Pandas version checks
-
[x] I have checked that this issue has not already been reported.
-
[x] I have confirmed this bug exists on the latest version of pandas.
-
[x] I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
import pandas as pd
df = pd.DataFrame({"key": range(100000), "val": "test"})
%timeit df.groupby(["key"]).first();
pa_df = df.convert_dtypes(dtype_backend="pyarrow")
%timeit pa_df.groupby(["key"]).first();
pa_df = pa_df.astype({"val": pd.StringDtype("pyarrow")})
%timeit pa_df.groupby(["key"]).first();
Issue Description
Grouping by and then aggregating on a dataframe that contains ArrowDtype(pyarrow.string()) columns is orders of magnitude slower than performing the same operations on an equivalent dataframe whose corresponding string column is of any other acceptable string type (e.g. string, StringDtype("python"), StringDtype("pyarrow")). This is surprising in particular because StringDtype("pyarrow") does not exhibit the same problem.
Note that in the bug reproduction example, DataFrame.convert_dtypes with dtype_backend="pyarrow" converts string columns to ArrowDtype(pyarrow.string()) rather than StringDtype("pyarrow").
Finally, here's a sample run, with dtypes printed out for clarity; I've reproduced this on both OS X and OpenSuse Tumbleweed for the listed pandas and pyarrow versions (as well as current main):
In [7]: import pandas as pd
In [8]: df = pd.DataFrame({"key": range(100000), "val": "test"})
In [9]: df["val"].dtype
Out[9]: dtype('O')
In [10]: %timeit df.groupby(["key"]).first();
8.37 ms ± 599 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
In [11]: pa_df = df.convert_dtypes(dtype_backend="pyarrow")
In [13]: type(pa_df["val"].dtype)
Out[13]: pandas.core.dtypes.dtypes.ArrowDtype
In [14]: %timeit pa_df.groupby(["key"]).first();
2.39 s ± 142 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [15]: pa_df = pa_df.astype({"val": pd.StringDtype("pyarrow")})
...:
In [16]: type(pa_df["val"].dtype)
Out[16]: pandas.core.arrays.string_.StringDtype
In [17]: %timeit pa_df.groupby(["key"]).first();
12.9 ms ± 306 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Expected Behavior
Aggregation performance on ArrowDtype(pyarrow.string()) columns should be comparable to aggregation performance on StringDtype("pyarrow"), string typed columns.
Installed Versions
Comment From: rhshadrach
Thanks for the report!
Aggregation performance on
ArrowDtype(pyarrow.string())columns should be comparable to aggregation performance onStringDtype("pyarrow"),stringtyped columns.
I don't think this expectation is correct. ArrowExtensionArray (corresponding to ArrowDtype) is essentially a wrapper around general PyArrow data, whereas ArrowStringArray (corresponding to StringDtype) is a data container specially crafted to support PyArrow strings. I do not believe we aim for neither feature nor performance parity between the two. Users should prefer StringDtype.
@jorisvandenbossche @WillAyd - should
df.convert_dtypes(dtype_backend="pyarrow")
be converting to StringDtype here?
Comment From: WillAyd
Hmm I don't think so - the StringDtype is associated with the "numpy_nullable" backend. The pyarrow backend has always provided back the ArrowExtensionArray wrapper types.
Do we know where the bottleneck is performance-wise? I agree with the OP that the performance should be equivalent between the two types, if not slightly faster for the ArrowExtensionArray
Comment From: rhshadrach
Hmm I don't think so - the
StringDtypeis associated with the "numpy_nullable" backend.
https://github.com/pandas-dev/pandas/blob/70edaa0b4661df6f251f2e3d3ae5c55ef371fc74/pandas/core/arrays/string_arrow.py#L128
Comment From: snitish
@WillAyd looks like the bottleneck is due to ArrowExtensionArray._groupby_op not properly handling the string[pyarrow] dtype. We have special handling for StringDtype but for string[pyarrow], it hits to_masked() which again does not handle this dtype. This causes the groupby operation to be performed in pure python causing the slowness.
Comment From: WillAyd
Thanks for that insight @snitish . Yea anything we can do to remove the layers of indirection and particularly Arrow <> NumPy copies would be very beneficial
Comment From: WillAyd
FWIW I realize the OP is talking about strings, but this likely applies to the wrapped Arrow types in general. You can see the same performance issues using another Arrow type like decimal:
In [108]: df = pd.DataFrame({
...: "key": pd.Series(range(100_000), dtype=pd.ArrowDtype(pa.int64())),
...: "val": pd.Series(["3.14"] * 100_000, dtype=pd.ArrowDtype(pa.decimal128(10, 4)))
...: })
In [109]: %timeit df.groupby("key").sum()
2.83 s ± 131 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [110]: %timeit pa.TableGroupBy(pa.Table.from_pandas(df), "key").aggregate([("val", "sum")])
8.18 ms ± 589 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Comment From: snitish
@WillAyd also noticed that .astype("string[pyarrow]") converts the dtype to StringDtype and the aggregation is much faster, while .convert_dtypes(dtype_backend="pyarrow") does not. Both dtypes show as "string["pyarrow"], but only one is a StringDtype. Is this expected?
In [2]: df = pd.DataFrame({"key": range(100000), "val": "test"}).astype({"val": "string[pyarrow]"})
In [3]: df["val"].dtype
Out[3]: string[pyarrow]
In [4]: isinstance(df["val"].dtype, pd.StringDtype)
Out[4]: True
In [6]: %timeit df.groupby("key").first()
16.5 ms ± 234 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
In [7]: pa_df = df.convert_dtypes(dtype_backend="pyarrow")
In [8]: pa_df["val"].dtype
Out[8]: string[pyarrow]
In [9]: isinstance(pa_df["val"].dtype, pd.StringDtype)
Out[9]: False
In [10]: %timeit pa_df.groupby("key").first()
4.73 s ± 44.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Comment From: kzvezdarov
I meant to open a separate issue about convert_dtypes but got carried away and forgot to, sorry about that. At least per the pandas.DataFrame.convert_dtypes doc, it seems that when convert_string is set to True, string objects should be converted to StringDtype, but in practice they appear to get converted to the wrapper type ArrowDtype(pyarrow.string()) instead. In both case the dtype's name property resolves to string[pyarrow].
In [3]: df = pd.DataFrame({"val": ["test"]}).convert_dtypes(dtype_backend="pyarrow")
In [4]: type(df.dtypes["val"])
Out[4]: pandas.core.dtypes.dtypes.ArrowDtype
Comment From: jorisvandenbossche
Both dtypes show as
"string["pyarrow"], but only one is aStringDtype. Is this expected?
Yes, that is expected (although very annoying they have the same repr ..). See also https://pandas.pydata.org/pdeps/0014-string-dtype.html for context. The StringDtype variant will become the default in 3.0.
Comment From: jorisvandenbossche
At least per the
pandas.DataFrame.convert_dtypesdoc, it seems that whenconvert_stringis set toTrue, string objects should be converted toStringDtype, but in practice they appear to get converted to the wrapper typeArrowDtype(pyarrow.string())instead.
This is of course not a simple case with one obvious correct answer, but, in general the idea is that convert_dtypes() is meant to give you the nullable dtypes, and when additionally passing dtype_backend="pyarrow", you are asking to get ArrowDtype dtypes (that is also what the docstring says).
Of course, if we are going to get more of the non-ArrowDtype nullable dtypes getting backed by pyarrow (like StringDtype now), this division gets a bit tricky (and another reason to move forward with https://github.com/pandas-dev/pandas/pull/58455).
Now, I assume one issue here is that the default StringDtype right now uses the "python" string storage, and not pyarrow. So that might be a reason you are asking for dtype_backend="pyarrow". Now, on the dev version we already have switched the default storage of StringDtype to pyarrow, and so starting with pandas 3.0 if you want nullable dtypes through convert_dtypes and want to use pyarrow just for the strings, you won't need to specify dtype_backend="pyarrow".
Comment From: kzvezdarov
Makes sense, thanks for clarifying. I'd just misinterpreted the relation between convert_string=True and dtype_backend="pyarrow" to imply converting to the nullable extension type, set to the pyarrow backend.
Comment From: kzvezdarov
FWIW I realize the OP is talking about strings, but this likely applies to the wrapped Arrow types in general. You can see the same performance issues using another Arrow type like decimal:
In [108]: df = pd.DataFrame({ ...: "key": pd.Series(range(100_000), dtype=pd.ArrowDtype(pa.int64())), ...: "val": pd.Series(["3.14"] * 100_000, dtype=pd.ArrowDtype(pa.decimal128(10, 4))) ...: }) In [109]: %timeit df.groupby("key").sum() 2.83 s ± 131 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) In [110]: %timeit pa.TableGroupBy(pa.Table.from_pandas(df), "key").aggregate([("val", "sum")]) 8.18 ms ± 589 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
It seems to only happen for the decimal and string ArrowDtype, the rest that I've tested with - float64, int64, boolean, timestamp - all seem to be only marginally slower. CProfile shows that for both ArrowDtype(pa.string()) and ArrowDtype(pa.decimal128(10, 4)) aggregation falls through to _agg_py_fallback:

whereas for other types it continues on to _cython_operation:
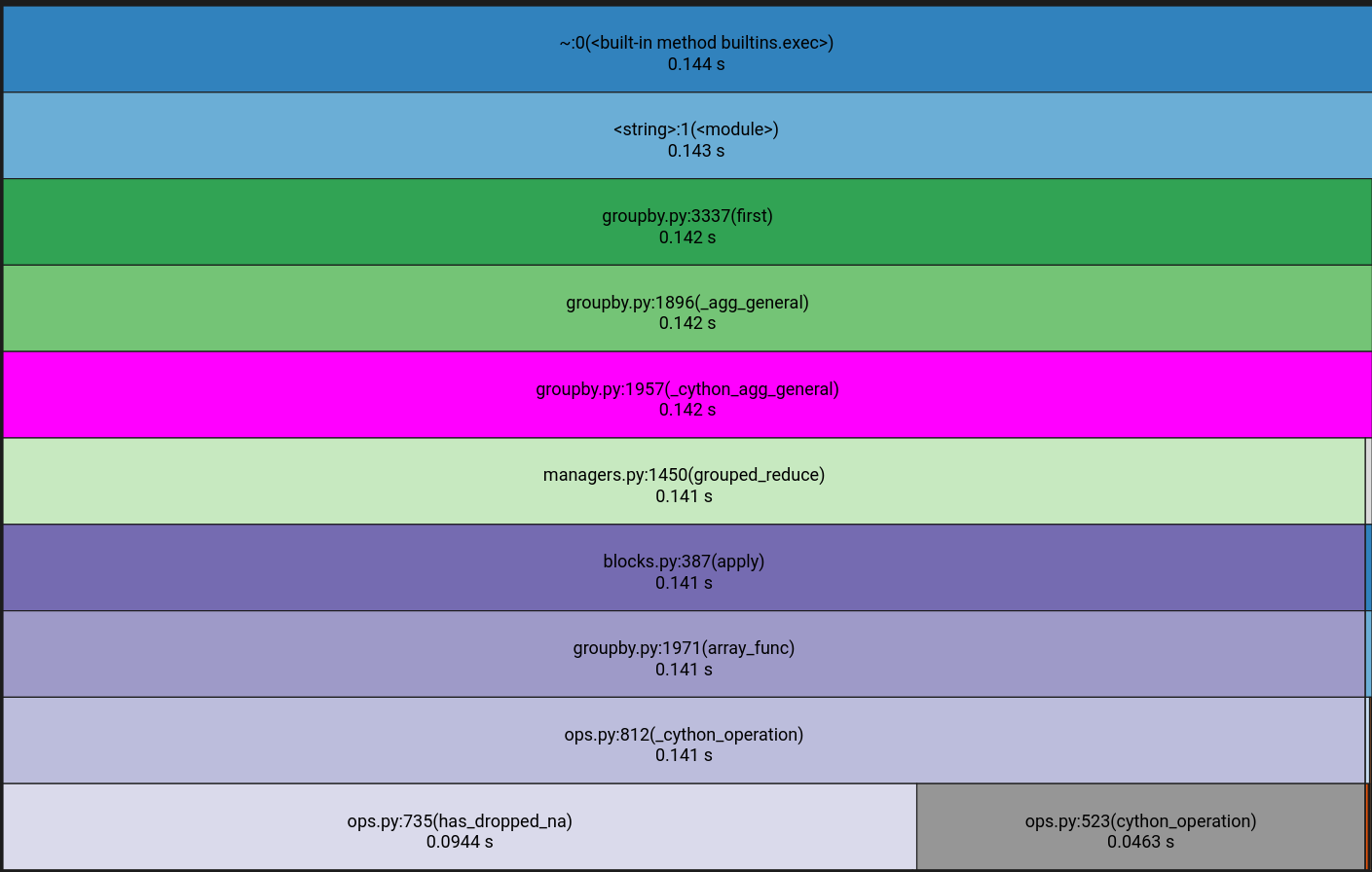
Making the ArrowDtype(pyarrow.string()) follow the handling of StringDtype seems to work - in the sense of fixing the performance issue - but I'm not that familiar with Pandas' internals, so I'm not sure if this is a correct/acceptable approach:
diff --git a/pandas/core/arrays/arrow/array.py b/pandas/core/arrays/arrow/array.py
index 0b546bed1c..89952b8f96 100644
--- a/pandas/core/arrays/arrow/array.py
+++ b/pandas/core/arrays/arrow/array.py
@@ -2376,7 +2376,9 @@ class ArrowExtensionArray(
ids: npt.NDArray[np.intp],
**kwargs,
):
- if isinstance(self.dtype, StringDtype):
+ if isinstance(self.dtype, StringDtype) or (
+ self.dtype.type == str and self.dtype.storage == "pyarrow"
+ ):
if how in [
"prod",
"mean",
diff --git a/pandas/core/arrays/base.py b/pandas/core/arrays/base.py
index 33745438e2..f4824255d3 100644
--- a/pandas/core/arrays/base.py
+++ b/pandas/core/arrays/base.py
@@ -2608,7 +2608,9 @@ class ExtensionArray:
op = WrappedCythonOp(how=how, kind=kind, has_dropped_na=has_dropped_na)
# GH#43682
- if isinstance(self.dtype, StringDtype):
+ if isinstance(self.dtype, StringDtype) or (
+ self.dtype.type == str and self.dtype.storage == "pyarrow"
+ ):
# StringArray
if op.how in [
"prod",
@@ -2648,7 +2650,9 @@ class ExtensionArray:
# through cython_operation
return res_values
- if isinstance(self.dtype, StringDtype):
+ if isinstance(self.dtype, StringDtype) or (
+ self.dtype.type == str and self.dtype.storage == "pyarrow"
+ ):
dtype = self.dtype
string_array_cls = dtype.construct_array_type()
return string_array_cls._from_sequence(res_values, dtype=dtype)