Pandas version checks
-
[x] I have checked that this issue has not already been reported.
-
[x] I have confirmed this bug exists on the latest version of pandas.
-
[x] I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
import pandas as pd
file_path = "\\path\\to\\outpattern_user_cost.sas7bdat" #Failure.
#file_path = "\\path\\to\\outpattern_user_cost_fixed.sas7bdat" #Success!
df = pd.read_sas(filepath_or_buffer=file_path, encoding="infer")
print(df)
Issue Description
With the latest (2.2.3) release of Pandas my team noticed when calling read_sas() on a particular '.sas7bdat' file, the read fails with an IndexError: list index out of range in _process_columnname_subheader() when processing the table's metadata.
The files in question can be found in: sas_data_files.zip. The archive contains 2 files: outpattern_user_cost.sas7bdat (the original data file causing the IndexError) and outpattern_user_cost_fixed.sas7bdat (the same table after being read into a new table in SAS and exported [see below], does not cause the error).
It produces the following trace result:
Traceback
Traceback (most recent call last):
File "C:\Users\XXXXXXX\Desktop\examples\my_tests\pandas_sas_issue.py", line 11, in <module>
df = pd.read_sas(filepath_or_buffer=file_path, encoding="infer")
File "C:\Users\XXXXXXX\Desktop\processorenv\lib\site-packages\pandas\io\sas\sasreader.py", line 164, in read_sas
reader = SAS7BDATReader(
File "C:\Users\XXXXXXX\Desktop\processorenv\lib\site-packages\pandas\io\sas\sas7bdat.py", line 228, in __init__
self._parse_metadata()
File "C:\Users\XXXXXXX\Desktop\processorenv\lib\site-packages\pandas\io\sas\sas7bdat.py", line 384, in _parse_metadata
done = self._process_page_meta()
File "C:\Users\XXXXXXX\Desktop\processorenv\lib\site-packages\pandas\io\sas\sas7bdat.py", line 390, in _process_page_meta
self._process_page_metadata()
File "C:\Users\XXXXXXX\Desktop\processorenv\lib\site-packages\pandas\io\sas\sas7bdat.py", line 453, in _process_page_metadata
subheader_processor(subheader_offset, subheader_length)
File "C:\Users\XXXXXXX\Desktop\processorenv\lib\site-packages\pandas\io\sas\sas7bdat.py", line 573, in _process_columnname_subheader
name_raw = self.column_names_raw[idx]
IndexError: list index out of range
However, in SAS, if the SAS data is saved to a new table, with no changes made to it:
data outpattern_user_cost_fixed;
set outpattern_user_cost;
run;
and then the new table is exported as outpattern_user_cost_fixed.sas7bdat, this new file is now read in by read_sas() correctly.
We use SAS to output the metadata of these test files via:
proc contents data="C:\Users\XXXXXX\Desktop\test\gconfid\pandas-ticket\outpattern_user_cost.sas7bdat";
title 'Not Fixed';
run;
proc contents data="C:\Users\XXXXXX\Desktop\test\gconfid\pandas-ticket\outpattern_user_cost_fixed.sas7bdat";
title 'Fixed';
run;
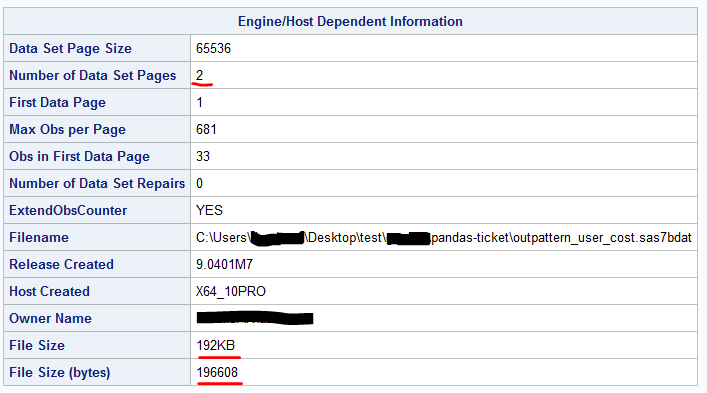
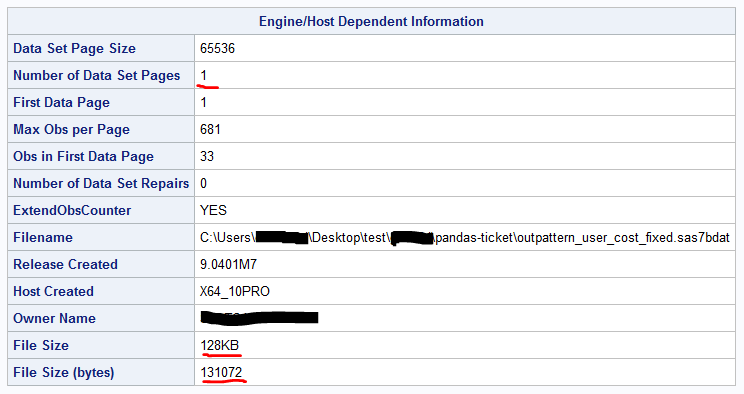
As shown above, the only difference reported is that the "Number of Data Set Pages" for the original erroneous table (outpattern_user_cost.sas7bdat) is 2 (vs 1 for outpattern_user_cost_fixed.sas7bdat) and the filesize is larger. All other reported metadata, including variable names, types and lengths, are the same.
Expected Behavior
The outpattern_user_cost.sas7bdat dataset should be loaded without error.
Installed Versions
Comment From: snitish
@andrdom I did some digging around and found that he problematic file has an extra 'amd' page that has "amendment" information that pandas currently does not handle. From https://cran.r-project.org/web/packages/sas7bdat/vignettes/sas7bdat.pdf :
In some test data files, there is a fourth page type, denoted ’amd’ which
appears to encode additional meta information. This page usually occurs last, and appears to contain amended
meta information.
Comment From: andrdom
@snitish Thank you very much for the investigation, we will look into workarounds for now.