))
...: data_df['channel'] = data
...:
1.93 ms ± 122 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
In [55]: %%timeit
...: data_df = pd.DataFrame()
...: data_df['channel'] = data
...:
110 ms ± 1.9 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
and since you repeat that many times in the memory profiler, that's a reason for the one taking a lot more time (I find it still strange that it is such a big difference though)
Comment From: jorisvandenbossche
@jreback: When a new column is added to the frame, the original index is reindexed, which causes a copy
That doesn't seem to be the case though (at least not on python 3):
In [65]: data = pd.Series(data=np.random.random(50000), index=pd.DatetimeIndex(np.arange(0, 50000)))
In [66]: data_df = pd.DataFrame()
In [67]: data_df['channel'] = data
In [68]: data.index.base is data_df.index.base
Out[68]: True
In [71]: data.index.base[0] = 5
In [72]: data_df.index[:5]
Out[72]:
DatetimeIndex(['1970-01-01 00:00:00.000000005',
'1970-01-01 00:00:00.000000001',
'1970-01-01 00:00:00.000000002',
'1970-01-01 00:00:00.000000003',
'1970-01-01 00:00:00.000000004'],
dtype='datetime64[ns]', freq=None)
@ace-e4s can you try to run the same in python 2 to see if you see any difference?
Comment From: ali-cetin-4ss
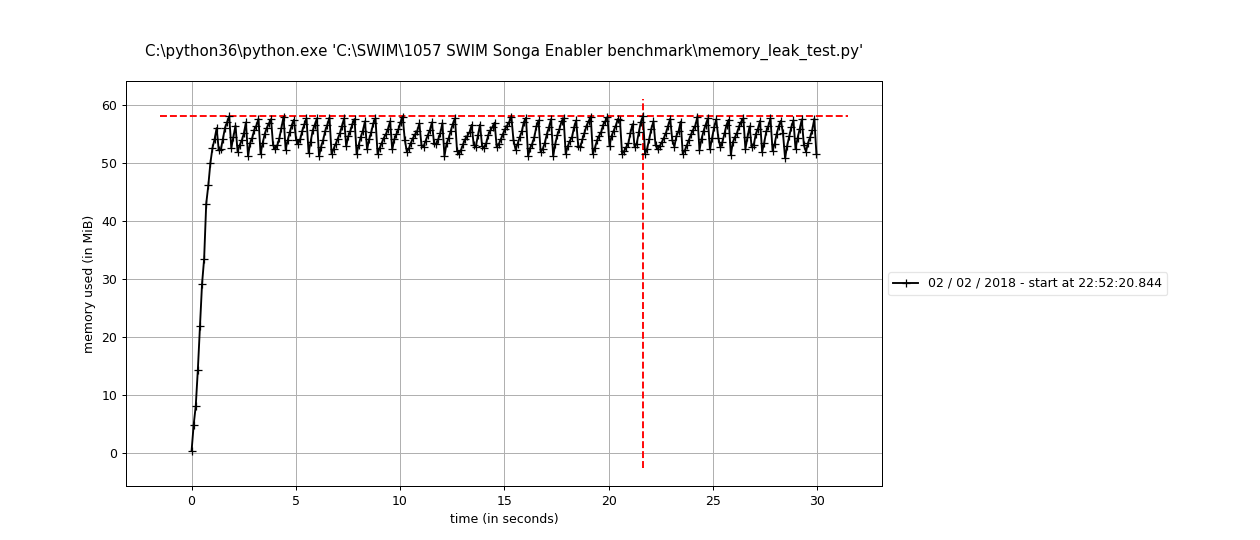
@TomAugspurger I tried to run it with Python 3.6 and got similar results as you; memory usage is comparable between leaky_af and tight, but tight runs much faster.
May this be a case of circular referencing somewhere, and Python 2 garbage collector is failing to collect? (If I'm not wrong, Python 3.4 improved significantly in that respect.)
Python 3.6 leaky_af()
Comment From: TomAugspurger
That seems most likely.
Since it's python 2 only, I suspect we would gladly take a patch fixing the behavior you're seeing, but I personally don't have any plans to look into it :)
On Fri, Feb 2, 2018 at 10:01 PM, ace-e4s notifications@github.com wrote:
@TomAugspurger https://github.com/tomaugspurger I tried to run it with Python 3.6 and got similar results as you; memory usage is comparable between leaky_af and tight, but tight runs much faster.
May this be a case of circular referencing somewhere, and Python 2 garbage collector is failing to collect? (If I'm not wrong, Python 3.4 improved significantly in that respect.) Python 3.6 leaky_af()
[image: pandas leaky_af - py36] https://user-images.githubusercontent.com/18338679/35756803-ebec0c4e-086c-11e8-918f-63d9c8c7e930.png
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/pandas-dev/pandas/issues/19459#issuecomment-362720381, or mute the thread https://github.com/notifications/unsubscribe-auth/ABQHIuFGVQ3rUqvB20csaD21rJ5IjaZZks5tQ4W0gaJpZM4RyGGZ .
{kind=link}
Comment From: ali-cetin-4ss
@jorisvandenbossche , yes same behavior in python 2.
Comment From: ali-cetin-4ss
Although the memory issue may be limited to Python 2, the poor performance may be a symptom of the same underlying issue.
Comment From: jorisvandenbossche
Likewise as @TomAugspurger but regarding the poor performance which also affects python 3: we gladly take a patch to solve it, but it isn't the most pressing issue as this usage pattern is not a typical way to do things if you care about performance.